International J. Computational Geometry & Applications
The expected extremes in a Delaunay triangulation.
M. Bern,
D. Eppstein, and F. Yao.
18th Int. Coll. Automata, Languages and Programming,
Madrid, Spain, 1991.
Springer, Lecture Notes in Comp. Sci. 510, 1991, 674–685,
doi:10.1007/3-540-54233-7_173.
Int. J. Comp. Geom. & Appl.
1 (1): 79–92, 1991,
doi:10.1142/S0218195991000074.
Discusses the expected behavior of Delaunay triangulations for points chosen uniformly at random (without edge effects). The main result is that within a region containing \(n\) points, the expected maximum degree is \(O(\log n / \log\log n)\).
Polynomial-size non-obtuse triangulation of polygons.
M. Bern
and D. Eppstein.
7th ACM Symp. Comp. Geom., North Conway, New Hampshire, 1991, pp. 342–350,
doi:10.1145/109648.109686
Int. J. Comp. Geom. & Appl. 2 (3): 241–255, 1992,
doi:10.1142/S0218195992000159
(special issue for 7th Symp. Comput. Geom.).
Erratum, Int. J. Comp. Geom. & Appl. 2 (4): 449–450, 1992,
doi:10.1142/S0218195992000305.
Any simple polygon can be triangulated with quadratically many nonobtuse triangles. Mostly subsumed by recent results of Bern et al described in "Faster circle packing".
Tree-weighted neighbors and geometric \(k\) smallest spanning trees.
D. Eppstein.
Tech. Rep. 92-77, ICS, UCI, 1992.
Int. J. Comp. Geom. & Appl. 4: 229–238, 1994,
doi:10.1142/S0218195994000136.
"Finding the \(k\) smallest spanning trees" used higher order Voronoi diagrams to reduce the geometric \(k\) smallest spanning tree problem to the graph problem. Here I instead use nearest neighbors for a modified distance function where the bottleneck shortest path length is subtracted from the true distance between points. The result improves the planar time bounds and extends more easily to higher dimensions.
Triangulating polygons without large angles.
M. Bern,
D. Dobkin,
and D. Eppstein.
8th ACM Symp. Comp. Geom., Berlin, 1992, pp. 222–231,
doi:10.1145/142675.142722.
Int. J. Comp. Geom. & Appl. 5: 171–192, 1995,
doi:10.1142/S0218195995000106
(special issue for 8th Symp. Comput. Geom.)
Follows up "Polynomial size non-obtuse triangulation of polygons"; improves the number of triangles by relaxing the requirements on their angles. Again mostly subsumed by results of Bern et al described in "Faster circle packing".
Faster circle packing with application to nonobtuse triangulation.
D. Eppstein.
Tech. Rep. 94-33, ICS, UCI 1994.
Int. J. Comp. Geom. & Appl. 7 (5): 485–491, 1997,
doi:10.1142/S0218195997000296.
Speeds up a triangulation algorithm of Bern et al. ["Linear-Size Nonobtuse Triangulation of Polygons"] by finding a collection of disjoint circles which connect up the holes in a non-simple polygon. The method is to use a minimum spanning tree to find a collection of overlapping circles, then shrink them one by one to reduce the number of overlaps, using Sleator and Tarjan's dynamic tree data structure to keep track of the connectivity of the shrunken circles.
Approximating center points with iterated Radon points.
K. Clarkson, D. Eppstein,
G.L. Miller,
C. Sturtivant, and
S.-H. Teng.
9th ACM Symp. Comp. Geom., San Diego, 1993, pp. 91–98,
doi:10.1145/160985.161004.
Int. J. Comp. Geom. & Appl. 6 (3): 357–377, 1996,
doi:10.1142/S021819599600023X.
Given a collection of n sites, a center point is a point (not necessarily a site) such that no hyperplane through the centerpoint partitions the collection into a very small and a very large subset. Center points have been used by Teng and others as a key step in the construction of geometric separators. One can find a point with this property by choosing a random sample of the collection and applying linear programming, but the complexity of that method grows exponentially with the dimension. This paper proposes an alternate method that produces lower quality approximations (in terms of the size of the worst hyperplane partition) but takes time polynomial in both n and d.
Parallel construction of quadtrees and quality triangulations.
M. Bern,
D. Eppstein, and
S.-H. Teng.
3rd Worksh. Algorithms and Data
Structures, Montreal, 1993,
doi:10.1007/3-540-57155-8_247.
Springer, Lecture Notes in
Comp. Sci. 709, 1993, pp. 188–199.
Tech. Rep. 614, MIT Lab. for Comp. Sci., 1994.
Int. J. Comp. Geom. & Appl.
9 (6): 517–532, 1999,
doi:10.1142/S0218195999000303.
A parallelization of the quadtree constructions in "Provably good mesh generation", in an integer model of computation, based on a technique of sorting the input points using values formed by shuffling the binary representations of the coordinates. A side-effect is an efficient construction for the "fair split tree" hierarchical clustering method used by Callahan and Kosaraju for various nearest neighbor problems.
Quadrilateral meshing by circle packing.
M. Bern
and D. Eppstein.
2nd CGC
Worksh. Computational Geometry, Durham, North Carolina, 1997.
6th Int. Meshing Roundtable, Park
City, Utah, 1997, pp. 7–19.
arXiv:cs.CG/9908016.
Int. J. Comp. Geom. & Appl. 10 (4): 347–360, 2000,
doi:10.1142/S0218195900000206.
We use circle-packing methods to generate quadrilateral meshes for polygonal domains, with guaranteed bounds both on the quality and the number of elements. We show that these methods can generate meshes of several types:
The elements form the cells of a Voronoi diagram,
The elements each have two opposite 90 degree angles,
All elements are kites, or
All angles are at most 120 degrees.
In each case the total number of elements is \(O(n)\). The 120-degree bound is optimal; if a simply-connected region has all angles at least 120 degrees, any mesh of that region has a 120 degree angle.
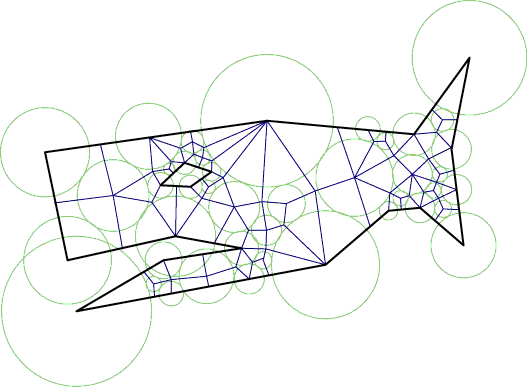
The skip quadtree: a simple dynamic data structure
for multidimensional data.
D. Eppstein,
M. T. Goodrich,
and
J. Z. Sun.
21st ACM Symp. Comp. Geom., Pisa, 2005, pp. 296–305,
doi:10.1145/1064092.1064138.
arXiv:cs.CG/0507049.
Int. J. Comp. Geom. & Appl. 18(1-2): 131–160, 2008,
doi:10.1142/S0218195908002568.
We describe a data structure consisting of a sequence of compressed quadtrees for successively sparser samples of an input point set, with connections between the same squares in successive members of the sequence. Using this structure, we can insert or delete points and answer approximate range queries and approximate nearest neighbor queries in O(log n) time per operation.
Improved grid map layout by point set matching.
D. Eppstein,
M. van Kreveld,
B. Speckmann, and
F. Staals.
28th European Workshop on Computational Geometry (EuroCG'12), Assisi,
Italy, 2012.
6th IEEE Pacific Visualization Conf. (PacificVis), Sydney, Australia, 2013,
doi:10.1109/PacificVis.2013.6596124.
Int. J. Comput. Geom. Appl. 25 (2): 101–122, 2015, doi:10.1142/S0218195915500077.
We study the problem of matching geographic regions to points in a regular grid, minimizing the distance between each region's centroid and the corresponding grid point, and preserving as much as possible the relative orientations between pairs of regions.
Folding polyominoes into (poly)cubes.
O. Aichholzer,
M. Biro,
E. Demaine,
M. Demaine,
D. Eppstein,
S. P. Fekete,
A. Hesterberg,
I. Kostitsyna, and
C. Schmidt.
27th Canadian Conference on Computational Geometry, Kingston, Ontario,
Canada, 2015, pp. 101–106.
arXiv:1712.09317.
Int. J. Comp. Geom. &
Appl. 28 (3): 197–226, 2018, doi:10.1142/S0218195918500048.
We classify the polyominoes that can be folded to form the surface of a cube or polycube, in multiple different folding models that incorporate the type of fold (mountain or valley), the location of a fold (edges of the polycube only, or elsewhere such as along diagonals), and whether the folded polyomino is allowed to pass through the interior of the polycube or must stay on its surface.