Using a MapReduce Architecture to make a posting list
- Goals:
- To teach you how to make a posting list with a distributed MapReduce architecture on a BIG cluster.
- Groups: This can be done in groups of 1, 2 or 3.
- Reusing code: This assignment will probably build on your CharCount code. You are welcome to use Hadoop examples as the basis for this project. Use code found over the Internet at your own peril -- it may not do exactly what the assignment requests. If you do end up using code you find on the Internet, you must disclose the origin of the code. Concealing the origin of a piece of code is plagiarism.
- Discussion: Use the Message Board for general questions whose answers can benefit you and everyone.
- Write a program to be executed by Hadoop:
- Input:
- on the distributed file system there will be files like /user/common/small_input.txt and /user/common/large_input.txt
- The format of the file will be <doc_id>:<word>:<word_count> One entry per line. Multiple entries with the same (doc_id,word) pair may be present. They should be summed in your deliverable.
- Output:
- A posting list with an alphabetized list of words found in your corpus, the documents in which they occur and their frequency in each document. Alphabetize according to native Java sorting functions.
- Input:
- One way to do this (there are
multiple ways to do this, perhaps some that are
more efficient):
- Create a MapReduce program
- Run it on Hadoop
- Transfer the output to your local filesystem
- Delete the output from the distributed filesystem
- Write a program to read in the output and answer the questions
- Guides
I didn't follow my own advice when walking though this assignment and tried to do too much at once. So I backed off and took it step by step and iterated with incremental improvements to get the whole job done. Here's how I walked through it:
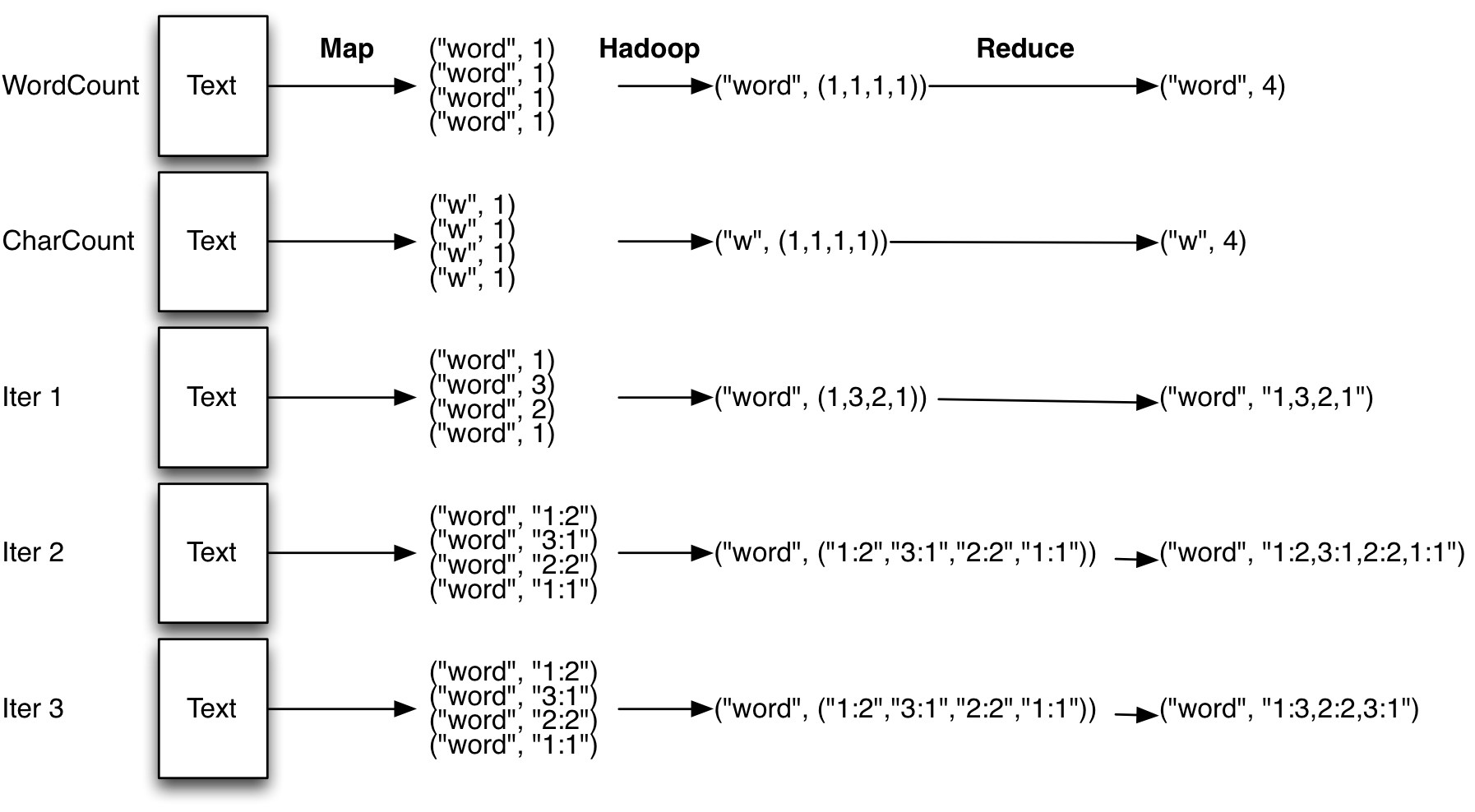
-
I modified the character counting assignment: I made the Map phase output a (key,value) pair that were of type Text and IntWritable. I tokenized the input as before and then did a second tokenizing step to subsplit the token around colons. The Text that I output as the key was the word. the IntWritable that I output was the Document Id.
The Reducer stage iterated through the list of Document Ids and constructed a string which was a list of all of them. Then the Reducer output a (key,value) pair of type (Text,Text). The key was the word and the value was a list of all the documents in String form.
In addition to the changes in my Mapper and Reducer, I explicitly set the MapOutputKeyClass and the MapOutputValueClass in my main function.
-
The next iteration that I did was to change the output of my Map from (Text,IntWritable) to (Text,MyPair). MyPair is a class that I made that encapsulated both the doc id and the term frequency. You can write your own class following the instructions here if you wish.
If you don't want to write your own class, then you need to encapsulate the doc id and term frequency in a string (or something else) and output it as a Text type. There are other ways to do it as well. The built-in types that you can use are shown here.
Whether your make your own type or use a built-in type, it has to implement the WritableComparable interface so that Hadoop can properly move your data around. The built-in hadoop types like "Text" do, but the standard Java types like "HashMap" do not.
In the process of making this change, I fixed the cluster so that it is now showing the status of your application on the website here as it is being run on many different machines.
The output is also now split across many different files. To combine them into one file quickly you can do the following commands. First move the files out of the dfs into the openlab disk space.
bin/hdfs dfs -copyToLocal /user/djp3/output01 /extra/ugrad_space/djp3Then merge all the files that start with "part*" into one large file. The "-m" tells sort that the files are already individually sorted. The "LC_ALL=C" tells the os to sort according to byte order
LC_ALL=C sort -m part* > big_file.txt -
The next step that I did was to process the documents in the reduce step so that repeats were merged and so that the documents lists were sorted.
-
The last thing that I did was to write a separate Java program that read in the "big file" and built a data structure from which I could answer the questions below.
It was helpful to know about TreeMaps, and ArrayLists. Also the function "Collections.sort(List)" will sort a list in forward order and "Collections.sort(List,Collections.reverseOrder())" will sort a list in reverse order. You don't necessarily have to use thost data structures though. There are more than one way to get the answers.
-
Finally, there is a test input in the dfs /user/common/very_small and a sample output that I got from that is here.
-
- Submitting your assignment
- We are going to use checkmate.ics.uci.edu to submit this assignment.
- Create a .txt document that answers the following questions:
- In the small input:
- How many documents are there?
- How many distinct terms are there?
- What are the 10 words with highest document frequency
- What are the 10 words with lowest document frequency
- What is the document frequency of the following words: zuzuf, fixed, rabbit, musicians,fences
- Evaluation:
- Correctness: Did you get the right answer?
- Due date: 03/04 11:59pm
- This is an assigment grade