Abstract: This paper introduces the problem of understanding what software process redesign (SPR) is, and how software process modeling, analysis and simulation may be used to support it. It provides an overview of research results from business process redesign to help draw attention to the importance of treating process redesign as a process of organizational and process transformation. This in turn requires examining and practicing SPR through an approach that combines organizational change management together with process management technologies. A discussion follows which then identifies a number of topic areas that require further study in order to make SPR a subject of software process research and practice.
Keywords: software process, process redesign, business process redesign, process modeling and simulation
1. Overview
Software process improvement (SPI) has traditionally been focussed on addressing how to improve the capabilities of a software development organization through maturing and comparative benchmarking of its software processes. The Capability Maturity Model from the Software Engineering Institute is the most visible SPI initiative of its kind. However, the CMM is targeted to incremental improvement of existing software processes. The CMM top-most level, Optimization (Level 5), characterizes those organizations whose software processes are incrementally improved and refined through monitoring, measurement and reflexive analysis of well-defined and well-managed processes. Nonetheless, the CMM does not provide specific guidance or a maturity level that implicitly prescribes how to fundamentally rethink how to optimize software processes to achieve on the order of 10X improvement through radical transformation. Are radical transformations of software processes the same as incremental evolutionary improvements? Probably not, though they appear to lie along a common dimension or metric that characterizes the scale or scope of process change that is sought. As such, software process redesign (SPR) merits investigation to determine whether and how it might lead to dramatic improvements in process efficiency or effectiveness.
The study presented in this paper introduces the topic of SPR. It describes how concepts, techniques and tools for software process modeling, analysis and simulation may be employed to support SPR studies. In particular, three research questions that explore and elaborate these topics can be identified as follows:
2. What is software process redesign
SPR is concerned with identification, application and refinement of new ways to improve software processes. Software processes of interest include not only those associated with software development, but also those for software system acquisition [SB98], use and evolution. Redesign heuristics serve as the main source of knowledge for how to dramatically improve the cycle time, defect prevention, and cost effectiveness of various kinds of software/business processes [VS99]. However, where do these heuristics come from? What can we learn from the results of business process redesign (BPR) studies? Is the Web a useful source of SPR knowledge? Let us consider each in turn.
2.1 Where do SPR heuristics come from
SPR heuristics can be derived through empirical studies of before and after focal processes have been redesigned [e.g., SN97]. The results of these studies are often cast in forms such as experience reports, case studies, lessons learned or best practices [DP98, O98], rather than from controlled, carefully designed experiments [ZW98]. As the generalizability of such studies is usually limited, the story, contexts and insights they may convey can be enlightening or sensitizing. Accordingly, this is why attention is drawn to heuristic knowledge to guide SPR. Nonetheless, SPR heuristics can also be derived from theoretical propositions that characterize how to most effectively redesign complex processes, or from patterns in measurable properties of formal representations of processes for redesign.
SPR heuristics may be domain independent and therefore applicable to a large set of processes. Alternatively, SPR heuristics may be domain specific, thus applicable to specific processes in particular settings. Both domain independent and domain specific SPR heuristics are sought. In examining how SPR heuristics are applied, we can learn the circumstances in which different types of heuristics are most effective or least effective. Similarly, we can learn which process redesigns are considered most effective and desirable in the view of the participants working in the redesigned process, or which redesigns are considered undesirable by the participants [SN97, VS99]. However, part of the challenge in identifying SPR heuristics of any kind is that unless they are explicit, most of these heuristics implicit. This means they are likely to be found through comparison across a diverse sample of redesign case studies, rather than conveniently found in a single repository. This kind of comparative domain analysis can be a high-skill, labor-intensive activity. Nonetheless, new technologies are creating options that may make such activity more manageable.
Therefore, it is useful to acknowledge that finding and ferreting out SPR heuristics is a difficult task. However, a structured scheme for taxonomically classifying SPR heuristics, or a repository populated with SPR heuristics, are likely to be valuable assets for research purposes or commercial applications of SPR. As such, there is motivation for finding more such heuristics, as well as for building alternative classification taxonomies and repositories for SPR.
2.2 Lessons from Business Process Redesign
The work of Hammer, Davenport and their colleagues brought attention to the problem of business process redesign (BPR) or process reengineering. Following their advice, existing or legacy software processes should be either (a) obliterated, not automated [H90], or else (b) understood and measured [DS90]. In turn, innovative to-be software processes should be designed and prototyped using leading-edge software engineering and other information technologies (ITs) as a new foundation for coordinating software development and use activities [DS90]. However, the ability to successfully realize the benefits of radical IT-based changes in most business processes has been elusive.
Reflective studies of the problems, pitfalls and best practices of BPR find that certain organizational variables, rather than IT, are key to achieving successful BPR outcomes [BMR94, HRW93]. In many of the BPR projects examined, BPR failure was reported to be the outcome about 70% of the time [BMR94]. How can BPR failure be avoided when redesigning software processes? Available research results from BPR studies indicate that critical conditions to help realize success should include the participation and commitment of top management executives, empowered workers, shared vision, realistic expectations, changes in worker roles and responsibilities, new performance measurements, worker incentives, and the like [BMR94, HRW93]. Conversely if these organizational conditions are insignificant or missing, then we should expect the application of BPR to software processes to fail.
The dilemma of how to realize the benefits of a successful BPR project, while avoiding the likelihood of failure, gave rise to a series of empirical field studies and surveys to track down the source of variation and causality. Results from representative investigations [CJS94, ESS95, GJ+95] emphasized the importance of addressing BPR implementation within the broader context of organizational change in a complex socio-technical environment [cf. KS82]. For instance, some organizations may choose to reengineer a set of processes (e.g., software life cycle processes) over time, in order to learn from what succeeds and what fails [CJS94]. Applying a lesson learned from Caron and colleagues [CJS94] to software process reveals that SPR efforts should be implemented within an organization bottom-up by the process end-users, rather than imposed top-down by senior management [cf. H90], to succeed. Following this, senior management should provide the strategic vision for an effort to redesign software processes that empowers process staff to participate in directing and implementing the effort [ESS95]. Similarly, change management strategies and techniques, technological competence, tactical planning and project management, and training personnel for to-be processes, should be factors related to success when redesigning software processes [GJ+97GJKW95
].
Drawing from the emerging theoretical basis of BPR [KG95], when redesigning software processes, focus should be on the creation of an organizational environment that support change management strategies. Central among them are organizational commitments to foster a process learning and experimentation environment, knowledge sharing supplemented with software technologies, internal and external partnering, and measurable process improvements, as prerequisites for BPR success. Similarly, when reengineering software development processes, effort should be directed at enhancing the level of team development, cooperative work, and collaborative learning [JW+97].
Finally, recent studies of BPR establish ties between process change and their consequence on organizational performance. For example, applying the results of Guha and colleagues [GG+97], reengineering software processes should require the creation of a learning organization where articulating the interdependencies between the change environment, process management and change management is the focus. Last, when redesigning software processes, management control of organizational resources, such as software acquisition and development process expenditures, must remain effective though perhaps in a more streamlined manner [SN97a].
2.3 Can the Web help us learn about SPR?
We can all use the Web to conduct a global search and information retrieval. Though we may find little matching a search for "software process redesign", a search for "process redesign" or "process reengineering" will return much more. Here we might find case studies, experience reports, best practices or lessons learned as narrative documents posted on academic, non-profit, or commercial sites. Clearly, the quality of the "knowledge" and results gleaned from sources on the Web may be more erratic than those found in system research studies. But in searching for SPR heuristics, when potentially relevant source materials are found, hyperlinks can be used to label and associate the connection between the materials and the heuristics they instantiate. Subsequently, when a heuristic is potential candidate for use in redesigning a software process, its source can be browsed and reexamined to help determine its similarity, relevancy, trajectory or outcome. Subsequently, as interest in SPR activities and outcomes grows, then more SPR case studies, experience reports, lessons learned, best practices, counter-examples and caveats may soon find their way onto the Web. Thus, SPR heuristics or SPR knowledge repositories should be viewed as growth areas, rather than as a topic that can be exhaustively analyzed with limited effort.
3. How can modeling, analysis and simulation help SPR
There is a growing body of studies and techniques that address the modeling, analysis and simulation of software processes [P98]. Yet none of the extant studies address the subject of SPR as their primary focus. However, SPR is often implicit as a motivating factor in practical applications of software process modeling and simulation. As such, how can modeling, analysis and simulation of software processes be employed to directly support SPR?
3.1 Modeling process redesign knowledge
As already noted SPR knowledge is often cast as heuristics derived from results of empirical or theoretical studies. These results may then be coded as production rules for use in a rule-based system (i.e., a pattern-directed inference system) [N97], or as tuples (records of relation attribute instance values) that can be stored in a relational database [KS96]. Nonetheless, these alternative representation schemes do not focus on what needs to be modeled, which is the focus here.
From a modeling standpoint, there is need to potentially model many kinds and forms of SPR knowledge. These include (a) the process to be redesigned in its legacy, "as-is" form before redesign, (b) the redesign heuristics (or transformations) to be applied, (c) the "to-be" process resulting from redesign, and (d) the empirical sources (e.g., narrative case studies) from which the heuristics were derived. Furthermore, we might also choose to model (e) the sequence of steps (or the "here-to-there" process) through which different redesign heuristics were applied to progressively transform the as-is process into its to-be outcome. Modeling the processes identified in (a), (c) and (e) is already within the realm of process modeling and simulation capabilities. However, (b) and (d) pose challenges not previously addressed by software process modeling technologies. Furthermore, (b) and (d) must be interrelated or interlinked to the process models of (a), (c) and (e) to be of greatest value for external validation, traceability, and incremental evolution purposes [VS99, ZW98]. Finally, software process modeling will play a role in (f) facilitating the continuing evolution and refinement of the SPR knowledge web.
3.2 Analyzing processes for redesign
Software process models can be analyzed in a number of ways [MS90, SM97]. These analysis are generally targeted to improving the quality of the process model, as well as to detect or prevent common errors and omissions that appear in large models. Nonetheless, software process redesign poses additional challenges when analyzing process models.
First, it is necessary to analyze the consistency, completeness, traceability and correctness of multiple, interrelated process models (as-is, here-to-there, and to-be). This is somewhat analogous to what happens in a software development project when multiple notations (e.g., for system specification, architectural design, coding, and testing) are used, therefore requiring analysis across as well as within a the software notations.
Second, it is necessary to account for software process resources throughout the redesign effort. For example, are resources that appear in an as-is process replicated, replaced, subsumed, or removed in the to-be process? SPR can change the flow of resources through a process, and thus we want to observe and measure these changes on process performance.
Last, one approach to determining when domain-independent process redesign heuristics can apply results from measuring structural attributes of the formal or internal representation (e.g., a semantic network or directed attributed graph) of a process as index for selecting process redesign heuristics [N97, N98, SN97]. Each of these challenges necessitates further description and refinement, as well as characterizing how they can interact in a simplifying or complicating manner.
3.3 Simulating processes before, during and after redesign
Software process models can be simulated in a number of interesting and insightful ways using either knowledge-based, discrete-entity or system dynamics systems [P98, S99]. However, is there still need for another type of system to simulate processes performed by process users, and under their control?
When considering the role of simulation in supporting software process redesign a number of challenges arise. For example, how much of a performance improvement does an individual redesign heuristic realize? Will different process workload or throughput characterizations lead to corresponding variations in simulated performance in both as-is and to-be process models? How much of a performance improvement do multiple redesign heuristics realize, again when considered with different workloads or throughputs? Can simulation help reveal whether all transformations should be applied at once, or whether they should be realized through small incremental redesign improvements? As such, simulation in the context of SPR raises new and interesting problems requiring further investigation and experimentation.
As suggested earlier, there is need to simulate not only as-is and to-be processes but also the here-to-there transformation processes. Following from the results in the BPR research literature, transforming an as-is process into its to-be counterpart requires organizational change management considerations. The process users who should be enacting and controlling the transformation process can benefit from, and contribute to, the modeling and analysis of as-is processes [SM97, S99]. Similarly, users can recognize possible process pathologies when observing graphic animations of process simulations. However, the logic of the process simulation may not be transparent or easy to understand in terms that process users can readily comprehend.
Conventional approaches to process simulation may not be empowering to people who primarily enact software use processes [cf. SN97]. Instead, another option may be needed: one where process users can interactively traverse (i.e., simulate) a new to-be process, or the here-to-there process, via a computer-supported process walk-through or fly-through. In such a simulation, user roles are not simply modeled as objects or procedural functions; instead, users play their own roles in order to get a first-person view and feel for the new process. This is analogous to how "flight simulators" are used to help train aircraft pilots. In so doing, user participation may raise a shared awareness of which to-be alternatives make the most sense, and how the transformations needed to transition from the as-is to to-be process should be sequenced within the organizational setting. As such, simulation for SPR raises the need for new approaches and person-in-the-loop simulation environments.
4. Approach and Results
Given the challenges identified in the previous section on how to modeling, analysis and simulation can support SPR, this section presents the approach and initial results from an effort in each of these three areas.
4.1 Modeling Approach and Results
In developing models of processes for SPR, we used two tools. First, in order to represent SPR knowledge formally and reason with it, the Loom knowledge representation system was selected [MB95]. Loom is a mature language and environment for constructing ontologies and intelligent systems that can be accessed over the Web [VR+99]. By using Loom to re-implement the Articulator process meta-model ontology [MS90, MS96], formal models of software (or business) processes, classification taxonomies and process redesign heuristics can be represented and manipulated. In turn, process knowledge can be analyzed, queried, and browsed, while relevant redesign alternatives for processes can be identified and linked to source materials on the Web. Nonetheless, Loom does impose a discipline for formally representing declarative knowledge structures in terms of concepts (object or pattern types), relations (link types that associate concept) and instances (concept, link, attribute values).
Loom's deductive classifier utilizes forward-chaining, semantic unification and object-oriented truth maintenance technologies. This enables it to compile the declarative knowledge into a network designed to efficiently support on-line deductive query processing [MB95]. Further, Loom's classifier can be used to taxonomically classify and update the SPR knowledge base as new SPR cases are entered and formally modeled. This in turn enables the SPR knowledge web to evolve with automated support [VS99].
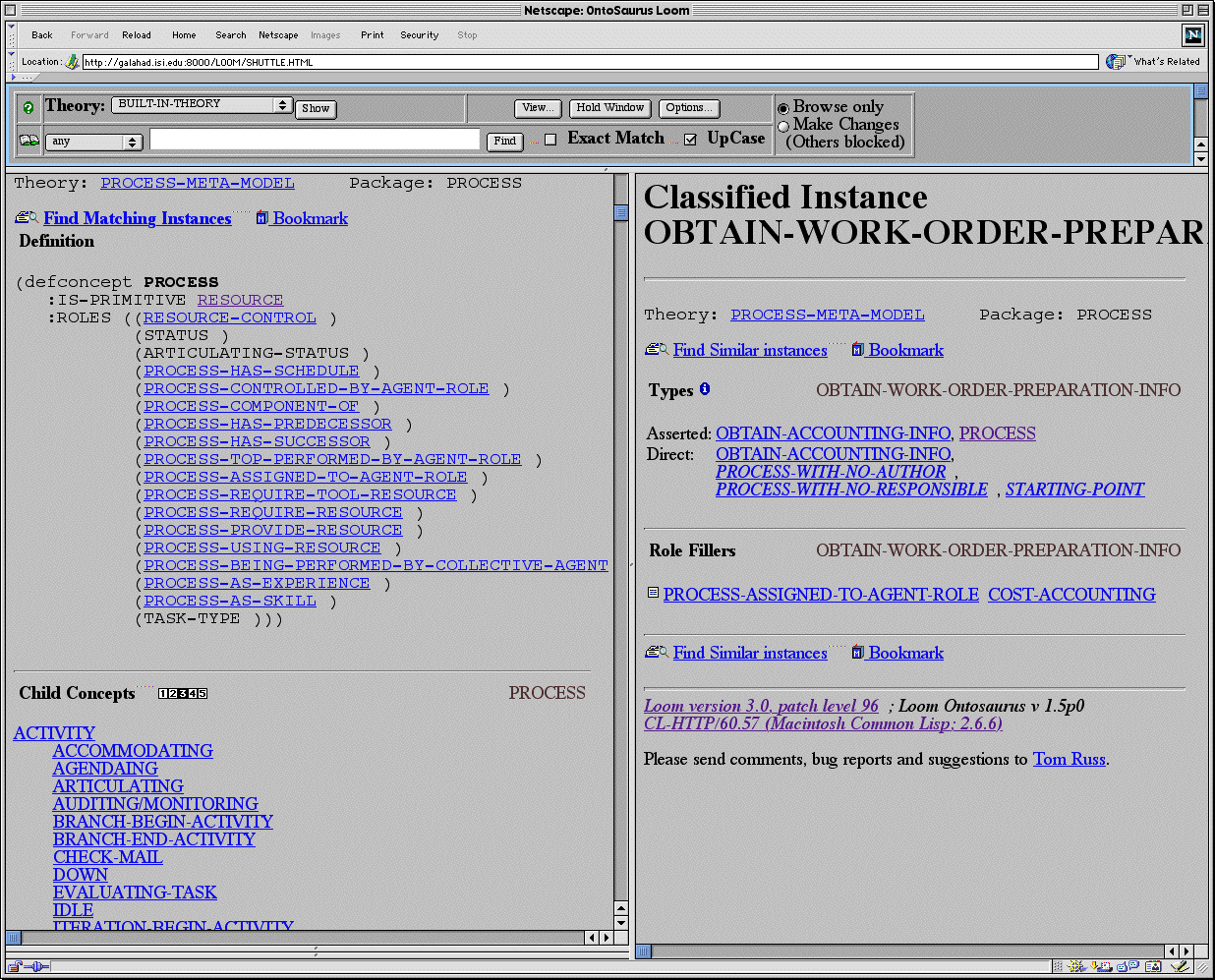
Second, in order to support the visualization of the knowledge bases and process models that have been constructed, a Web browser interface to the Loom system called Ontosaurus is used [ON99]. Ontosaurus is a client-side tool in which a Loom server loaded with one or more knowledge bases replies to queries and produces Web pages describing several aspects of the knowledge base. It is also able to provide simple facilities for producing general queries and editing the contents of knowledge bases. Figure 1 shows a browser window accessing Ontosaurus. The display consists of three window panels; Toolbar (top), Reference (left side) and Content (right side). The Toolbar panel consists of buttons to perform various operations such as select domain theory, display theory, save updates, etc. The Reference and Content panels are designed to display contents of a selected ontology. Links in both panels display their contents in the Content window. This facilitates exploring various links associated with a word or concept in the Reference window without the need to continuously go back and forth. The bookmark window holds user-selected links for Web pages to Ontosaurus pages, and is managed by the buttons in the bottom of the bookmark window.
We now describe how we built a knowledge-based system to represent and diagnose models of SPR. The system is based on an ontology of business processes expressed in Loom. Loom provides a semantic network knowledge representation framework based on description logics. Nodes in a Loom semantic network define concepts that have roles or slots to specify their attributes. A key feature of description logic representations is that the semantics of the representation language are very precisely specified. This precise specification makes it possible for the classifier to determine whether one concept subsumes another based solely on the formal definitions of the two concepts. The classifier is an important tool for evolving ontologies because it can be used to automatically organize a set of Loom concepts into a classification hierarchy or taxonomy based solely on their definitions. This capability is particularly important as the ontology becomes large, since the classifier will find subsumption relations that people might overlook, as well as modeling errors that could make the knowledge base inconsistent.
Overall, 30 process redesign heuristics have been identified and classified so far. Six taxonomies have also been identified for grouping and organizing access to the BPR cases found on the Web. These taxonomies classify and index the cases according to:
4.2 Analysis Approach and Results
The first challenge in analysis processes for redesign point to three types of problems that arise when modeling business processes. First, consistency problems refer to conflicts in the specification of several properties of a given process. For example, a typical consistency problem is to have a process with the same name as one of its outputs (something that occurs surprisingly often in practice, perhaps because the output is often the most visible characteristic of a process). Second, completeness problems cover incomplete specifications of the process. For instance, a typical completeness problem occurs when we specify a process with no inputs (a "miracle", which can produce outputs with no inputs) or no outputs (a "black hole", where inputs disappear without generating any output). Third, traceability problems are caused by incorrect specification of the origin of the model itself: its author, the agent(s) responsible for its authoring or update, and source materials from which it was derived. Subsequently, a process model that is consistent, complete and traceable can be said to be internally correct. Thus, solving these model-checking problems is required once process models are to be formalized.
One of the main reasons Loom is interesting as a formal process representation language is its capability to represent the abstract patterns of data that are the very definition of the problems discussed above. This capability is useful in producing simple and readable representations of model-checking analyses. For example, it is possible to define incomplete process model in plain English as "a process with no outputs", or as a black-hole. This can be described in Loom as a process that provides exactly zero resources:
(defconcept black-hole
:is (:and process
(:exactly 0 process-provide-resource)))
Using the process modeling representations discussed above, the user describes a process model through Ontosaurus for processing by Loom. Then the system diagnoses the model provided. One of the advantages of using Loom is that once we define an instance, Loom automatically applies its classifier engine to find out what concepts match and apply to that instance. This offers a big advantage, since there is no need to specify an algorithm for the analysis process: instead, process models are analyzed automatically as a new model is specified. In addition, the classifier performs truth-maintenance. Therefore, if process model is updated to correct a problem found by the system, the classifier will immediately retract the assertion that the problem applies to that process. Thus, the classifier automates this knowledge maintenance activity.
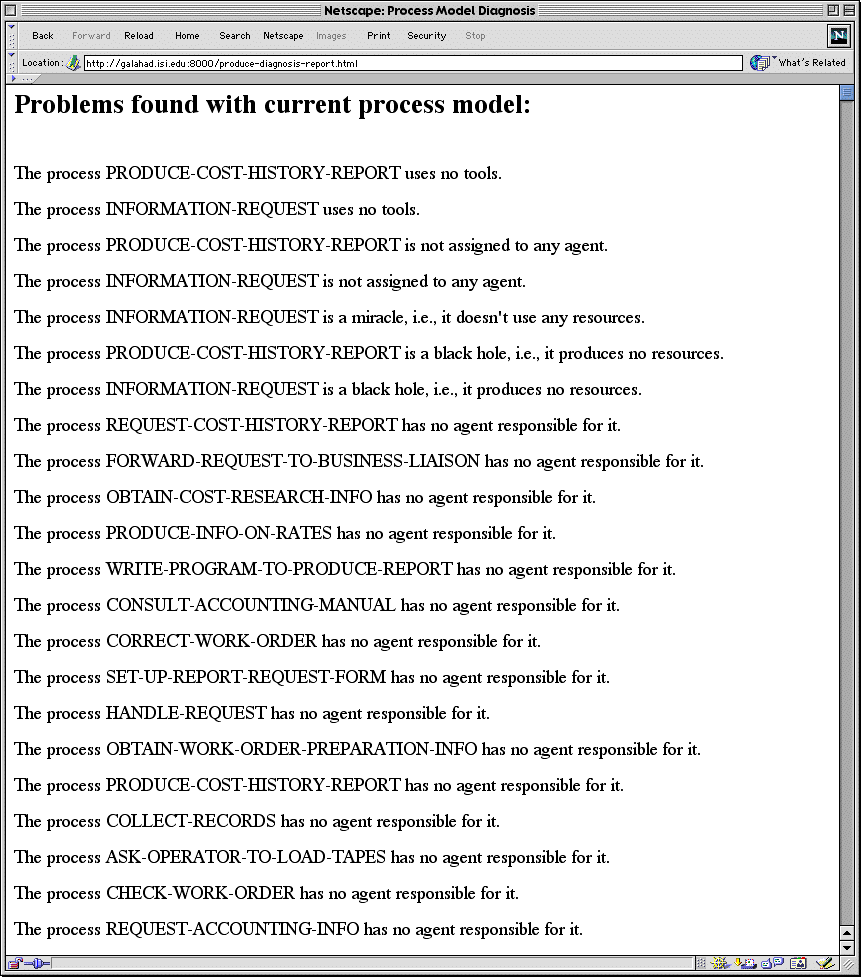
In order to provide a more direct interface to the diagnosis system, the Ontosaurus browser was extended to display two new types of pages. The first displays a description of process in a less Loom-specific way (e.g., for reporting purposes). The second displays a list of all problems found in the current process model we input. Figure 2 shows a screenshot of the Web page constructed by the server to describe the problems found in a model of a sample process.
The other two challenges for analyzing processes to support SPR can be addressed with a common capability that builds on the one just described. Since a formal representation of a software process model can be viewed as a semantic network or directed attributed graph, it is possible to measure the complexity attributes of the network/graph as a basis for graph transformation, simplification or optimization. This means that measures of a richly attributed "process flow chart" could reveal attributes such as the number of process steps, the length of sequential process segments, the degree of parallelism in process control flow, and others [N97, N98]. Subsequently, redesign heuristics can be coded as patterns in the structure of a process representation. In turn, it then becomes possible to cast a process redesign heuristic as a production rule (or pattern-directed inference rule) whose antecedent stipulates a process complexity measure pattern, and whose consequent specifies the optimization transformation to be applied to the process representation [N98]. For example, when analyzing a software process model, if a sequence of process steps has linear flow and the inputs and outputs of the steps are mutual exclusive, then the process steps can be performed in parallel. Such a transformation reduces the time required to execute the redesigned process sequence.
Thus, process analysis for SPR can focus on measurement of attributes of a formal representation of a software process model that is internally correct. This is similar to how compilers perform code optimizations during compilation, after parsing and semantic analysis while prior to code generation.
4.3 Simulation Approach and Results
Questions pertaining to simulated process throughput performance or user workloads before/after process redesign can already be addressed by process simulation tools and techniques [P98, S99]. No significant advances are required for this. Similarly, knowledge-based simulation capabilities can be employed to determine process performance improvements when multiple redesign heuristics are used to create alternative scenarios for software process enactment [cf. CJS94, S99]. Nonetheless, the challenge of how to support the transformation of as-is software processes into to-be redesigned alternatives is not addressed by existing process simulation approaches; thus a new direction is required.
One key requirement for managing the organizational transformation to a redesigned software process is the engagement, motivation and empowerment of process users. The goal is to enable these users to direct and control process redesign efforts, as well as to select the process redesign alternatives for implementation and enactment. As the direct use of available simulation packages may present an obstacle to many process users, another means to support process management and change management is needed.
The approach we choose was to engage a process user community in a multi-site organizational setting and partner with them in redesigning their software use processes [SN97]. In particular, we developed, provided and demonstrated a prototype wide-area process walkthrough simulator that would enable the process redesign participants with a means to model, redesign and walkthrough processes that span multiple settings accessed over the Internet. With this environment, 10 process redesign heuristics were found applicable, while the process users chose 9 to implement [SN97]. In so doing, they eventually achieved a factor of 10X in cycle time reduction, and reductions in the number of process steps between 2-1 and 10-1 in the software use processes that were redesigned [SN97]. A process simulator played a central role in the redesign, demonstration and prototyping of these processes. How was this realized?
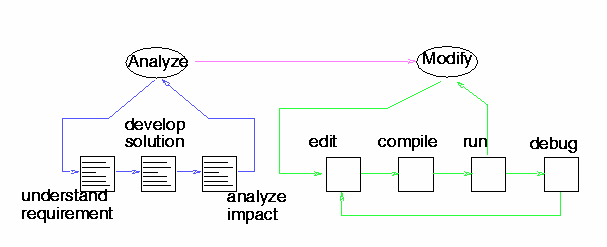
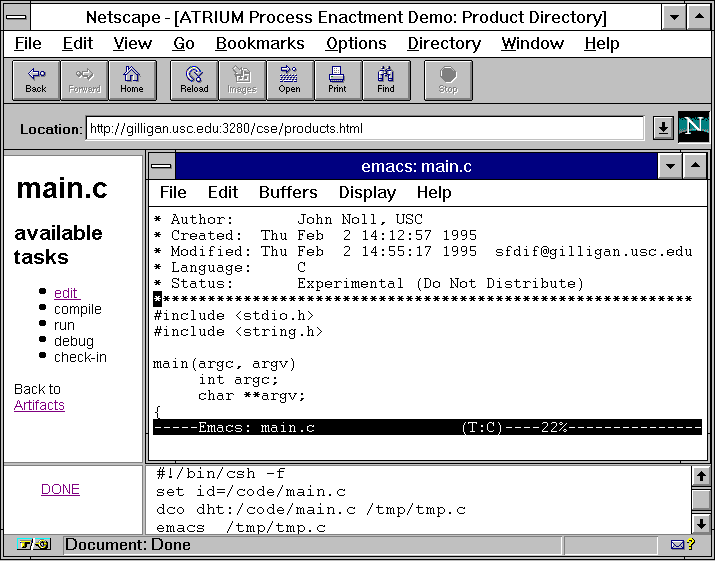
Process prototyping is a computer-supported technique for enabling software process models to be enacted without integrating the tools and artifacts required by the modeled process [SM97]. It allows process users the ability to interactively observe and browse a process model, step by step, across all levels of process decomposition modeled, using a common Web browser as its graphic user interface. Creating a basic process execution run-time environment entails taking a prototyped process model and integrating the tools as helper applications that manipulate process task artifacts attached to (manually or automatically) generated Web/intranet hyperlinks (URLs) [NS99]. Consider the following example of a simple software development process displayed in Figure 3.
Figure 3: A simple software development process depicted as a directed graph
This process can be modeled in terms of the process flow (precedence relations) and decomposition. It can also be attributed with user roles, tools and artifacts for each process step. Further, as suggested above, the directed attributed graph that constitutes the internal representation of the process can be viewed and browsed as a hyperlinked structure that can be navigated with a Web browser. The resulting capability allows process users the ability to traverse or walkthrough the modeled process, task by task, according to the modeled process's control flow. This in turn realizes a Web-based or intranet-based process simulator system. Figure 4 provides a view of a set of artifacts that might be associated with the process in Figure 3. Figure 5 provides a similar view of a selected task ("edit"), tool (the Emacs editor), and artifact (loaded in the Emacs edit buffer) associated with a user role as a "developer" (not shown). In addition, the lower right frame in Figure 5 displays a record of the history of process task events that have transpired so far.
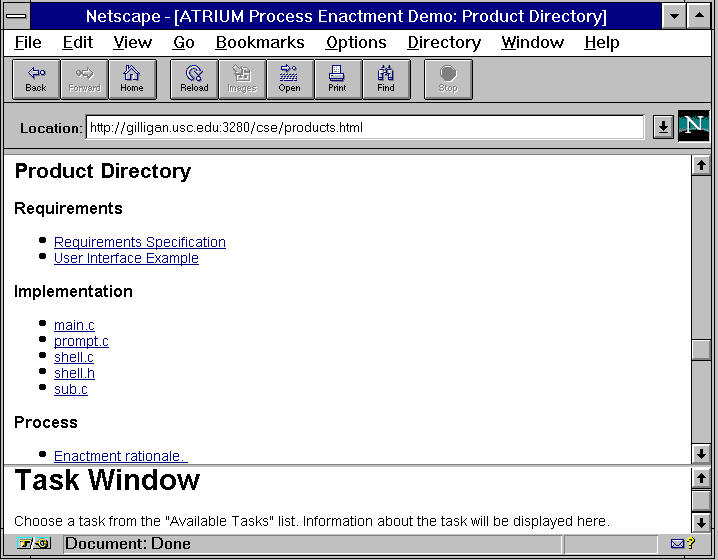
Using this process prototyping technology, we could work with process users to iteratively and incrementally model their as-is or to-be processes. Subsequently, modeled processes could then be interactively traversed using a Web browser interface to the resulting process simulator. Process users, independent of the time or location of their access to the process model, could then provide feedback, refinement or evaluation of what they saw in the Web-based process simulator.
Simulators are successful in helping process users to learn about the operational sequences of problem-solving tasks that constitute a software process [cf. KG95, GG+97]. Flight simulators have already demonstrated this same result many times over with flight operations process users (aircraft pilots). Process walkthrough simulators can identify potential patterns of software process user behavior, as well as potential performance or workflow bottlenecks in their use. This information in turn can help to identify parameter values for a discrete-event simulation of the same process. However, this has not yet been attempted.
Overall, discrete-event and knowledge-based simulation systems, together with process walkthrough simulators, constitute a learning, knowledge sharing, measurement and experimentation environment that can support and empower process users when redesigning their software processes [cf. BMR94, KG95, GG+97]. Therefore, these process simulation capabilities, together with other organizational change management techniques, should help minimize the risk of failure when redesigning software processes used in complex organizational settings.
5. Discussion
Given the introduction to the subject of SPR, explanation of what it is, explanation of how software process modeling, analysis and simulation fit it, and demonstrated how it can operate through examples, there is still more work to be done. Thus, the purpose of this discussion is to identify some of the future needs that have become apparent from this investigation.
First, whether dealing with a real software process in a real-world setting, or when browsing one found on the Web, capturing, formalizing or otherwise modeling as-is processes is cumbersome. Part of the problem at hand is that most organizations lack explicit, well-defined or well-managed processes as the starting point for an SPR effort. Consequently, attention is often directed to focus only on creation of to-be alternatives, without establishing an as-is baseline. Without a baseline, SPR efforts will increase their likelihood of failure [BMR94, DS90, GK95, HRW93]. Thus, there is need for new ways and means for the rapid capture and codification of as-is software processes to facilitate SPR.
Second, there is need for rapid generation of to-be and here-to-there processes and models. SPR heuristics, as well as the tools and techniques for acquiring and applying them appear to have significant face value. They can help to more rapidly produce to-be process alternatives. However, knowledge for how to construct or enact the here-to-there transformation process in a way that incorporates change management techniques and process management tools is an open problem. Further study is needed here.
Third, SPR heuristics or transformation taxonomies may serve as a foundation for developing a theoretical framework for how to best represent SPR knowledge. Similarly, such a framework should stipulate what kinds of software process concepts, links and instances should be represented, modeled and analyzed to facilitate SPR. Nonetheless, there is also a practical need to design and tailor SPR taxonomies to specific software process domains and organizational settings. At this point, it is unclear whether heuristics for redesigning software use processes are equally applicable to software acquisition, development or evolution processes. The same can be said for any other combination of these types of software processes.
Fourth, in the preceding section, software tools supporting the modeling, analysis and simulation of software processes for redesign were introduced. However, these tools were not developed from the start as a single, integrated environment. Thus their capabilities can be demonstrated to help elucidate what is possible. But what is possible is not practical for widespread deployment or production usage. Thus, there is a need for new environments that support the modeling, analysis and simulation of software processes that can be redesigned, life cycle engineered [SM97], and continuously improved from knowledge automatically captured from the Web.
Last, as highlighted in the results from BPR research studies, and from first-hand experience [SN97], process users need to be involved in redesigning their own processes. Accordingly, the temptation to seek fully automated approaches to generating alternative to-be process designs from the analysis of an as-is process model must be mitigated. The question here is to understand when or if fully automated SPR is desirable, and in what kinds of organizational settings. For example, there can be SPR situations where automated redesign may not be a suitable goal or outcome. This is in organizational settings where process users seek empowerment and involvement in redesigning and controlling their process structures and workflow. In settings such as these, the ability to access, search/query, select and evaluate possible process redesign alternatives through a through the system capabilities described above may be more desirable [cf. SN97]. Thus the ultimate purpose of support environment for SPR may be in supporting and empowering process users to direct the redesign of their processes, rather than in automating SPR.
Beyond this, one of the goals of SPR should be to minimize the risk of a failed SPR effort. Solutions that focus exclusively on development technology-driven or technology-only approaches to SPR seemed doomed to fail. Thus, there remains a challenge for those that choose the technology path to SPR to effectively demonstrate how such an approach can succeed, in what kinds of organizational settings, and with what kinds of skilled process participants.
6. Conclusions
This paper addresses three research questions that identify and describe what software process redesign is, how software process modeling and simulation fit in, and what an approach to SPR might look like. SPR is proposed as a technique for achieving radical, order-of-magnitude improvements or reductions in software process attributes. SPR builds on empirical and theoretical results in the area of business process reengineering. However, it also builds on knowledge that can be gathered from the Web. Though the quality of such knowledge is more variable, the sources from which it is derived--experience reports, case studies, lessons learned, best practices and similar narratives--can be formally represented, hyperlinked and browsed during subsequent use or reuse. A central result from the knowledge collected so far is that SPR must combine its focus to both techniques for changing the organization where software processes are to be redesigned, as well as for identifying how software engineering and information technology-based process management tools and concepts can be applied.
Software process modeling, analysis, and simulation technology can be successfully employed to support SPR. In particular, knowledge-based tools, techniques and concepts appear to offer a promising avenue for exploration and application in this regard. However, new process modeling, analysis and simulation challenges have been also identified. These give rise to the need to investigate new tools and techniques for capturing, representing and utilizing new forms of process knowledge. Knowledge such as SPR heuristics can play a central role in rapidly identifying process redesign alternatives. Software process simulation techniques in particular may require support for person-driven process simulations, which enable process users to observe, walk-through or fly-through process redesign alternatives. Finally, software process modeling, analysis and simulation capabilities that support SPR activities, may be deployed so as to engage and facilitate the needs of users who share processes across multiple organizational settings, using mechanisms that can be deployed on the Web.
Last, an approach to SPR that utilizes Web-based tools for software process modeling, analysis, and person-driven simulation has been presented. Initial experiences in using these tools, together with the business process reengineering and change management techniques they embody, indicates that the objective of order-of-magnitude reductions in software process cycle time and process steps can be demonstrated and achieved in complex organizational settings. Whether results such as these can be replicated in all classes of software processes--acquisition, development, usage, and evolution--remains the subject of further investigation. Similarly, other research problems have been identified for how or where advances in software process modeling and simulation can lead to further experimental studies and theoretical developments in the art and practice of software process redesign.
Acknowledgements
The research described in this paper benefit from collaborations with the following people. Andre Valente at the USC Information Sciences Institute developed the modeling and analysis system prototype with Loom and Ontosaurus displayed in Figures 1 and 2. John Noll, now at the Computer Science Dept., University of Colorado at Denver, developed the modeling and process simulation walkthrough intranet shown in Figures 4 and 5. The process measurement technique and rule-based formulation used for automated process redesign analysis was first developed by Mark Nissen, now at the Systems Management Dept., Naval Postgraduate School, Monterey, CA. All of these contributions are gratefully acknowledged.
References
[APL95] J.D. Ahrens, N. Prywes and E. Lock. Software Process Reengineering: Toward a New Generation of CASE Technology, J. Systems and Software, 30(1):71-84, 1995.
[BMR94] B.J. Bashein, M.L. Markus and P. Riley. Preconditions for BPR Success: And How to Prevent Failures. Information Systems Management, 11(2):7-13, Spring 1994.
[CJS94] J.R. Caron, S.L. Jarvenpaa and D.B. Stoddard. Business Reengineering at CIGNA Corporation: Experiences and Lessons Learned From the First Five Years. MIS Quarterly, 18(3):233-250, September, 1994.
[DP98] T.H. Davenport and L. Prusak. Working Knowledge: How Organizations Manage What They Know. Harvard Business School Press, Boston, MA, 1998.
[DS90] T.H. Davenport and J.E. Short. The New Industrial Engineering: Information Technology and Business Process Redesign. Sloan Management Review, 34(4):1-27, 1990.
[ESS95] M.J. Earl, J.L. Sampler, and J.E. Short. Strategies for Business Process Reengineering: Evidence from Field Studies, J. Management Information Systems, 12(1):31-56, 1995.
[GJ+95] V. Grover, S.R. Jeong, W.J. Kettinger and S. Wang. The Implementation of Business Process Reengineering. J. Management Information Systems, 12(1):104-144. 1995.
[GG+97] S. Guha, V. Grover, W.J. Kittenger and J.T.C. Teng. Business Process Change and Organizational Performance: Exploring an Antecedent Model. J. Management Information Systems, 14(1):119-154, 1997.
[HRW93] G. Hall, J. Rosenthal and J. Wade. How to Make Reengineering Really Work. Harvard Business Review, 119-131, November-December 1993.
[H90] M. Hammer. Reengineering Work: Don't Automate, Obliterate. Harvard Business Review. 68(4):104-112, July-August 1990.
[JW+97] B.D. Janz, J.C. Wetherbe, G.B. Davis, R.A. Noe. Reengineering the Systems Development Process: The Link between Autonomous Teams and Business Process Outcomes, J. Management Information Systems, 14(1): 41-68, 1997.
[KG95] W.J. Kettinger and V. Grover. Special Section: Toward a Theory of Business Process Change Management, J. Management Information Systems, 12(1):9-30, 1995.
[KS82] R. Kling and W. Scacchi. The Web of Computing: Computer Technology as Social Organization. in A. Yovits (ed.), Advances in Computers, 21:3-90, 1982.
[KS96] S. Ku, Y.-H. Suh, and G. Tecuci. Building an Intelligent Business Process Reengineering System: A Case-Based Approach. Intelligent Systems in Accounting, Finance, and Management, 5(1):25-39, 1996.
[MB95] R. MacGregor and R. Bates, Inside the Loom description classifier. SIGART Bulletin 2(3):88-92, 1995.
[MS90] P. Mi and W. Scacchi. A Knowledge-based Environment for Modeling and Simulating Software Engineering Processes, IEEE Trans. Knowledge and Data Engineering, 2(3): 283-294, 1990. Also appears in Nikkei Artificial Intelligence, 20(1): 176-191, 1991 (in Japanese).
[MS96] P. Mi and W. Scacchi. A Meta-Model for Formulating Knowledge-Based Models of Software Development. Decision Support Systems, 17(3):313-330. 1996.
[N97] M.E. Nissen. Reengineering the RFP Process through Knowledge-Based Systems. Acquisition Review Quarterly, 4(1):87-100, 1997.
[N98] M.E. Nissen. Redesigning Reengineering through Measurement-Driven Inference. MIS Quarterly, 22(4): 509-534, December, 1998.
[NS99] J. Noll and W. Scacchi. Supporting Software Development Projects in Virtual Enterprises. Journal of Digital Information, 1(4), February 1999.
[O98] D.E. O'Leary. Enterprise Knowledge Management. Computer, 31(3):54-61, 1998.
[ON99] Ontosaurus Web Browser home page. http://www.isi.edu/isd/ontosaurus.html
[P98] Proceedings ProSim'98 Workshop on Software Process Simulation Modeling, Silver Falls, OR, June 1998.
[S98] W. Scacchi. Modeling, Simulating, and Enacting Complex Organizational Processes: A Life Cycle Approach, in M. Prietula, K. Carley, and L. Gasser (eds.), Simulating Organizations: Computational Models of Institutions and Groups, AAAI Press/MIT Press, Menlo Park, CA, 153-168, (1998).
[S99] W. Scacchi. Experiences with Software Process Simulation and Modeling, J. Systems and Software, 46(2): 183-192, 1999.
[SB98] W. Scacchi and B.E. Boehm. Virtual System Acquisition: Approach and Transitions, Acquisition Review Quarterly, 5(2):185-216, Spring 1998.
[SM97] W. Scacchi and P. Mi. Process Life Cycle Engineering: A Knowledge-Based Approach and Environment. Intelligent Systems in Accounting, Finance, and Management, 6:83-107, 1997.
[SN97] W. Scacchi and J. Noll, Process-Driven Intranets: Life Cycle Support for Process Reengineering, IEEE Internet Computing, 1(5):42-49, September 1997.
[SN97a] S.K. Sia and B.S. Neo. Reengineering Effectiveness and the Redesign of Organizational Control: A Case Study of the Inland Revenue Authority of Singapore. J. Management Information Systems, 14(1):69-92, Spring 1997.
[VR+99] A. Valente, T. Russ, R. MacGregor, and W. Swartout. Building and (Re)Using an Ontology for Air Campaign Planning. IEEE Intelligent Systems, 14(1):27-36, 1999.
[VS99] A. Valente and W. Scacchi. Developing a Knowledge Web for Business Process Redesign, IJCAI-99 Workshop on Workflow and Process Management, August 1999.
[ZW98] M. Zelkowitz and D.R. Wallace. Experimental Models for Validating Technology. Computer, 31(5), 23-3 1, May 1998.