Execute a query using ranked retrieval
- Goals:
- To teach you how to use the crawl and posting list to answer a user's query.
- Groups: This can be done in groups of 1, 2 or 3.
- Reusing code: This assignment will probably build on code you have previously written. You may only use code that someone in your group has written. Use code found over the Internet at your own peril -- it may not do exactly what the assignment requests. If you do end up using code you find on the Internet, you must disclose the origin of the code. Concealing the origin of a piece of code is plagiarism.
- Discussion: Use the Message Board for general questions whose answers can benefit you and everyone.
- Write a program to answer a query:
- There are two versions to this assignment. You can either do the baseline assignment (V1), or you can do the show-me-what-you-got assignment (V2). The first max out as 100/100 points, the second will be out at 110/100 points.
- V1
- Input: A posting list generated from the /user/common/large data set. You may use your own, or you may use one that is provided after the late due date for Task 30 has passed.
- Program: Use the algorithm from p 17 of Lecture 12's notes to calculate the most relevant documents for a given query. Do not implement the normalization from lines 9 and 10.
- Evaluation: Each person (even
if you are in a group) will take a
EEE
quiz which will ask 15 questions
of the form:
- What is the {first...fifth}-most relevant document (by id number) for the query X and what is it's relevance score?
- V2
- Input: A posting list generated from the /user/common/very_large data set (the whole crawl). Another index which maps documents to document ids. A final index which maps documents to terms. These will be provided to you.
- Program: Use the algorithm from p 17 of Lecture 12's notes to calculate the most relevant documents for a given query. Implement the normalization.
- Evaluation: Each person (even
if you are in a group) will take a EEE
quiz which will ask 10 questions
of the form:
- What is the {first...fifth}-most relevant document (by url) for the query X and what is it's relevance score?
- Guides: V1
- The posting list can be found here
Here is a screen shot of my output
This screen shot was updated on 3/15/14 at 9:30am to correct a bug in our code
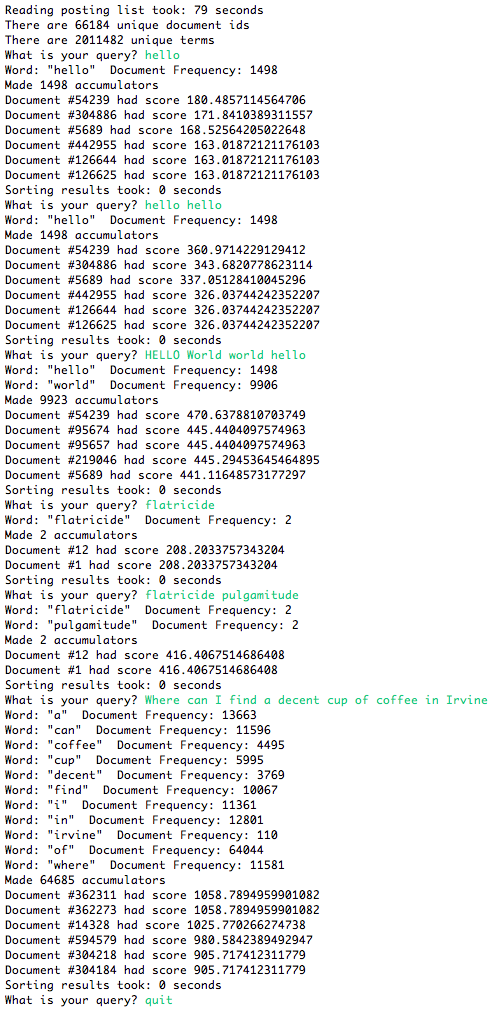
- To get these numbers I used log2. Getting the exact numbers correct is important.
- I used page 14 of these notes for the formula reference. Remember that the query counts as a document and will bump up your corpus size and document frequency by one
- Use the algorithm from p 17 of Lecture 12's notes to to make the accumulators
- Guides: V2
- In order to get the posting list, you need to install BitTorrent Sync, create a folder on your local hard drive, then tell BitTorrent Sync to sync that folder using the key "BIHOELFM4N53EQMSV23VZF2NLAUVW2O25". The very large posting list is currently there at about 2GB compressed. I'll add the other files as they are available. BitTorrent Sync is like Dropbox, but private.
- Evaluation:
- Correctness: Did you get the right answer?
- Due date: 03/21 11:59pm No late credit
- This is an assigment grade