Background
If you've learned very much C++ before, you've no doubt worked your way through the details of how memory is managed. When you've written classes, you've striven to make them what you might call "well-behaved," which means that they manage memory properly — including when their objects are created, copied, assigned, and destroyed — and follow various other reasonable semantic rules that C++ is built around. If you're not entirely familiar with things like copy constructors, assignment operators, or the use of const in the signature of a member function, it might be worth taking a look at the following set of notes from the most recent offering of my ICS 45C course.
I'll assume familiarity with those concepts throughout the discussion of the present topic.
Copying and assigning objects in C++
As you've seen previously, there are a number of ways to trigger copying or assigning of objects in C++.
- Declare a new variable and initialize it as a copy of an existing one.
std::string s = "Alex";
std::string t = s; // copies the contents of s into t
Afterward, anything done to t will have no effect on s, or vice versa, so the contents of s will need to be copied into t when t is constructed.
- Passing an object as a pass-by-value parameter to a function. The expected guarantee is that anything that's done to a pass-by-value parameter in a function will have no effect on the original, so we'll need to make a copy into the parameter.
- Assigning the value of one variable into another already-existing variable.
t += " Thornton";
s = t; // copies the contents of t into s, replacing existing contents of s
Afterward, anything done to s will have no effect on t, or vice versa, so the contents of s will need to be replaced with a copy of the contents of t.
In every one of these cases, there is a common outcome: Once the contents of one object are copied into another, the two copies are separate, so any subsequent modification made to one will not affect the other. The only time this isn't true is when you have a class that hasn't been implemented properly; a well-designed C++ class will always do one of two things:
- Support copying and/or assigning properly, in the way described. For classes with only well-behaved member variables, this will be the default; for others (e.g., when there are member variables that are pointers to dynamically-allocated storage owned by the object), we generally need copy constructors and assignment operators to make this work properly.
- Disallow copying and/or assigning altogether, so that it is a compile-time error to even attempt to do it. Some objects can't be copied in a natural way — the standard output object, std::cout, is an example. Others are unsafe to copy, such as std::unique_ptr. In these cases, the copying is made illegal.
The ideas here are the same whether we're talking about tiny objects like ints or larger, more complex objects like std::vector or std::map. Either way, the semantics of copying are expected to be the same in C++; a copy is a copy. The only difference is that the more complex types require custom behavior — because the default of simply copying or assigning all of the member variables leads to problematic behavior, like copied linked lists that share the same nodes — which leads us to have to write copy constructors and assignment operators.
Swapping, revisited
In the Templates notes, we saw a function template called myswap, which was intended to be able to swap values between two variables of the same type. That function template is duplicated below:
template <typename T>
void myswap(T& a, T& b)
{
T temp = a;
a = b;
b = temp;
}
We implemented myswap using a fairly standard three-line approach based around copying the values of a and b:
- Copy the value of a into a temporary variable, so we can safely change it without losing its original value. (A temporary variable turns out to be unavoidable here, since we have to change one variable at a time.)
- Next, copy the value of b into a. At this point, a and b are separate copies of the same value, the original value of b.
- Finally, copy the original value of a from the temporary variable into b. At this point, a's value is the original value of b and b's value is the original value of a; the values have been swapped.
It's easy to see why this strategy works; writing out some integer values on a piece of paper and tracing the execution line by line should be enough to convince yourself that this approach is correct. But is this actually a good way to solve the problem? The answer depends very much on what kinds of objects you're swapping. If you're swapping int values, this is a perfectly reasonable approach, because the copies — one copy constructor call (a copy-constructed into temp) and two assignment operators calls (b into a, then temp into b) — are relatively inexpensive, and anything fancier (using pointers or references or some other approach to try to avoid the copies) would be at least as expensive as just copying the integers. But imagine, instead, that you're swapping std::vector<int> values. That's a very different story indeed.
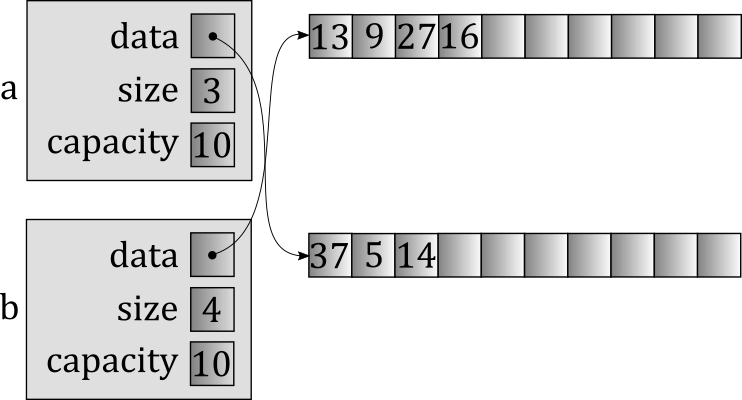
Let's suppose that each vector contains three member variables: data (a pointer to a dynamically-allocated array), size, and capacity. Watch what happens when we swap them using the myswap function template above, starting with our two vectors, a and b.
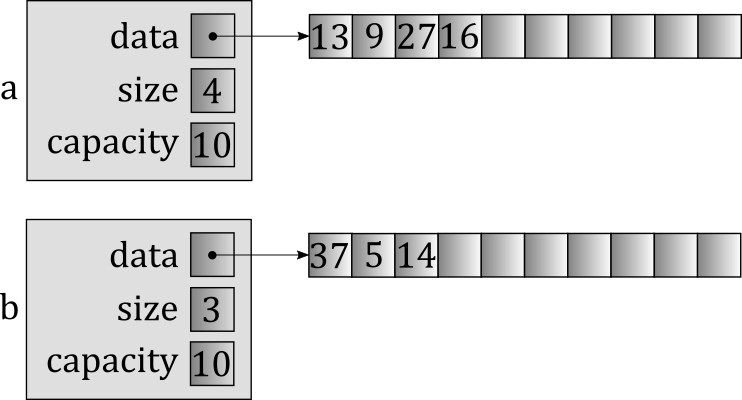
First, we copy a into temp, which allocates a brand-new array and copies the contents of a's array into it.

Next, we copy b into a. The most straightforward implementation would allocate a new array for a, then destroy the old one — that's what's pictured here — though a smarter one could certainly note that the capacities are the same as reuse the existing one.
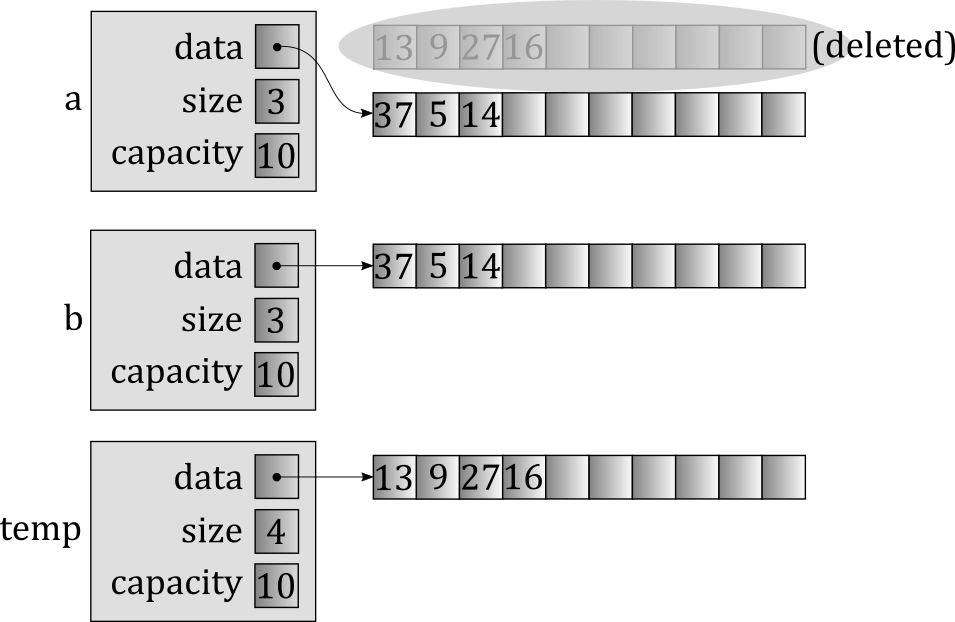
Next, we copy temp into b, again triggering a new array allocation, along with the deletion of an existing one. Again, this could have been avoided since the capacities are the same, but would not be avoidable if they were substantially different from one another.

Finally, the function ends, temp is destroyed, and we're left with the following final outcome.
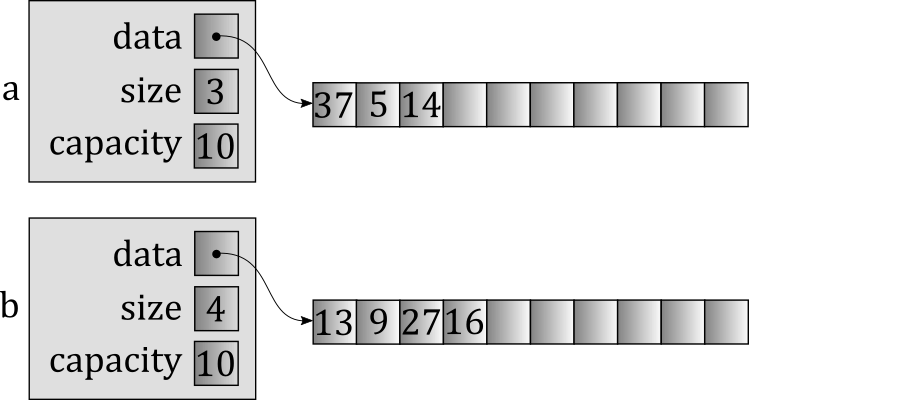
This is what we wanted, but at what cost? When you consider the actual behavior — and C++ requires that you think about things this way, because how you do things has such a profound impact on performance — you realize how much waste there is. The original contents of a have been copied twice, which means we've dynamically allocated two arrays and copied every element from one to the other both times. (Imagine these were std::vector<std::string> values instead! It's even worse then, because copying the strings will add even more cost!) Additionally, the original contents of b have been copied once. While it might be possible for the copy constructor and assignment operator to do some fancy footwork to eliminate at least some of the allocation (e.g., by reusing exsting arrays instead of allocating new ones), the basic problem remains: We're making copies of things that, when you think about it, don't really need to be copied at all.
By way of analogy, suppose that we're instead talking about sequences of numbers written on pieces of paper. I'm holding one piece of paper that we'll call a and you're holding the other that we'll call b, each with a different sequence of numbers. Now suppose we wanted to swap sequences, so each was holding the other person's sequence. In this analogy, our myswap implementation would be the equivalent of doing this:
- Obtaining an additional piece of paper that we'll call temp, then writing the sequence from a on to temp.
- Obtaining another additional piece of paper, then writing the contents of b on that paper. We'll call this new piece of paper a and then throw away the paper we used to call a.
- Obtaining yet another additional piece of paper, then writing the contents of temp on that paper. We'll call this new piece of paper b and then throw away the paper we used to call b.
- Finally, we'll throw away the paper we call temp, because we no longer need it.
Maybe we could avoid some of this work by, for example, erasing the numbers and rewriting new sequences on the same paper, but the fact remains that we'd spend a lot of time rewriting the sequences, one way or another. And, when you think about it, this all seems very silly. If all we want is for me to have your sequence instead of mine, and for you to have my sequence instead of yours, why don't we just exchange papers and be done with it? I'll hand you my paper, you hand me your paper, and that's it; we're done! (Even if you stretch the analogy to be a bit more like C++ and say we can each only hold one paper at a time, I could put my paper on a desk, you could hand me your paper, and then you could pick up my paper. Simple!)
This idea wasn't lost on the designers of C++, and, in the case of swapping, it's long been possible to work around the problem.
Specializing the swap operation for std::vector
For a long time, it's been possible in C++ to implement specializations of templates, which is to say that we can supply a special version of a template for a particular set of template parameters. This allows us to have the basic, generic behavior that's used most of the time, while still being able to specify something better in cases where we know we could do better. A specialization of our myswap function for std::vector might look something like this:
template <typename T>
void myswap(std::vector<T>& a, std::vector<T>& b)
{
a.swap(b);
}
As luck would have it, std::vector has a swap member function, so this turns out to be quite easy to implement. Given that it's a member function, it has full knowledge of how std::vector is implemented, so it's smart enough to realize something important: If you want to swap the contents of two vectors, all you have to do is swap the pointers to the dynamically-allocated arrays, as well as the size and capacity values. There's no need to make any copies of the arrays themselves, or to touch any of the individual elements. So this swap will actually be quite cheap, even if the vectors are large. Suppose we started with this scenario:
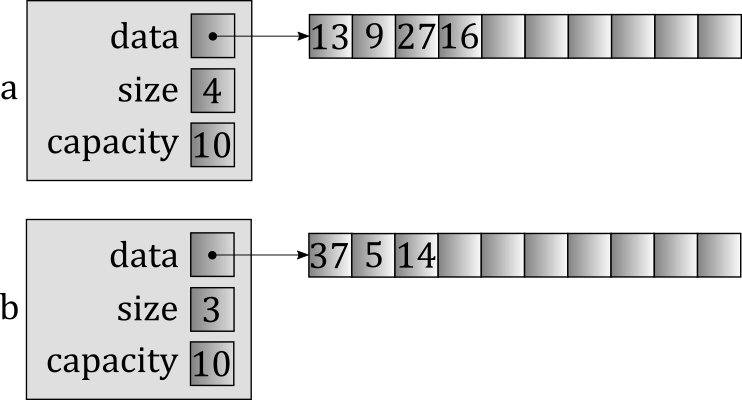
After running our specialized version of myswap on these two vectors, here's what we would get:
Particularly when you're talking about objects for which copying is expensive — and data structures are a great example of this, since they can often grow arbitrarily large — the name of the game is avoiding copies at all costs. We can partly win this battle by passing them by reference instead of by value, or by using smart pointers to "share" them. But, as we've seen with myswap, there are still times where we'll need to give some thought to the details; if we write code without thinking carefully enough about its impact, there can be an awful lot of work going on behind the scenes to implement something that could ultimately be done with a lot less work if we were more careful.
Compilers, too, can help. They've gotten better over the years at eliminating at least some unnecessary copying, using a technique called copy elision.
How copy elision helps
Compilers can be more clever than we sometimes give them credit for. Generally, the goal of a C++ compiler is to emit code that is observably equivalent to the code that we wrote; in other words, a compiler is permitted to generate any code it likes, so long as the observable effect of that code — what it looks like the code does, ultimately — is the same as what we wrote. This means that the code that's generated is often quite different than a naive reading of our code might make us believe.
For example, consider this C++ statement:
std::vector<int> v = std::vector<int>{1, 2, 3, 4, 5};
A naive reading of that statement would make us believe that it does the following:
- Constructs a new temporary vector of five integers (1, 2, 3, 4, and 5).
- Constructs v as a copy of that temporary vector of five integers.
- Destroys the temporary vector, since it's no longer necessary.
It's clear, though, that this is a pretty wasteful approach. Why build the temporary vector and leave it alive just long enough to copy it into v? Why not just eliminate all of that and construct v directly, so that it contains the five integers, and be done with it?
C++ compilers do what's called copy elision to deal with cases like this. At well-defined times — the C++ standard actually defines when this is allowed to occur, since constructors, copy constructors, and assignment operators might have side effects — the unnecessary copies will be eliminated automatically. In the statement above, for example, since the temporary vector lasts only long enough to copy-construct it into v, the compiler simply constructs the temporary into v in the first place; v becomes a vector of five integers with a regular constructor, and the temporary never exists.
There are other cases where copy elision takes effect, as well. Another example occurs when values are returned from functions and then immediately stored into variables.
std::vector<int> build()
{
return std::vector<int>{1, 2, 3, 4, 5};
}
...
std::vector<int> v = build();
In a case like this, a compiler is permitted to elide the copy, instead constructing the returned vector directly into the variable v. Similarly, temporary values passed into pass-by-value parameters can be constructed directly into those parameters, again eliding a copy.
But, unfortunately, this technique only gets us so far; there are plenty of copies that the compiler is not allowed to elide. But, thanks to some advances in C++ (since the C++11 standard), if we write our own code more carefully, we can remove certain other kinds of unnecessary copies ourselves, by implementing them instead as moves.
Moving instead of copying
While it has long been possible to customize swapping behavior to make it more efficient by specializing the std::swap function in the C++ Standard Library, swapping turns out to be a special case of something that's actually more general. Sometimes you want the value of one variable to be stored in another variable, but you don't want to make a copy of it, because only the new variable needs its value subsequently. In a case like that, all you want is for that value to move to a new variable instead.
You're probably already quite familiar with the distinction between copying and moving in other contexts. For example, you've no doubt seen this distinction in the context of files on your hard drive.
- If you copy a file, that file's contents are now separately stored in two places. Subsequently, anything you do to one of those copies will not affect the other.
- If you move a file — say, from one directory to another — then its contents are still only stored once, albeit in a different place.
It may not surprise you to know that moving a file is generally a lot cheaper than copying it, because filesystems tend to be implemented in such a way that a file contains something akin to a pointer to its contents. Moving a file, conceptually, requires putting that same pointer in a different place, but the contents of the file don't have to actually move, so it's no more expensive to move a large file than it is to move a small one. (You may also have noticed that moving a file from one hard drive to another, or from a hard drive to a USB stick, behaves quite differently. That can't be done without copying the contents of the file to the new device; a move between devices would actually be implemented as a copy followed by a deletion.)
Let's suppose, hypothetically, that there was a move operator in C++, somewhat akin to assignment, but whose goal was to move the contents of a variable into another, rather than copying it. We'll say that this operator is written as ⇐, where a ⇐ b moves the value out of b and into a, leaving b in an undefined state. If there was such an operator, then you could write our myswap function template much differently:
template <typename T>
void myswap(T& a, T& b)
{
T temp ⇐ a;
a ⇐ b;
b ⇐ temp;
}
Why this would be different is that moving is a different operation than copying. For example, if the type T was std::vector<int>, the moves would be substantially cheaper than the corresponding copies, because it would require only adjusting pointers to dynamically-allocated arrays, rather than creating new arrays or copying values from one into another. In more detail, here's how this might work. Let's suppose, again, that each vector contains three member variables: data (a pointer to a dynamically-allocated array), size, and capacity.
- First, a would be moved into temp, which would make these changes:
- Set temp's data to be a's data. This is simply a pointer copy, which is quite inexpensive.
- Set temp's size and capacity to be a's size and capacity. Again, this would be quite inexpensive.
- Set a's data to nullptr, since it no longer has any contents.
- Set a's size and capacity to 0.
- Next, b would be moved into a, which would be implemented similarly. a would now have the same data, size, and capacity that b used to have, and b would now be empty.
- Next, temp would be moved into b, which would also be similar. b would now contain the contents of temp, and temp would now be empty.
- Finally, the local variable temp would be destroyed, since we've reached the end of the function. But since temp is empty, it will be destroyed quite easily; there's nothing to deallocate.
This implementation of myswap has almost no unnecessary overhead left in it. None of the elements of either a or b were ever copied or even touched; instead, pointers were swapped, which is cheap (and doesn't scale linearly with the size of the vectors).
It should be noted that the move operator described here doesn't exist in C++, but there is an implementation of this same idea, which is called move semantics. From a performance perspective, being able to move things instead of copy them can eliminate a lot of unnecessary overhead, particularly when you talk about objects that would be complex or expensive to copy. Let's take a look at how the actual implementation of move semantics in C++ works. (Note that this is a feature that was added to C++ relatively recently, in the C++11 standard, so you'll need a relatively recent compiler to make use of it. The compiler on the ICS 46 VM supports it, so you're on safe ground there.)
Move semantics in C++
Lvalues and rvalues, revisited
C++ programs, fundamentally, manipulate values. Values are stored in variables, passed as parameters, returned from functions, used temporarily and then thrown away, and so on. To make sense of all of this, C++ distinguishes between a few kinds of values, most notably lvalues and rvalues.
- An lvalue is one that has storage allocated to it. For example, when you evaluate the name of an existing variable in an expression, that's an lvalue, because variables are stored in memory.
- An rvalue is one that does not have storage allocated to it, such as the value of an expression that was calculated temporarily.
The letters l and r are used to distinguish left from right, the basic distinction being that lvalues can appear on the left-hand side of an assignment and that rvalues can appear only on the right-hand side. So, for example, it's legal to say this:
x = 3;
because x is an lvalue (i.e., it refers to a location in memory), but it's not legal to say this:
3 = x;
because 3 is an rvalue, so where would we be storing a result?
Lvalue references
We've seen, many times, that you can declare variables that are references in C++. References establish an alternative name for some object. Once you've bound it to an object, any time you use the reference, you're using the original object; the two are synonymous.
int i = 3;
int& r = i; // r is now bound to i
r = 9;
std::cout << i << std::endl; // prints 9
You've probably noticed that it's not possible to bind a reference to a constant:
int& r = 9; // not legal!
The technical reason is that 9 is not an lvalue; it has no storage associated with it, so a subseqeuent assignment to r would be meaningless. For this reason, C++ nowadays has a more specific name for the kinds of references you've seen previously: they're called lvalue references, because they can only refer to lvalues.
Rvalue references
Beginning in C++11, we now have what are called rvalue references, which are permitted to refer to rvalues but not to lvalues. An rvalue reference to an int rvalue would have the type int&&; the two & characters are what tells you that the reference is an rvalue reference (as opposed to the single & character used to denote an lvalue reference). At first blush, that seems like a very odd feature to include in the language, but it is surprisingly useful in practice. Let's first make sure we understand their basic mechanics.
int i = 3;
int&& r1 = i; // not legal; i is not an rvalue
int&& r2 = 9; // legal, since 9 is an rvalue
A bit more technically, the real distinction here is that 9 is a value that is expiring, which is to say that it will die as soon as the expression it arises from has been evaluated. Rvalue references allow you to keep expiring values alive a bit longer, so you can do something with them before they die.
It should be noted that all of this gets a lot more complicated than I'm explaining here, particularly in cases where you use rvalue references with types that aren't determined until a template is instantiated. But this understanding is enough for us to understand how to implement move semantics, which is one of their primary uses.
Move constructors
Beginning in C++11, a new kind of constructor called a move constructor is now available to us, and can be written in any class where we need one. A move constructor's job is to move the value of its parameter into the object being constructed, leaving the parameter essentially valueless (or, at the very least, in some valid state) afterward. Granted, because they have an effect on their source, they are potentially dangerous, but they're only actually used in scenarios where that danger doesn't exist: when the source is an rvalue. We denote that by writing the move constructor so that its parameter is an rvalue reference, so it will only be called when the source is an rvalue.
class X
{
public:
...
X(X&& x); // move constructor
...
};
Since we know that the parameter is about to expire, it's safe for us to do things that would otherwise be problematic. For example, a hypothetical move constructor for std::vector might look something like this:
template <typename T>
std::vector<T>::vector(std::vector<T>&& v) noexcept
: data{nullptr}, size{0}, capacity{0}
{
std::swap(data, v.data);
std::swap(size, v.size);
std::swap(capacity, v.capacity);
}
In this case, we've essentially cannibalized the internals of v, placed them inside of the newly-constructed vector, and left behind empty internals in v. Since we know that v is a vector that is about to expire, then we leave it in a state where it will be inexpensive to clean up. But rather than copying the internals of v into our newly-constructed vector, we've moved them, which is to say that the newly-constructed vector now looks exactly like v used to look; it points to the same array and has the same size and capacity. And not a single element of the array was touched or copied, so this was very inexpensive.
Note that we were able to mark this move constructor noexcept because all we're doing is swapping the values of pointers and integers; nothing can fail. (This is not uncommon in move constructors, and we generally want to mark them as noexcept whenever we can, because that triggers some optimizations that aren't available without it.)
We need not invoke this constructor directly. A C++ compiler will automatically generate code that calls it in cases where it's reasonable and safe to do so, and, for the most part, the defaults work as you would expect. The advantage is that cases where vectors can be moved will now be substantially faster — asymptotically faster! — than they used to be. Could we leave out a move constructor and let the copy constructor do the work? Sure, we could. But adding a move constructor is a great performance optimization in cases where moving could be implemented a lot more cheaply than copying, particularly if you're implementing something like a data structure, whose size may grow arbitrarily large.
Move assignment operators
Similarly, C++11 added the notion of a move assignment operator, which is one that assigns an expiring value into an existing variable by moving it. Again, a parameter with an rvalue reference type is used to distinguish it from a typical (copy) assignment operator.
class X
{
public:
...
X& operator=(X&& x); // move assignment operator
};
As with move constructors, the knowledge that a move assignment operator's parameter is an expiring value makes it possible for us to do things that are much more efficient than we could if the parameter had to live on. For example, a hypothetical move assignment operator for std::vector might look something like this:
template <typename T>
std::vector<T>& std::vector<T>::operator=(std::vector<T>&& v) noexcept
{
std::swap(data, v.data);
std::swap(size, v.size);
std::swap(capacity, v.capacity);
return *this;
}
Note that we've being careful to swap the old value of the target vector into the source vector, rather than leaving the source vector in an empty state. This is important because it ensures that the old value of the target vector — which has been replaced by the new value — will still need to be destroyed. But since we know the source vector is expiring, we know that its destructor is about to be called, so we might as well let that destructor clean up the target vector's old value for us.
Once again, I should point out that a move assignment operator is not a requirement in a C++ class, because a (copy) assignment operator can always be used in its place, but move assignment can add a very important layer of optimization for types where copying is expensive, particularly if you're implementing something like a data structure, whose size may grow arbitrarily large.
std::move and rewriting our myswap to use moves instead of copies
There is one more wrinkle that is worth understanding. While a C++ compiler is capable of determining, in many cases, that values are about to expire, there are times when it's not obvious from the context of the code you wrote, yet you can determine that a value should expire at a certain point. As an additional performance optimization, you can "force" a value to expire by calling a function in the C++ Standard Library called std::move. It's important to point out that std::move is actually a somewhat misleading name, because it doesn't actually move anything; what it does is cast a value to its corresponding rvalue reference type, which means that the compiler will now freely assume that the value is about to expire. Anything you do with it subsequently is considered undefined behavior, but if you use this carefully, you can achieve a lot of benefit in some circumstances.
The std::move function in the C++ Standard Library isn't just a curiosity; it actually has a lot of use. For example, it allows us to write something very much akin to the hypothetical myswap that we proposed using the nonexistent ⇐ operator.
template <typename T>
void myswap(T& a, T& b)
{
T temp = std::move(a);
a = std::move(b);
b = std::move(temp);
}
Note that this is the implementation of std::swap in the C++ Standard Library these days, so there is much less need to implement custom swap functions than there once was. By solving the more general problem — allowing moves in place of copies, when appropriate — the more specific problem is solved automatically.