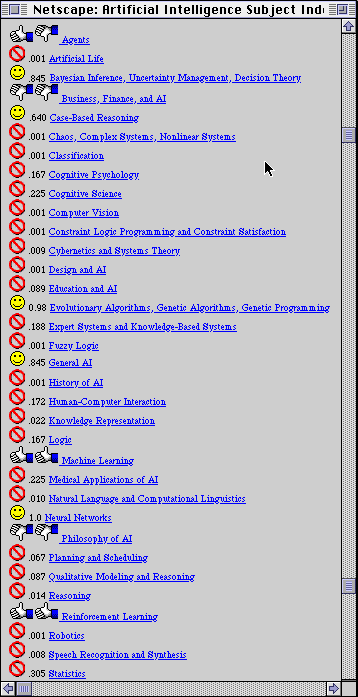
Syskill & Webert: Identifying interesting web sites
Michael Pazzani, Jack Muramatsu & Daniel Billsus
Department of Information and Computer Science
University of California, Irvine
Irvine, CA 92717
pazzani@ics.uci.edu
phone: (714) 824-5888
fax (714) 824-4056
http://www.ics.uci.edu/~pazzani/
Abstract
We describe Syskill & Webert, a software agent that learns to rate pages on the World Wide Web (WWW), deciding what pages might interest a user. The user rates explored pages on a three point scale, and Syskill & Webert learns a user profile by analyzing the information on each page. The user profile can be used in two ways. First, it can be used to suggest which links a user would be interested in exploring. Second, it can be used to construct a LYCOS query to find pages that would interest a user. We compare six different algorithms from machine learning and information retrieval on this task. We find that the naive Bayesian classifier offers several advantages over other learning algorithms on this task. Furthermore, we find that an initial portion of a web page is sufficient for making predictions on its interestingness substantially reducing the amount of network transmission required to make predictions.
1 Introduction
There is a vast amount of information on the World Wide Web (WWW) and more is becoming available daily. How can a user locate information that might be useful to that user? In this paper, we discuss Syskill & Webert, a software agent that learns a profile of a user's interest, and uses this profile to identify interesting web pages in two ways. First, by having the user rate some of the links from a manually collected "index page" Syskill & Webert can suggest which other links might interest the user. Syskill & Webert can annotate any HTML page with information on whether the user would be interested in visiting each page linked from that page. Second, Syskill & Webert can construct a LYCOS (Maudlin & Leavitt, 1994) query and retrieve pages that might match a user's interest, and then annotate this result of the LYCOS search. Figure 1 shows a Web page (http://ai.iit.nrc.ca/subjects/ai_subjects.html) that has been annotated by Syskill and Webert. This web page is a subject listing of AI topics that serves as an example of one index page. In this case, the user has indicated strong interest in "Machine Learning" and "Reinforcement Learning" (indicated by two thumbs up), a mild interest in "Agents" (indicated by one thumb up and one thumb down) and no interest in "Business, Finance and AI" and "Philosophy of AI' (indicated by two thumbs down). The other annotations are the predictions made by Syskill & Webert about whether the user would be interested in each unexplored page. A smiley face indicates that the user hasn't visited the page and Syskill & Webert recommends the page to the user. For this topic, these pages are "Neural Networks," "Evolutionary Algorithms," "Bayesian Inference," "General AI," and "Case-Based Reasoning." The international symbol for "no" is used to indicate a page hasn't been visited and the learned user profile indicates the page should be avoided. Following any prediction is a number between 0 and 1 indicating the probability the user would like the page.
Figure 1. An example of a page annotated by Syskill & Webert.
In this paper, we first describe how the Syskill & Webert interface is used and the functionality that it provides. Next, we describe the underlying technology for learning a user profile and how we addressed the issues involved in applying machine learning algorithms to classify HTML texts rather than classified attribute-value vectors. We describe experiments that compare the accuracy of several algorithms at learning user profiles. Finally, we relate Syskill & Webert to other agents for learning on the Web.
2 Syskill & Webert
Syskill & Webert learns a separate profile for each topic of each user. We decided to learn a profile for user topics rather than users for two reasons. First, we believe that many users have multiple interests and it will be possible to learn a more accurate profile for each topic separately since the factors that make one topic interesting are unlikely to make another interesting. Second, associated with each topic is a URL that we call an index page. The index page is a manually constructed page that typically contains a hundred or more links to other information providers. For example, the Web page at http://golgi.harvard.edu/biopages/all.html contains links to over 400 sites on the topic of Biosciences. Syskill & Webert allows a user to explore the Web using the index page as a starting point. In one mode of using Syskill & Webert, it learns a profile from the user's ratings of pages and uses this profile to suggest other pages accessible from the index page. To collect ratings, the HTML source of users' pages is intercepted, and an additional functionality is added to each page (see Figure 2). This functionality allows the user to rate a page as either hot (two thumbs up), lukewarm (one thumb up and one thumb down), or cold (two thumbs down). The user can return to the index page or switch topics. Furthermore, the user can instruct Syskill & Webert to learn a user-profile for the current topic, make suggestions or consult LYCOS to search the Web.
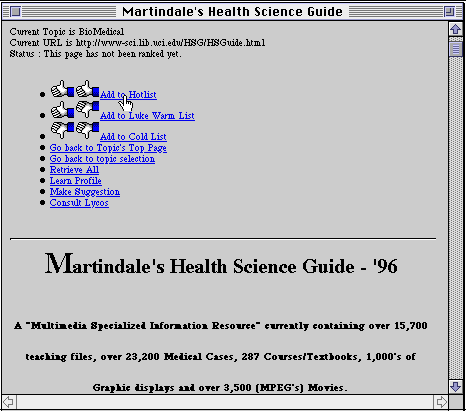
Figure 2. Syskill & Webert interface for rating pages.
When a user rates a page, the HTML source of the page is copied to a local file[1] and a summary of the rating is made. The summary contains the classification (hot, cold, or lukewarm), the URL and local file, the date the file was copied (to allow for the bookkeeping that would occur when a file changes), and the page's title (to allow for the production of a summary of the ratings).
Syskill & Webert adds functionality[2] to the page (see Figure 2) for learning a user profile, using this user profile to suggest which links to explore from the index page, and forming LYCOS queries. The user profile is learned by analyzing all of the previous classifications of pages by the user on this topic. If a profile exists, a new profile is created by reanalyzing all previous pages together with any newly classified pages.[3]
Once the user profile has been learned, it can be used to determine whether the user would be interested in another page. However, this decision is made by analyzing the HTML source of a page, and it requires the page to be retrieved first. To get around network delays, we allow the user to prefetch all pages accessible from the index page and store them locally. Once this has been done, Syskill & Webert can learn a new profile and make suggestions about pages to visit quickly. Section 5 discusses one means of avoiding a significant amount of network transmission overhead. Once the HTML has been analyzed, Syskill & Webert annotates each link on the page with an icon indicating the user's rating or its prediction of the user's rating together with the estimated probability that a user would like the page. Following any prediction is a number between 0 and 1 indicating the probability the user would like the page. The default version of Syskill & Webert uses a simple Bayesian classifier (Duda & Hart, 1973) to determine this probability. Note that these ratings and predictions are specific to one user and do not reflect on how other users might rate the pages.
As described above, Syskill & Webert is limited to making suggestions about which link to follow from a single page. This is useful if someone has collected a nearly comprehensive set of links about a topic. Syskill & Webert contains another feature that is useful in finding pages that might interest a user anywhere on the Web (provided the pages have been indexed by LYCOS). The user profile contains information on two types of words that occur in pages that have been rated. First, it contains words that occur in the most number of pages that have been rated "hot." For these words, we do not consider whether they have also occurred in pages that have other ratings. However, we ignore common English words and all HTML commands. The second set of words we use are those whose presence in an HTML file helps discriminate pages that are rated hot from other pages. As described in Section 3, we use mutual information to identify discriminating words. Since LYCOS cannot accept very long queries, we use the 7 most discriminating words that are found in a higher proportion of hot pages than all pages and the 7 most commonly occurring words as a query. Experimentally, we have found that longer queries occasionally exhaust the resources of LYCOS. The discriminating words are useful in distinguishing pages of a given topic but do not describe the topic. For example (see Figure 3) the discriminating words for one user about the Biosciences are "grants," "control," "WUSTL," "data," "genome," "CDC," and "infectious." The common words are useful for defining a topic. In the example in Figure 3 these are "university," "research," "pharmacy," "health," "journal," "biology," and "medical."

Figure 4. Syskill & Webert constructs a LYCOS query from a user profile.
A strength of LYCOS is that it indexes a large percentage of the Web and can quickly identify URLs whose pages contain certain keywords. However, it requires a user to filter the results. Syskill & Webert can be used to filter the results of LYCOS (provided the pages are fetched). For example, Figure 4 shows part of a LYCOS result that has been augmented by Syskill & Webert to contain a recommendation against visiting one page and for visiting others.
3. Learning a user profile.
Learning algorithms require a set of positive examples of some concepts (such as web pages one is interested in) and negative examples (such as web pages one is not interested in). In this paper, we learn a concept that distinguishes pages rated as hot by the user from other pages (combining the two classes lukewarm and cold, since few pages are rated lukewarm, and we are primarily interested in finding pages a user would consider hot). Most learning programs require that the examples be represented as a set of feature vectors. Therefore, we have constructed a method of converting the HTML source of a web page into a Boolean feature vector. Each feature has a Boolean value that indicates whether a particular "word" is present (at least once) or absent in a particular web page. For the purposes of this paper, a word is a sequence of letters, delimited by nonletters. For example, the URL <A HREF= http://golgi.harvard.edu/biopages/all.html> contains nine "words" a, href, http, golgi, harvard, edu, biopages, all, and html. All words are converted to upper case.
Not all words that appear in an HTML document are used as features. We use an information-based approach, similar to that used by an early version of the NewsWeeder program (Lang, 1995) to determine which words to use as features. Intuitively, one would like words that occur frequently in pages on the hotlist, but infrequently on pages on the coldlist (or vice versa). This is accomplished by finding the expected information gain (E(W,S)) (e.g., Quinlan, 1984) that the presence or absence of a word (W) gives toward the classification of elements of a set of pages (S):
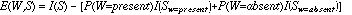
where
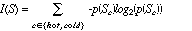
and P(W=present) is the probability that W is present on a page,
and
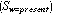 is
the set of pages that contain at least one occurrence of W and
is
the set of pages that contain at least one occurrence of W and
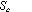 are the pages that belong to the class c.
are the pages that belong to the class c.
Using this approach, we find the set of k most informative words. In the experiment discussed in Section 4, we use the 128 most informative words. Section 6 discusses the impact of selecting other values for k. Table 1 shows some of the most informative words obtained from a collection of 140 HTML documents on independent rock bands.
Table 1. Some of the words used as features.
nirvana suite lo fi snailmail him
pop records rockin little singles recruited
july jams songwriting college rr his
following today write handling drums vocals
island tribute previous smashing haunting bass
favorite airplay noise cause fabulous becomes
Once the HTML source for a given topic has been converted to positive and negative examples represented as feature vectors, it's possible to run many learning algorithms on the data. We have investigated a variety of machine learning algorithms. In addition, we compare our results to TF-IDF, an weighting strategy from information retrieval adapted to perform the task of classification.
3.1 Bayesian classifier
The Bayesian classifier (Duda & Hart, 1973) is a probabilistic method for classification. It can be used to determine the probability that an example j belongs to class Ci given values of attributes of the example:
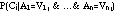
If the attribute values are independent, this probability is proportional to:
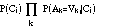
Both
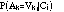 and
and
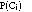 may be estimated from training data. To determine the most likely class of an
example, the probability of each class is computed. An example is assigned to
the class with the highest probability.
may be estimated from training data. To determine the most likely class of an
example, the probability of each class is computed. An example is assigned to
the class with the highest probability.
3.2 Nearest Neighbor
The nearest neighbor algorithm operates by storing all examples in the training set. To classify an unseen instance, it assigns it to the class of the most similar example. Since all of the features we use are binary features, the most similar example is the one that has the most feature values in common with a test example.
3.3 PEBLS
PEBLS (Cost & Salzberg, 1993) is a nearest neighbor algorithm that
makes use of a modification of the value difference metric, MVDM, (Stanfill
& Waltz, 1986) for computing the distance between two examples. This
distance between two examples is the sum of the value differences of all
attributes of the examples. The value difference between two values
 and
and
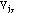 of attribute Aj is given by:
of attribute Aj is given by:
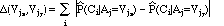
3.4 Decision Trees
Decision tree learners such as ID3 build a decision tree by recursively partitioning examples into subgroups until those subgroups contain examples of a single class. A partition is formed by a test on some attribute (e.g., is the feature database equal to 0). ID3 selects the test that provides the highest gain in information content.
3.5 TF-IDF
TF-IDF is one of the most successful and well-tested techniques in Information Retrieval (IR). A document is represented as a vector of weighted terms. The computation of the weights reflects empirical observations regarding text. Terms that appear frequently in one document (TF = term-frequency), but rarely on the outside (IDF = inverse-document-frequency), are more likely to be relevant to the topic of the document. Therefore, the TF-IDF weight of a term in one document is the product of its term-frequency (TF) and the inverse of its document frequency (IDF). In addition, to prevent longer documents from having a better chance of retrieval, the weighted term vectors are normalized to unit length.
In Syskill & Webert, we use the average of the TF-IDF vectors of all examples of one class in order to get a prototype-vector for the class (Lang, 1995). To determine the most likely class of an example we convert it to a TF-IDF vector and then apply the cosine similarity measure to the example vector and each class prototype. An example is assigned to the class that has the smallest angle between the TF-IDF vector of the example and the class prototype.
3.6 Neural Nets
We used two approaches to learning with neural nets. In the perceptron approach, there are no hidden units and the single output unit is trained with the delta rule (Widrow & Hoff, 1960). The perceptron is limited to learning linearly separable functions (Minsky & Papert, 1969). We also use multi-layer networks trained with error backpropagation (Rummelhart, Hinton & Williams, 1986). We used 12 hidden units in our experiments.
4 Experimental Evaluation
To determine whether it is possible to learn user preferences accurately, we have had four users use the Syskill & Webert interface to rate pages. A total of six different user profiles were collected (since one user rated pages on three different topics). The topics are summarized in Table 2 together with the total number of pages that have been rated by the user. Two users rated the pages on independent recording artists. One (A) listened to an excerpt of songs, and indicated whether the song was liked. Of course, the machine learning algorithms only analyze at the HTML source describing the bands and do not analyze associated sounds or pictures. Another user (B) read about the bands (due to the lack of sound output on the computer) and indicated whether he'd be interested in the band.
Table 2. Topics used in our experiments.
User Topic URL of topic's index page Pages
A Biomedical http://golgi.harvard.edu/biopages/medicine.html 127
A Lycos not applicable 54
A Bands http://www.iuma.com/IUMA-2.0/olas/location/USA.html4 57
(listening)
B Bands (reading) http://www.iuma.com/IUMA-2.0/olas/location/USA.html 154
C Movies http://rte66.com/Movies/blurb.html 48
D Protein http://golgi.harvard.edu/sequences.html 26
Syskill & Webert is intended to be used to find unseen pages the user would like. In order to evaluate the effectiveness of the learning algorithms, it is necessary to run experiments to see if Syskill & Webert's prediction agrees with the users preferences. Therefore we use a subset of the rated pages for training the algorithm and evaluate the effectiveness on the remaining rated pages. For an individual trial of an experiment, we randomly selected k pages to use as a training set, and reserved the remainder of the data as a test set. From the training set, we found the 128 most informative features, and then recoded the training set as feature vectors to be used by the learning algorithm. We tried six learning algorithms on each training set. The learning algorithm created a representation for the user preferences. Next, the test data was converted to feature vectors using the features found informative on the training set. Finally, the learned user preferences were used to determine whether pages in the test set would interest the user. We also tested TF-IDF using a similar scheme, except that TF-IDF operated directly on all of the words in HTML pages and did not require converting the pages to a set of 128 informative features[5]. For each trial, we recorded the accuracy of the learned preferences (i.e., the percent of test examples for which the learned preferences agreed with the user's interest). We ran 24 paired trials of each algorithm. Figures 5 and 6 show the average accuracy of each algorithm as a function of the number of training examples.
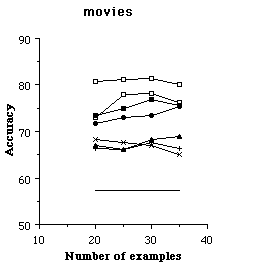
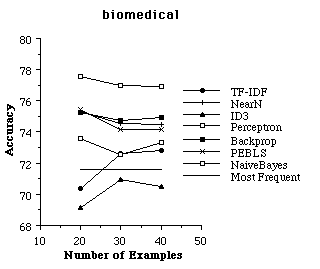
Figure 5. The average accuracy of each learning algorithm at predicting a user's preferences.
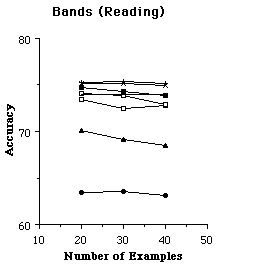
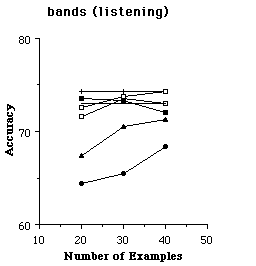
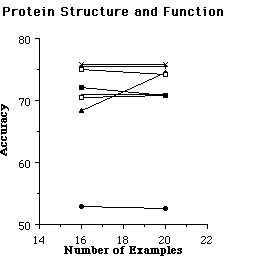
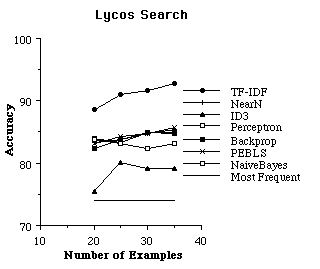
Figure 6. The average accuracy of each learning algorithm at predicting a user's preferences.
The results are promising in that on most of the problems the predictions are substantially better than simply guessing that the user would not be interested in a page (which is the most frequent prediction on all topics). However, no one algorithm is clearly superior on this set. To get a more detailed idea of which algorithms perform well, we analyzed the data to find the algorithm(s) that were most accurate with 20 training examples in each domain and the algorithm(s) that were least accurate. In each case, we used a paired, two tailed t-test to find other algorithms that were not significantly different from the best and the worst. On the biomedical domain, the naive Bayesian classifier was most accurate and ID3 was least. On the LYCOS search domain, TF-IDF was most accurate and ID3 was least. On the bands (listening) problem, nearest neighbor, PEBLS and backpropagation were most accurate and TF-IDF was least. On the bands (reading) problem nearest neighbor, PEBLS , backpropagation and were most accurate and TF-IDF was least. On the movies domain the naive Bayesian classifier was most accurate and nearest neighbor, ID3 and PEBLS were least. On the protein problem, PEBLS, nearest neighbor, ID3 and the naive Bayesian classifier were most accurate and backprop and the perceptron were least accurate. In summary, it appears that ID3 is not particularly suited to this problem, as one might imagine since it learns simple necessary and sufficient descriptions about category membership. The TF-IDF algorithm does not appear to have an advantage over the machine learning algorithms. In one domain it is significantly better than others, but in several others it was significantly worse. Although one must be careful not to read too much into averaging accuracies across domains, the naive Bayesian classifier has the highest average accuracy with 20 training examples: 77.1 (standard deviation 4.4). In contrast, PEBLS is 75.2 (4.7), backprop is 75.0 (3.9), nearest neighbor is 75.0 (5.5), ID3 is 70.6 (3.6) and TF-IDF is 68.5 (12.0). These results do illustrate that ID3 is not suited to this task and that TF-IDF has a large amount of variation in its performance. We have also experimented with a more advanced decision tree learner C4.5 with similar results.
We have decided to use the naive Bayesian classifier as the default algorithm in Syskill & Webert for a variety of reasons. It is very fast for both learning and predicting. Its learning time is linear in the number of examples and its prediction time is independent of the number of examples. It is trivial to create an incremental version of the naive Bayesian classifier. It provides relatively fine-grained probability estimates that may be used to order the exploration of new pages in addition to rating them. For example, on the biomedical domain, we used a leave-one-out testing methodology to predict the probability that a user would be interested in a page. The ten pages with the highest probability were all correctly classified as interesting and the 10 pages with the lowest probability were all correctly classified as uninteresting. There were 21 pages whose probability of being interesting was above 0.9 and 19 of these were rated as interesting by the user. There were 64 pages whose probability of being interesting was below 0.1 and only 1 was rated as interesting by the user.
In the remainder of this paper, we'll concentrate our experimentation on the naive Bayesian classifier with 20 training examples. We choose a small number of examples since most users will want to get results after ranking such a small number of pages. We investigate two issues:
* Is it possible to get similar accuracy with less work by looking at an initial portion of the page during learning and prediction?
* Can better results be achieved by selecting more (or less) that 128 informative words to use as features?
4. 1 Processing an initial portion of the page.
As described so far, it is necessary to store the complete HTML source of every page rated by the user and to evaluate an unseen page it is necessary to retrieve the entire HTML to convert the page to a feature vector. Here, we investigate an alternate approach. Instead of analyzing the entire HTML to find informative words, only the words contained in the initial c characters are used during learning when creating a profile and only those words in the initial c characters are used to predict whether a user would like the page. Of course, we still select the 128 most informative words in the initial portions of the pages. Note that we look at an initial sequence of characters, rather than words, since the protocol for transmission of segments of the file is based on characters.
We ran an experiment with the naive Bayesian classifier on the six domains with 20 training examples where we varied the value of c. The values used were 256, 512, 1024, 2048, 3072, 4096 and infinity (i.e., using the entire document). The results of this experiment, averaged over 24 trials, are shown in Figure 7. We plot each domain separately and also plot an average over the six domains.
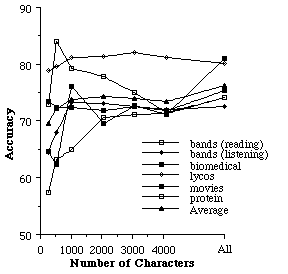
Figure 7. The effect of only analyzing the initial c characters of a file.
While in some domains (protein, bands and LYCOS), there is an advantage in not analyzing the entire document, on average there is a small decrease in accuracy. For example, only looking at the first 2048 characters yields an average accuracy of 74.2 while looking at all characters yields an accuracy of 76.3[6]. We have run experiments with all of the other learning algorithms and the general pattern is the same. On average, it is best to analyze the entire file, but the first 1024 -2048 characters is sufficient to achieve nearly the same accuracy. Usually, less than 512 characters results in a significant decrease in accuracy.
Although there is a small decrease in accuracy when looking at the initial segment of the file, in the next version of Syskill & Webert we will store and process only an initial segment to reduce the transmission overhead associated with fetching pages to rank. We also note that many users of Syskill & Webert rate a page as interesting without looking at the entire page and that many information retrieval systems index abstracts rather than the full text of a document.
Anecdotally, we have observed that some errors in Syskill & Webert are caused by analyzing too much of a page. For example, Syskill & Webert sometimes rates a page as interesting to a user when it is not. Sometimes this occurs because the page itself is uninteresting, while at the bottom of the page, there are pointers and short descriptions of related interesting sites[7]. This may explain why in some domains the accuracy of Syskill and Webert is improved when only analyzing an initial segment.
4. 2 Varying the number of informative features
The decision to use the 128 most informative words as features was made by looking at one initial domain (biomedical) when only 50 examples were collected. In this section, we explore the impact of selecting other numbers of features. Once again, we show results only for the naive Bayesian classifier with 20 examples. We experimented with selecting 16, 32, 64, 96, 128, 200, 256, and 400. of the most informative words to use as features. The results, averaged over 24 trials, are shown in Figure 8. We plot each domain separately and also plot an average over the six domains.
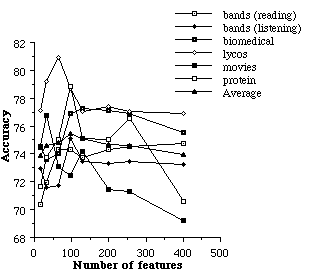
Figure 8. The effect of varying the number of informative features.
Figure 8 shows that having too few features can cause problems because important discriminating features are ignored. On the other hand, having too many features can also cause problems if many words that aren't very relevant are used as features. On average for the values we tested, 96 performed best. One might consider using information-gain to select a large group of informative features, and then using existing approaches for feature subset selection (e.g., Kittler, 1986; John, Kohavi, Pfleger, 1994) to select some of these features using a criteria other than informativeness. However, such algorithms increase the complexity of the Bayesian classifier, making it impractical to learn a profile interactively.
5. Related work
The methods developed for our learning agent are related to work in information retrieval and relevance feedback (e.g., Salton & Buckey, 1990; Croft & Harper, 1979). However, rather than learning to adapt user queries, we are developing a user profile that may be used for classification tasks such as filtering new information as it becomes available.
There are several other agents designed to perform tasks similar to ours. The WebWatcher (Armstrong, Freitag, Joachims, and Mitchell, 1995) system is designed to help a user retrieve information from Web sites. When given a description of a goal (such as retrieving a paper by a particular author), it suggests which links to follow to get from a starting location to a goal location. It learns by watching a user traverse the WWW and it helps the user when similar goals occur in the future. The WebWatcher and the work described here serve different goals. In particular, the user preference profile may be used to suggest new information sources related to ones the user is interested in.
Like our work, WebHound (Lashkari, 1995) is designed to suggest new Web pages that may interest a user. WebHound uses a collaborative approach to filtering. In this approach, a user submits a list of pages together with ratings of these pages. The agent finds other users with similar ratings and suggests unread pages that are liked by others with similar interests. One drawback of the collaborative filtering approach is that when new information becomes available, others must first read and rate this information before it may be recommended. In contrast, by learning a user profile, our approach can determine whether a user is likely to be interested in new information without relying on the opinions of other users. Furthermore, the profile learned also contains information that can be used to create queries of Web search engines such as LYCOS. However, one advantage of the collaborative approaches is that they do not require transmission and analysis of the HTML source of Web pages.
Balabanovic, Shoham, and Yun (1995) have developed an agent that searches links from existing pages for pages that might interest a user, using the TF-IDF weights as part of a user profile. In our experiments, TF-IDF did not perform as well at classification as algorithms designed for classification. Croft (1995, personal communications) has argued that the task of classifying pages differs from the tasks for which TF-IDF and relevance feedback were designed and that algorithms designed for classification may provide a more appropriate bias for the task.
5 Future Work
We are planning two types of enhancements to Syskill & Webert. First, we will investigate improvements to the underlying classification technology:
* Selecting an appropriate numbers of features. The performance of the learning algorithms is sensitive to the number of relevant features. We currently use a fixed number of features in a user profile. Rather than fixing the number, we plan on investigating having a threshold on the minimum informativeness of a feature. This may allow Syskill & Webert to adapt the number of features to the given problem and the number of examples without increasing the complexity of converting HTML to Boolean features.
* Explore the use of ordinal rather than Boolean features. Boolean features indicate whether a word is present or absent in a document. The ordinal features could indicate the number of times a word is present. Note that words include items such as "jpg" and "html" so these may be used to make decisions based on the number of pictures or links if they are informative. Like extensions to TF-IDF, these may be normalized to the length of the document.
* Using linguistic and hierarchical knowledge in the forming of features. Linguistic routines such as stemming (i.e., finding the root forms of words) may improve the accuracy of Syskill & Webert by having a smaller number of more informative features. Currently, words in the pages are used as features without any knowledge of the relationship between words such as "protein" and "proteins." Semantic knowledge such as the relationship between "pigs" and "swine" may also prove useful (e.g., Greffenstette, 1992). Similarly, knowing that "gif," "jpg" and "jpeg" are all extensions of graphic files would facilitate Syskill & Webert learning that a user has a preference for (or against) pages with in-line graphics.
* We will continue experimentation with various learning algorithms. Nearest neighbor algorithms perform about as well as Bayesian classifiers and have many of the same desirable properties. Nearest neighbor algorithms have a few potential advantages such as not making independence assumptions and having the ability to learn nonlinearly separable functions. One possibility that we are now implementing is using the TF-IDF weights as part of similarity metric for nearest neighbor. Syskill & Webert is implemented in a fashion that allows us to easily change the representation of user profiles.
Another set of enhancements to Syskill & Webert involve the redesign of the user interface to make it more interactive. We are currently reimplementing many of its capabilities as JAVA applets. One important advantage of this reimplementation is that the user profile can then be stored on the client rather than on the Syskill & Webert server. We are also exploring several other enhancements to the interface that will make it easier to use (and as a consequence allow us to collect more data for our experiments).
* Implementing routines that interactively annotate the index page with Syskill & Webert's predictions as the initial 2k of each link is processed. Currently, no annotations are added until all links have been retrieved and rated. We allow the user to prefetch links so that the rating can occur rapidly, but this does require patience the first time Syskill & Webert is used and disk space to store local copies of files.
* Currently, Syskill & Webert displays its raking as annotations on the current page that is displayed. We are planning on an option that will create a new page with Syskill & Webert's rankings sorted by the probability estimate that the page is hot.
* Currently, Syskill & Webert retrieves the original source of a page to determine its interestingness. Several of the Web search engines such as LYCOS store a summary of the page (e.g., See Figure 4). We are implementing routines to use this summary for rating the interestingness of a page. Combined with the previous option, this will reorder the suggestion made by LYCOS based on the user's profile. This may be particularly useful with "CyberSearch" which is a copy of much of the LYCOS database on CD-ROM eliminating the network connection overhead as well as the network transmission overhead.
* We plan on monitoring the topic page of each topic of a user, and notifying the user when a new link is added to the page that is rated as interesting.
7 Conclusions
We have introduced an agent that collects user evaluations of the interestingness of pages on the World Wide Web. We have shown that a user profile may be learned from this information and that this user profile can be used to determine what other pages might interest the user. Such pages can be found immediately accessible from a user-defined index page for a given topic or by using a Web search engine. Experiments on six topics with four users showed that the Bayesian classifier performs well at this classification task, both in terms of accuracy and efficiency. Other learning algorithms that make classifications based on combining evidence from a large number of features also performed well. ID3 was not very accurate perhaps since it tries to minimize the number of features it tests to make a classification and accurate classifications cannot be based on the presence or absence of a few words. Further experimentation showed that nearly the same classification accuracy could be achieved by looking only at the initial portion of a page, suggesting an enhancement to the interface that reduces storage space and network transmission overhead.
References
Armstrong, R. Freitag, D., Joachims, T., and Mitchell, T. (1995). WebWatcher: A learning apprentice for the World Wide Web.
Balabanovic, Shoham, and Yun (1995). An adaptive agent for automated web browsing, Journal of Visual Communication and Image Representation 6(4).
Cost, S. & Salzberg, S. (1993). A weighted nearest neighbor algorithm for learning with symbolic features Machine Learning, 10, 57-78.
Croft, W.B. & Harper, D. (1979). Using probabilistic models of document retrieval without relevance. Journal of Documentation, 35, 285-295.
Duda, R. & Hart, P. (1973). Pattern classification and scene analysis. New York: John Wiley & Sons.
John, G. Kohavi, R., & Pfleger, K. (1994). Irrelevant Features and the subset selection problem Proceedings of the Eleventh International Conference on Machine Learning. New Brunswick, NJ.
Kittler, J. (1986). Feature selection and extraction. In Young & Fu, (eds.), Handbook of pattern recognition and image processing. New York: Academic Press.
Kononenko, I. (1990). Comparison of inductive and naive Bayesian learning approaches to automatic knowledge acquisition. In B. Wielinga (Eds..), Current trends in knowledge acquisition. Amsterdam: IOS Press.
Lang, K. (1995). NewsWeeder: Learning to filter news. Proceedings of the Twelfth International Conference on Machine Learning. Lake Tahoe, CA.
Lashkari, Y. (1995). The WebHound Personalized Document Filtering System. http://rg.media.mit.edu/projects/webhound/
Maudlin, M & Leavitt, J. (1994). Web Agent Related Research at the Center for Machine Translation Proceedings of the ACM Special Interest Group on Networked Information Discovery and Retrieval
Minsky, M., & Papert, S. (1969). Perceptrons. Cambridge, MA: MIT Press.
Quinlan, J.R. (1986). Induction of decision trees. Machine Learning, 1, 81-106.
Rachlin, Kasif, Salzberg & Aha, (1994). Towards a better understanding of memory-based reasoning systems. Proceedings of the Eleventh International Conference on Machine Learning. New Brunswick, NJ.
Rumelhart, D., Hinton, G., & Williams, R. (1986). Learning internal representations by error propagation. In D. Rumelhart and J. McClelland (Eds.), Parallel Distributed Processing: Explorations in the Microstructure of Cognition. Volume 1: Foundations, (pp 318-362). Cambridge, MA: MIT Press.
Salton, G. & Buckley, C. (1990). Improving retrieval performance by relevance feedback. Journal of the American Society for Information Science, 41, 288-297.
Skalak, D. (1994) Prootype and feature selection by sampling and random mutation hill climbing algorithms. Proceedings of the Eleventh International Conference on Machine Learning. New Brunswick, NJ.
Stanfill, C. & Waltz, D. (1986). Towards memory-based reasoning. Communications of the ACM, 29, 1213-1228.
Widrow, G., & Hoff, M. (1960). Adaptive switching circuits. Institute of Radio Engineers, Western Electronic Show and Convention, Convention Record, Part 4.
 WebGlimpse |
|
| Search: The full archive | |