Why not everything can be statically allocated
We learned previously about objects that are statically allocated and stored on the run-time stack. There are advantages to statically allocating objects — most notably, they're deallocated automatically when they fall out of scope — but it turns out that not everything can be statically allocated, for at least a couple of reasons.
Sizes can be unpredictable
Previously, we saw that the C++ Standard Library provides a type called std::string, which encapsulates the idea of text, i.e., a sequence of characters. But let's stop for a moment to consider what std::string objects might actually look like in memory, based on our previous understanding of static allocation and the run-time stack. Consider this partial C++ function:
void foo()
{
std::string s = "Alex";
// ...
}
From our previous understanding of memory allocation, we would conclude that the variable s is a local variable of the function foo(), which we understand to mean that s has been statically allocated and will be stored on the run-time stack, and that it will be deallocated automatically — along with everything else in foo()'s activation record — when the function ends. And, in fact, this is technically true, but there's more to the story than meets the eye in this case.
One of the things that we learned about statically-allocated objects is that they must have a known size at compile time. For every function, the compiler must determine a precise layout for the function's activation record (i.e., how large the activation record will be, and where within that activation record each local variable, parameter, etc., will be stored).
This brings up an important question: What is the size of s? Looking at the foo() function above, you might conclude that the string consists of four characters of text, so that its size might be equivalent to four characters (e.g., if each character is one byte, s would be four bytes). But, unfortunately, it's not that simple: strings can change after they've been created! What if foo() continued like this?
void foo()
{
std::string s = "Alex";
// ...
s += " Thornton";
// ...
}
How big should s be now? You might conclude that the compiler could simply determine that, at most, s would have the characters Alex Thornton stored in it, so it could allocate 13 characters' worth of memory. But there are a couple of problems with that. First of all, s isn't always 13 characters long; before the use of +=, s is only four characters, though I suppose a compiler could work its way around that, in this particular case. Secondly, and more importantly, it's not always this simple! Consider the function bar() below.
void bar(int n)
{
std::string s;
for (int i = 0; i < n; i++)
{
s += '-';
}
// ...
}
How big should s be in bar()? The actual length of the text stored in s can't be determined precisely at compile time, because the loop appends n dashes to an initially-empty string. So unless the compiler allocates enough memory to store any possible number of dashes — on our architecture, an int variable might be as large as 2,147,483,647, so we're talking about 2 GB! — there simply isn't any way to do this correctly.
In other words, not every object has a size that can be determined at compile time. Some things have sizes determined by input to a function or by other external input to the program (e.g., user input, input sent via a network). If the size of an object can't be determined at compile time, it can't be allocated statically, and it can't be stored on the run-time stack. So we'll need to find another alternative.
Object lifetime
While it is quite often the case that an object created in a function will best be destroyed when that function ends, there are plenty of circumstances where this isn't the case. Some objects need to outlive the functions in which they're created.
For example, maybe we're talking about a function that's part of a server in a massively-multiplayer online game, which is called every time someone connects to the server and logs in. As a result, some information about that user is allocated and will need to be used in many places throughout the program for as long as the user is still connected, even though the function that handled the connection process has already finished. Only when the user disconnects, that information will then need to be deallocated.
In some cases like that, you could simply return the value from the initial function that creates it, then pass it as arguments to other functions as you work your way through a program's control flow. But this can be an expensive proposition — if the object is large, it might need to copied repeatedly! And what if you want to store the object in some kind of data structure — akin to a Python list or a Java ArrayList — that grows and shrinks over its lifetime? Now we're back to the same problem we had before: Data structures that grow and shrink over time have sizes that can't be determined at compile time, so their contents can't be statically allocated.
Dynamic allocation
We've seen previously that the words static and dynamic appear quite frequently when talking about programming languages, and that they quite often are used, broadly, to mean the same kind of thing. Things that are said to be static are often understood to be things that happen before a program runs (e.g., things that are determined by a compiler), while dynamic things are things that happen while a program runs.
If we're talking about memory allocation, the distinction is the same.
- Static allocation is done before a program runs. In the case of C++, that means the compiler determines the object's size and (relative) position in memory (e.g., if it's a local variable of a function, where in that function's activation record the object will be stored).
- Dynamic allocation is done while a program runs. As the program is executing, an object might need to be created on the fly, only to be destroyed at some other time. In the case of C++, dynamic allocation is done using the keywords new and delete, which, respectively, allocate and deallocate an object dynamically. (If you've written programs in Python or Java before, it should be noted that most allocation in these languages is actually dynamic, but that the deallocation is done automatically by a garbage collector. In C++, by contrast, both allocation and deallocation are the programmer's responsibility.)
If we consider how the run-time stack is managed, it becomes clear that dynamically-allocated objects wouldn't fit there very well. If a C++ program can allocate or deallocate an object dynamically at any time, perhaps in wildly different places in a program, possibly deallocating them in wildly different orders than they were allocated, then the run-time stack simply wouldn't be a good place to store them; the run-time stack is managed in a way that is completely dependent on the order in which functions are called and return.
So there must be another area of memory, one that is separate from the run-time stack, that's used to store objects like these, which have dynamic sizes and/or dynamic lifetimes. This area of memory is called the free store or the heap. In the heap, anything goes.
- Your program decides when memory will be allocated, how much of it will be allocated, and what types of objects will be stored there. That memory is allocated only when the program explicitly asks to do so.
- Your program decides when memory will be deallocated, making that memory available to be reused elsewhere. That deallocation happens only when the program explicitly asks to do so, and the memory is not available to any other part of the program until that deallocation has been done.
(The terms "free store" and "heap" are used somewhat interchangeably among C++ programmers, though the term "heap" is more common, so I'll stick with that term going forward. Note, also, that you may have taken a data structures course that discussed a data structure called a "heap" that is used to store objects in a kind of priority-based order; the naming collision here is a coincidence and the heap in a C++ program has nothing to do with that.)
The code generated by a C++ compiler organizes memory in a way that keeps the run-time stack separate from the heap (and, in turn, both of these are kept separate from the areas in memory that store the program's code and its global variables). Allocation and deallocation in one area has no effect on the other, so you can accurately think of these as simply being separate.
How dynamic allocation is used in std::strings
So, if there are two kinds of memory allocation, this suggests how a local variable s of type std::string might look when stored in memory. A string is a combination of two areas in memory:
- Fixed-size information that describes the string but does not include its text. Because the size of this information is fixed, it can be allocated at compile time.
- The sequence of characters stored in the string. Because this can grow and shrink over the lifetime of a string, and because it's not generally possible for a compiler to determine its size, it will need to be dynamically allocated.
That suggests an arrangement sort of like this one:
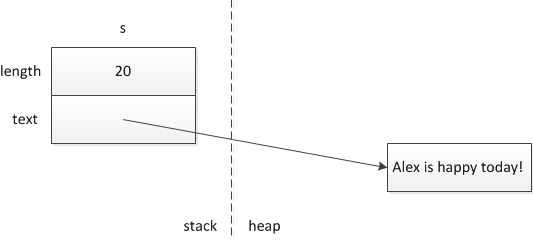
The length part of s above could simply be an unsigned int value that indicates how many characters of text are contained in s. For any given compiler, unsigned int values have a known size at compile time (four bytes on the ICS 45C VM), so this part could be allocated statically.
The text part of s is different. Given what we learned about references, you might conclude that text is a reference. But it turns out that it can't be. Because s can be modified during the course of its life — characters can be added, removed, etc. — a reference will be problematic, because references can't be pointed to new locations in memory once they're initialized, which will be necessary as the number of characters grows and shrinks. Remember that references solve a fairly narrow problem in C++: passing or returning a fixed location of a single object. That's not going to cut it here.
So it looks like we'll need a new tool to solve this problem; references must not be the only way in C++ to track the location of something else. We need something that can represent the location of an object (i.e., a memory address), but that can be re-pointed to new memory locations over the course of its life. That tool is called a pointer.
Pointers
A pointer in C++ is a very thinly-veiled abstraction for a memory location. A pointer is actually a combination of two things:
- A memory address, in a literal sense. As we've seen, every tiny block of memory — often, every single byte — generally has a numeric address, which you can think of as being like an index into a giant array. So if you want to keep track of the location of something in memory, you need only keep track of its address.
- A type. Every pointer knows what type of object it's pointing to.
In other words, a pointer won't just say "I'm pointing to memory location x." It'll say "I'm pointing to an integer stored at memory location x." Given a pointer of a particular type, you'll be limited in terms of how you can treat the object it points to; for example, if it's a pointer to an integer, you'll only be able to do to that object the things you can legally do to integers. As always, C++'s type system will verify that you're not violating these constraints: pointers to integers can only legally be pointed to integer objects, and the objects they point to can only be treated as integers.
Declaring a variable that stores a pointer to a particular type of object simply requires appending a * to the name of that object's type. For example, this is the declaration of a pointer variable x that is a pointer to an int object:
int* x;
(Note that the precise spacing here can be done in different ways, though I'll adopt the convention of writing the * next to the type, as opposed to writing it next to the variable's name, since it's conceptually part of x's type.)
As declarations begin to become more complex, it becomes important that we establish a good way to read and understand them. A good rule of thumb that works in many cases is to read them in a right-to-left manner. If we do that here, and if we take * to mean "pointer," then we would read the declaration above as "x is a pointer to an integer."
The & (address-of) operator
C++ references store memory addresses only implicitly. In other words, the variable is, for all intents and purposes, the same as the object the reference refers to. Behind the scenes, C++ is probably storing a memory address, but there is no name for it; whenever you use the name of the reference, you'll get the object that the reference refers to.
The value of a pointer is different. Pointers are memory addresses, both explicitly and implicitly. When you access the value of a pointer, you're accessing the memory address that it stores, not the object stored at that address. An int* is not interchangeable with an int; it's a pointer to an integer. The compiler takes this distinction quite seriously, and will carefully ensure that you're not interchanging these concepts in ways that don't make sense. For example, the following code will result in a compile-time error:
int i = 3;
int* p = i; // invalid conversion from int to int*
The second line will be disallowed because it is an attempt to store an int value into a variable whose type is int*. While you could argue that memory addresses are simply integers, allowing this would be much more error-prone than the alternative, so the compiler won't let you do it — at least not without playing some tricks, which we might see later in the course, but that you would only use in rare circumstances where you wanted fine-grained control over precisely what addresses you wanted to store in pointers; I've done that before, but maybe only a tiny handful of times.
However, pointers can be made to point to existing objects, but you need a bit of additional syntax to do it. There is an operator that you can use in an expression that asks for the address where an object is stored. It's often called the address-of operator, and is indicated by an &. When you prefix an object with an & in an expression — not in a type declaration, where & means something else (i.e., a reference type) — what you get back is a pointer to that object.
int i = 3;
int* p = &i;
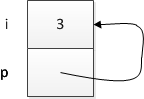
In the example above, p will now store the address where i is located, because the literal meaning of &i is "Give me a pointer that points to i." Because i has type int, it stands to reason that the pointer you would get back would be an int*, which is why it's legal to store the value of &i into p. Pictorially, we can now think of p as being sort of like an arrow that points to i — which is how I quite often draw it or visualize it in my mind — though, behind the scenes, the arrow is really just a number (i.e., the address in memory where i is).
You can also assign one pointer into another, which wouldn't require the use of the & operator. This makes a certain amount of sense, because pointers store addresses (constrained by a type), so assigning one pointer into another simply copies that address, the effect of which is that the target would now point to the same object as the source. For example:
int i = 3;
int* p = &i;
int* q = p;
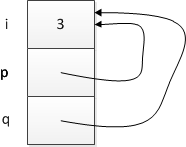
In this case, p will be a pointer that points to i, and then q will be made to point to the same place p does. So both pointers are now pointing to i.
I should mention, also, that you can have pointers to pointers, though this isn't something I find myself doing very often — but it's also not something I've never done. For example:
int i = 3;
int* p = &i;
int** q = &p;
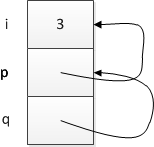
When we ask for &i, we get a pointer to i; since i is an int, that pointer's type is int*. When we then ask for &p, we get a pointer to p; since p is an int*, the pointer we get back has the type int** (i.e., read right-to-left as "a pointer to a pointer to an int"). So, in this case, the pointer q points to the pointer p, which, in turn, points to the integer i.
Dereferencing
Pointers wouldn't be much use if you couldn't use them to access the objects they point to. If a pointer's job is to keep track of where some object is, it stands to reason that you'd need to know where that object is because you plan to do something with it. When you want to access the object that a pointer points to, you use an operator called the dereference operator (so we often call this dereferencing a pointer), which is represented by *. When the * operator precedes a pointer in an expression, you're asking for the object that the pointer points to.
(Yes, the operator is called dereference, even though this has nothing to do with references. Historically, this isn't as crazy as it now sounds; references were added to C++ long after C had a dereference operator that operated on pointers. But, nowadays, it's an unfortunate collision of terms that can be confusing at first.)
In general, if you have an int* p:
- p is an expression that evaluates to the pointer itself (i.e., a memory address where you would find an int)
- *p is an expression that evaluates to the object that the pointer points to (i.e., an int)
It should be noted that *p is an lvalue, so it will be possible to both read from the integer that p points to, and also to change it.
As you might imagine, then, & (address-of) and * (dereference) are the inverse of one another.
int i = 3;
int* p = &i;
std::cout << i << std::endl;
*p = 4;
std::cout << i << std::endl;
The code above, then, would print 3 and then 4 to the standard output.
The interaction between pointers and references
Once you understand each of them, pointers and references interact in ways you might expect, though the notation takes some getting used to, particularly because & and * show up in a couple of different ways. The important thing to remember is that pointers and references aren't the same thing: References are implicit synonyms for objects, whereas pointers explicitly store the location of another object.
A few examples are illustrative here:
int* p = new int;
*p = 3;
int& q = *p;
q = 4;
std::cout << *p << std::endl;
int* r = &q;
*r = 5;
std::cout << *p << std::endl;
int*& s = p;
*s = 6;
std::cout << *p << std::endl;
At the conclusion of this code block, the relevant variables and objects might be arranged in memory like this. (The arrows with dashed lines denote references, the others denote pointers.)
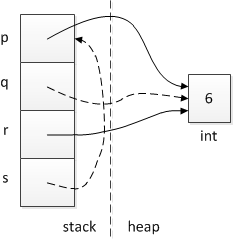
We can trace through this code a line at a time to understand what it means, so we can understand how we ended up with the diagram above.
- We first dynamically allocate an integer. The pointer p now points to it.
- We then assign the value 3 into the dynamically-allocated integer.
- Next, we define q, a reference to an integer. As we've seen, references have to be made to refer to an object of the appropriate type at the time they're created. A reference to an integer needs to refer to an integer. *p is an integer, the integer that p points to, so we can safely refer q to *p.
- We then assign the value 4 into the integer referred to by q. This is the same integer pointed to by p; its previous value was 3.
- Now we print *p, which is that same integer, so we see the output 4.
- Next, we define r, a pointer to an integer, and assign it to point to &q. This is a bit confusing, but, like many complex things in C++, we can understand it piecemeal. q is a reference to an integer, but any time we say q, we're talking about the integer; the fact that it's a reference is implicit. So &q is really a way of asking for the address of the integer that q refers to. That happens to be the same integer that p points to. So r is, ultimately, the same address as p; both pointers point to the same place.
- We then assign the value 5 into *r, the integer that r points to. That's the same integer that p points to, and the same integer that q refers to. Its value changes from 4 to 5.
- Printing the value of *p displays 5.
- Next, we define s. Reading its type declaration from right to left, we see that "s is a reference to a pointer to an integer." So, we'll need to initialize it to refer to an int*. p is an int*, so we can assign s to refer to p.
- We then assign the value 6 into *s. Fundamentally, s is a reference, so when we say s in this expression, we get the value s refers to. s refers to the pointer p. Since we dereferenced that pointer by saying *s, we're saying "Go to where that pointer points." That pointer points to our same dynamically-allocated integer, whose value is updated to 6.
- Finally, printing the value of *p displays 6.
One more small wrinkle you should be aware of: There are no pointers to references in C++. References are treated identically to the objects they refer to, so a pointer to reference would have no useful meaning; it would be no different from a pointer to the object that the reference referred to. For that reason, C++ simply disallows them.
nullptr
The job of a pointer is to track the location of another object, though there is a situation we've not yet considered. What if, instead, you want to track the absence of an object (i.e., you want a pointer that indicates that an object is missing)? This might sound strange at first blush, but it's actually a technique that has more practical use than you might think.
For example, you may have previously seen a data structure called a linked list, which consists of a sequence of values stored in separate objects called nodes. Each node stores one object in the list, and then keeps track of where the next node is. The first node tells you the location of the second, the second tells you the location of the third, and so on, and the list's structure arises from the way that they "link together." In C++, you would typically store a pointer in each node that points to the subsequent node. But in the last node, which has no node that follows it, what would you store? Every node will need to look the same, so there will need to be a pointer, even in the last one, but where will the pointer point? This problem (and lots of problems like it) calls for a pointer that points to no object at all.
In C++, we say that a pointer that points to no object is a null pointer. As far as the C++ standard is concerned, there are a few ways to say that. The "modern" way is to use the keyword nullptr, which always evaluates to a null pointer (and is compatible with a pointer of any type, but with no other types). So, for example, if you wanted a pointer p that pointed to nothing, you would initialize it like this:
int* p = nullptr;
Dereferencing a null pointer is considered undefined behavior, though it will most often result in a program crash; the reason is that you're asking for an object that isn't there. For example, if you do that on a program you run from the Linux shell in the ICS 45C VM, your program will generally crash and you'll see only the error message Segmentation fault, though this behavior can be different on other systems (e.g., on my Windows 10 machine, as of this writing, it will pop up the standard "This program has stopped working" crash dialog box instead).
So this block of code would compile and run, but would crash in the ICS 45C VM:
int* p = nullptr;
*p = 3; // CRASH!
Other ways to say "null"
The nullptr keyword is the notation that I'll use when I want to use the concept of "nullness" in a C++ program, but you should be aware that there are a couple of other ways to do it. Another way to do it — which I find to be more obtuse, but is technically legal — is to use the constant 0, which is also compatible with any pointer type.
int* p = 0;
You can't assign non-zero constant integers to a pointer, but you can assign zeroes. I don't typically like this style, because it can be confusing — I like things that look, at a glance, like what they are, and this is one more level of indirection in an already-complex language. But it is worth knowing that pointers can be thought of as being zero (null) or non-zero (not null), because you might see them used as boolean expressions, the same way that integers can be:
if (p)
{
// p is non-null
}
else
{
// p is null
}
This, too, is not a style I prefer; I would write it this way, because, again, it makes explicit a key detail that I might otherwise easily miss:
if (p != nullptr)
{
// p is non-null
}
else
{
// p is null
}
Lastly, the C++ Standard Library has long defined a macro called NULL (note the capitalization; that's important) that actually expands to 0, so is another way to set a pointer to null:
int* p = NULL;
While you'll probably see a fair amount of code online that does this, because nullptr is a fairly recent addition to C++, you should prefer nullptr, as it has the nice property of only being assignable to a pointer type, whereas NULL is literally 0, meaning this would also be legal, even though it makes no sense conceptually (though our C++ compiler on the ICS 45C VM will warn you about it):
int a = NULL;
The "new" and "delete" operators
Thus far, we've seen a lot of the notation used to create and interact with pointers, but it's still not at all clear why you would need them from a practical perspective. Pointers would be nearly useless if dynamic memory allocation wasn't supported, because their primary use is for accessing objects that have been allocated dynamically (i.e., on the heap). So, to more fully understand pointers, we need to know how to do dynamic allocation and deallocation.
Dynamically allocating an object
The operator new is used to dynamically allocate an object. Any type of object can be allocated this way, and the operand of new is the type of object you want. When you allocate, say, a new int, you've asked for your program to do three things, right then and there:
- Find a block of memory on the heap that's not already allocated, one that is big enough to store an int. (So, for example, on the ICS 45C VM, that would be four bytes.)
- Provided that a block of memory was found — and we'll talk another time about the consequences of running out of memory and how you deal with them, but we currently lack the techniques in C++ to do so — that block of memory is allocated, which means that it will be "cordoned off," in a sense, so that it can't be allocated anywhere else until after you explicitly deallocate it later.
- The location of that allocated memory on the heap is returned to you. Since we're talking about an address in memory, what you get back is a pointer, with the type of that pointer determined by the type of object that you asked for, so new int would give you back an int*.
So, in the following example, we dynamically allocate an integer and interact with it.
void foo()
{
int* p = new int;
*p = 3;
std::cout << p << std::endl;
std::cout << *p << std::endl;
(*p)++;
std::cout << *p << std::endl;
}
If you ran that code, what would happen is the following:
- An int would be dynamically allocated and p would be pointed to it. That int would be stored on the heap, while the pointer p, which is a local variable in the foo() function, would be stored on the run-time stack.
- The value 3 would be stored in the int that p points to.
- Printing p would show the actual memory address where p points, i.e., the address on the heap where the integer was allocated. That will work a little differently on different platforms, but on the ICS 45C VM, you would see it show up as 16 hexadecimal digits (since memory address are 64 bits), such as 0x000004F08E739B00.
- Printing *p would show the integer value stored at that address. Since we stored 3 just after we dynamically allocated the integer, we should see 3.
- Incrementing *p would cause the value of *p to be increased by 1. So the int that p points to will now have the value 4. (The reason for the parentheses around *p is to override operator precedence; otherwise, we'd be incrementing p and then dereferencing that, and that's a conversation for another day.)
- Printing *p again would display 4.
When this function ends, its statically-allocated local variables — namely, the pointer p — would be destroyed automatically. When pointers are destroyed, though, the objects they point to are not. This is by design, actually, because you might have more than one pointer pointing to the same object over the course of time, so it's up to you to manage the deallocation of dynamically-allocated objects.
Dynamically deallocating an object
In a programming language that offers the ability to explicitly allocate objects on a heap, and where objects on the heap have indeterminate lifetime, it is quite common for an automatic garbage collector to be provided. While more of the details are hidden behind the scenes than they are in C++, both Python and Java, for example, heap-allocate almost all of their objects very similarly to the way C++ does with its new operator. The main difference is that both Python and Java will periodically discover which objects are no longer in use and deallocate them automatically, so that this deallocation is not something you'll need to manage yourself.
An automatic garbage collector is part of a programming language's runtime system, which is to say that it is interwoven into your program and works alongside it. The presence of an automatic garbage collector has two positive effects:
- It makes it much more difficult (though still not impossible) to suffer from memory leaks. When you allocate memory dynamically, it is considered to be "in use" and can't be allocated again until it's been deallocated first. A memory leak is simply allocation without subsequent deallocation, meaning that a program (particularly a long-running program) gradually uses more and more memory until it suffers serious consequences such as a major slowdown or even a crash. Provided that you don't keep pointers/references to objects that you no longer need, running out of memory is not something you have to think about very much in a garbage-collected language, unless your program needs to actually use a lot of memory at a time.
- Garbage collectors are generally conservative about deleting objects, opting to do so only when they are provably inaccessible, so they make it impossible to have a dangling pointer or dangling reference, which is a pointer/reference to deallocated memory. If you can access an object, you know it's a "live" object.
Given this, an automatic garbage collector sounds like a wonderful thing to be able to depend on, and it certainly can be. But there's a big problem, from a performance perspective: Automatic garbage collection isn't free. Depending on the algorithm that's used, it might slow a program down, seemingly randomly introduce noticeably-long pauses into your program, and generally make it more difficult to predict how long individual functions might take to run. In some kinds of software, that's fine; in others (e.g., control software for robotics or a loop that renders frames in a 3D video game, which are subject to real-time constraints), it's impossible to accept.
For this reason — and consistent with C++'s basic design philosophy of not including features that impose a cost on those who choose not to use them — C++ does not include an automatic garbage collector. This isn't to say that "dead" objects can't be cleaned up, or even that there aren't really good tools that can automate some kinds of cleanup. But the reality is that deallocating dynamically-allocated objects when you're done with them is ultimately your responsibility as a C++ programmer. As soon as you use the new operator to allocate an object on the heap, you'll need to consider where and when that object needs to be deallocated with the delete operator.
You can think of the delete operator as being a kind of inverse of the new operator.
- The new operator allocates an object on the heap and returns a pointer to it.
- The delete operator takes that same pointer and deallocates the object that it points to.
As a somewhat nonsensical example that nevertheless demonstrates the concept, consider this C++ function.
void foo(int n)
{
for (int i = 0; i < n; i++)
{
int* p = new int;
// ...
}
}
This function runs n iterations of a loop, each of which dynamically allocates an int and then fails to deallocate it. The effect of calling this function is more insidious than it might appear at first glance. Every time you call this function, at least O(n) bytes (on the ICS 45C VM, at least four bytes per int) are allocated on the heap. When the function ends, its local variables and parameters (i, n, and p) — which are stored on the run-time stack — are destroyed automatically. But the dynamically-allocated integers remain on the heap, now unreachable since we have no pointer to any of them; those integers will remain allocated for as long as our program runs, or until the program finally crashes due to having run out of available memory.
By using the delete operator in the body of this loop, so that each of the integers is deallocated when we're done with it, we could call this function with n's value being as large as we want and never run out of memory.
void foo(int n)
{
for (int i = 0; i < n; i++)
{
int* p = new int;
// ...
delete p;
}
}
It's important to reiterate here that delete p doesn't mean what you might think at first glance. You can read delete p as meaning "Delete the object that the pointer p points to." In each case, p points to an integer that we dynamically allocated using new; every use of new has a corresponding use of delete, so none of the dynamically-allocated integers leak.
What about the pointer p, though? Who deletes it? Remember that it's a local variable, so it's statically allocated; it will be destroyed automatically when the function ends.
The "dangling pointer" problem
There's one more wrinkle to consider when deleting a dynamically-allocated object. When you delete it, you do so by giving the delete operator a pointer to that object; at that point, the object is deleted, but the pointer is not. So where does that pointer, then, point?
The answer is that it points just exactly where it did before, to the object that delete just deallocated for us. So, technically, this code is legal (though certainly not moral):
int* p = new int;
*p = 3;
delete p;
std::cout << *p << std::endl;
After the point where we say delete p, the pointer p is still in scope, but dereferencing it (i.e., following it to the now-deallocated memory it points to) results in undefined behavior. It may accidentally work, it may behave unpredictably, or it may even crash the program.
Words of warning and encouragement
The old saw that "with great power comes great responsibility" applies here. You have the power to control how memory is allocated and how and when it is deallocated. This gives you a high level of control over the performance characteristics of the programs you write, but the onus is on you to manage these details correctly. And the unfortunate part is that mismanaging it will often result in hard-to-find bugs, where programs gradually and quietly use up memory until they run out and grind to a halt, or where programs give unpredictable results or simply crash for no apparent reason.
There are a lot of subtleties to consider whenever you create an object using new. It's your responsibility as a C++ programmer to think these things through, to implement them correctly, and to test them. Every time you create an object with new, think about what part of your program should be responsible for deleting it. If the answer is "the same function in which it was created," what you probably want is a statically-allocated local variable instead, unless the object is particularly large or has an indeterminate size. If the answer is anything else, now you have some design work to do.
We'll see, as we learn more C++, that there are tools that significantly mitigate problems like these, which automate some of the most common usage patterns that you'll encounter. But we first have to learn how the underlying, lower-level constructs like new and delete work; they're the tools on top of which the simpler ones are built.