The following problem comes up when Gene 4.2 creates reports in certain output formats. Some report types want the text they create to be centered. Some formats are only capable of handling character output; they do not have any way of specifying centering. To center text in these formats, we need to indent it ourselves by using an appropriate number of space characters.
The complication is that the Macintosh character set contains two kinds of space character: the usual space, and option-space (also known as non-breaking space). For typical fonts, these two spaces are different widths. We can take advantage of this fact by using a combination of both kinds of spaces, to get a total amount of indentation that centers the text more accurately than we would achieve by using only one kind of space.
So, the question becomes, given three numbers
a (the width of a normal space),find two more numbers
b (the width of an option-space), and
c (the amount we want to indent),
x (the number of normal spaces to use), andso that ax+by is as close as possible to c. This is an instance of diophantine approximation (a field studying how to find integer approximations to various formulas).
y (the number of option-spaces to use),
A slight further optimization can be made here: if it's possible to err by equal amounts on both the high and low side of c, we want the answer to be consistently on one side, say the low one. Another way of thinking of this is that we get an even better approximation to c - 1/2 than we do to c itself. This is especially helpful for the centering application since centering involves dividing a certain amount of space by two.
We might also have a secondary goal of minimizing the number of characters (x+y) but we don't worry about that here.
How can we solve this efficiently?
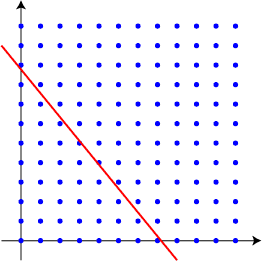
The following picture depicts an example we will use in the rest of this page, in which a=11, b=9, and c=79. In terms of our original problem, the width of an option-space is 11 pixels, the width of a space is 9 pixels, and the total width we wish to indent is 79 pixels. Each blue dot in the picture represents the combination of x option-spaces and y spaces. The red line represents the ideal width of 79 pixels. What we want to do is to find a blue dot that's as close as possible to the red line.
For this example, there are exact integer solutions to the equation ax+by=c, but these solutions all have one of x and y negative, which makes no sense for our application. We require both numbers to be positive or zero; with this constraint, the best close approximate solution is x=3, y=5, ax+by=78. In other words, 3 option-spaces and 5 spaces give a 78-pixel indentation, close to our desired indentation of 79 pixels.
If the line ax+by=c contains an integer point, that's our solution; otherwise we'd like to find an integer point (x,y) as close to the line as possible. Depending on whether the point is below or above the line, (x,y) can be described by certain inequalities. If (x,y) is below the line, it satisfies the three inequalities
The general problem of finding a point satisfying certain linear inequalities, and maximizing or minimizing a linear function, is known as linear programming. If the variables are allowed to be real numbers, linear programs can be solved in polynomial time (in the number of variables and inequalities, and in the number of bits needed to store the various numbers defining the problem) using complicated methods such as Karmarkar's algorithm. With only few variables (here, just two) they can be solved even more efficiently using algorithms from computational geometry.
Here, however, we have an additional constraint that x and y be integers. This makes a different type of problem, known as integer linear programming. If there are many variables, integer linear programming is very hard (NP-complete) but here there are only two variables, so we can solve our problem reasonably efficiently.
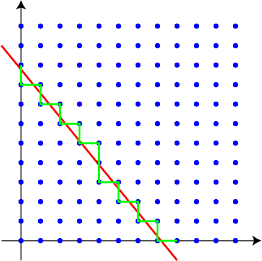
In more detail, we start our path with the candidate solution x=0, y=c/b+1. Then whenever the current point has ax+by >= c, we decrease y, and whenever ax+by <= c, we increase x, until we reach the other end of the path, y=0, x=c/a+1. At each step we compare the current point against the best previous solution.
This takes time O(c/a + c/b), the number of points on the path of candidate solutions. Although not polynomial (this time bound is exponential in the number of bits needed to represent the input) this may be ok for our centering application, since we need to spend a similar amount of time actually outputting the spaces.
We can assume without loss of generality that a>b (if not, just switch the two coordinates). The idea behind our efficient algorithm is simply to approximate the line ax + by = c by one of integer slope, y = r - qx. To make this line have similar slope to the original one, we let q=floor(a/b), and to make this line stay entirely below the original one, we let r=floor(qc/a).
We use this line to divide the possible integer solutions to our problem into two sets, a triangle near the origin in which y <= r - qx, and a wedge bounded by the y axis and by the line y >= r - qx + 1.
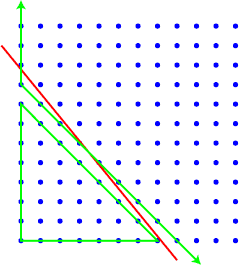
Within the lower triangle, the best approximation to c is always found at the lower right corner. In the problem shown in the picture, the lower right corner point is on the x axis, but for some other problems it might be slightly above the axis. More technically the solution for this case is the point with x = floor(c/a) and y = r - qx.
Within the upper wedge, we can ignore the constraint y >= 0 (the optimal solution ignoring this constraint is the same as if the constraint were there). If we perform a coordinate transformation y = y + qx - r - 1 this wedge turns back into the quadrant x,y >= 0! In other words we can solve the upper wedge problem recursively as another instance of the same type of problem we started with. As a base case to the recursion, whenever the upper wedge becomes completely above the line ax + by = c we can simply return the origin as our best approximation.
At each step, the coordinate transformation we use replaces a with a - bq, so the instances we solve get smaller and smaller. In fact, the changes made to a and b are exactly those made by Euclid's algorithm for computing gcd(a,b), which is known to terminate after O(log a) steps. So the same bound applies to our algorithm. Note in particular that the runtime doesn't depend on c, the number we're trying to approximate.
The results? A bit of a wash. Without optimization, the efficient algorithm was actually 50% slower than the brute force method on the numbers I tried. But with compiler optimizations turned on (in particular function inlining), the efficient algorithm became more than twice as fast as the (similarly optimized) brute force algorithm. The moral seems to be that optimizing compilers are more critical for recursive algorithms than for iterative ones.
My choice would be to go with the efficient algorithm. The speed differences are small enough not to matter (either algorithm will only use a small fraction of the total report output time) but the efficient algorithm has greater flexibility to cover cases I haven't yet anticipated, or other applications of the same problem.