Research Section
I have a background in both embedded systems (my academic life) and storage systems (my industrial life). I had the chance to collaborate with some extremely bright minds in both academia from various universities as well as industry (primarily my fellow IBMers at Almaden Research Center and Tucson).
Research Interests:
- Virtualization Support for Multi- and Many-core Platforms
- Variation-aware Software
- Embedded System Reliability
- Low Power Embedded System Design
- Embedded System Security - Multi-level Security
- Software/Hardware Application Mapping/Scheduling for Embedded Systems
- Compiler Optimizations With Focus on Parallelization, Security and Reliability
- Caching Algorithms for Embedded and Storage Systems
- Storage Management
PHiLOSoftware: A Low Power, High Performance, Reliable, and Secure Virtualization Layer for On-Chip Software-Controlled Memories
(SLIDES), (THESIS), (Download Framework)
To cope with the computational and memory requirements of emerging mobile software stacks, designers are deploying single-chip multi-core platforms with distributed on-chip memories (e.g., Caches and/or ScratchPad Memories). In order to pack more cores-per-die, designers are relying on aggressive technology scaling, trading off power, performance, and scalability for an alarming increase in process variations that result in high variations in power consumption and operating frequencies, as well as higher probabilities of failure. To increase system performance, designers are opting to deploy a variety of communication fabrics (e.g., buses, networks on chip) at the cost of variation in access latencies to the on-chip memory resources. Finally, to mitigate the growing leakage power in SRAM-based memories, designers are deploying emerging memory technologies as viable alternatives, which in turn have different characteristics and require more complex memory allocation policies. In this context, the exploration, design, and implementation of the memory subsystem in these platforms faces two main challenges: 1) Scalability -- the increasing memory demands of the software stack requires smart memory allocation decisions to maximize system performance and minimize power consumption. 2) Physical characteristic variation -- software needs to address and opportunistically exploit the inherent process and technological variations in the underlying system to maximize system performance and minimize power consumption. This project introduces PHiLOSoftware, a Low Power, High Performance, Reliable, and Secure Virtualization Layer for On-Chip Software-Controlled Memories. PHiLOSoftware allows designers to build memory allocation policies to efficiently manage the distributed on-chip memory resources at a high level. Key technical contributions of this project are: (1) We introduce a virtualization layer to transparently manage the available memory resources, abstracting any physical characteristics of the device from the programmer, while minimizing changes to the programming model, (2) We exploit memory virtualization for trusted environment generation through security-aware scheduling and memory allocation, (3) We introduce the notion of Embedded RAIDs-on-Chip, which allow programmers to define high-level variation-aware policies to manage their data, and enforced at run-time by our variation-aware virtual memory manager, (4) We define a new metric, emph{volatility analysis}, to derive efficient dynamic memory allocation decisions of hybrid-memory space with support of our hybrid-memory aware virtual memory manager, (5) We propose the concept of the SPMCloud, which is a highly-scalable memory subsystem built on the notion of distributed virtualized memory resources to support future generations of single-chip cloud computers, and (6) We propose the concept of virtual memory address spaces with different guarantees/characteristics (e.g., low-power, fault-tolerant, secure, etc.). The novelty of our approach lies in the deployment of a light-weight memory virtualization layer for distributed on-chip memories to allow programmers and compilers to build power, performance, reliability, and security-aware memory allocation policies that opportunistically exploit the device characteristics (e.g., communication fabric, memory technology, etc.) and process variations (access latencies, low power) of the underlying platform at the system level through virtualized address spaces.
CAM: Constraint-aware Application Mapping on Multiprocessor Systems (SLIDES)
The increasing demand for low power, high performance, reliable, and secure multimedia embedded systems has motivated the need for effective solutions to satisfy application bandwidth and latency requirements under a tight power budget. As technology scales and new techniques such as aggressive voltage scaling are utilized in the design of embedded systems it is imperative that applications are optimized to take full advantage of the underlying resources and meet power, performance, and reliability requirements. Moreover, as these devices become more complex and their connectivity to the world-wide-web is constantly increasing their vulnerabilities to malicious software increase.
CAM is a framework for constraint-aware application mapping on embedded systems.
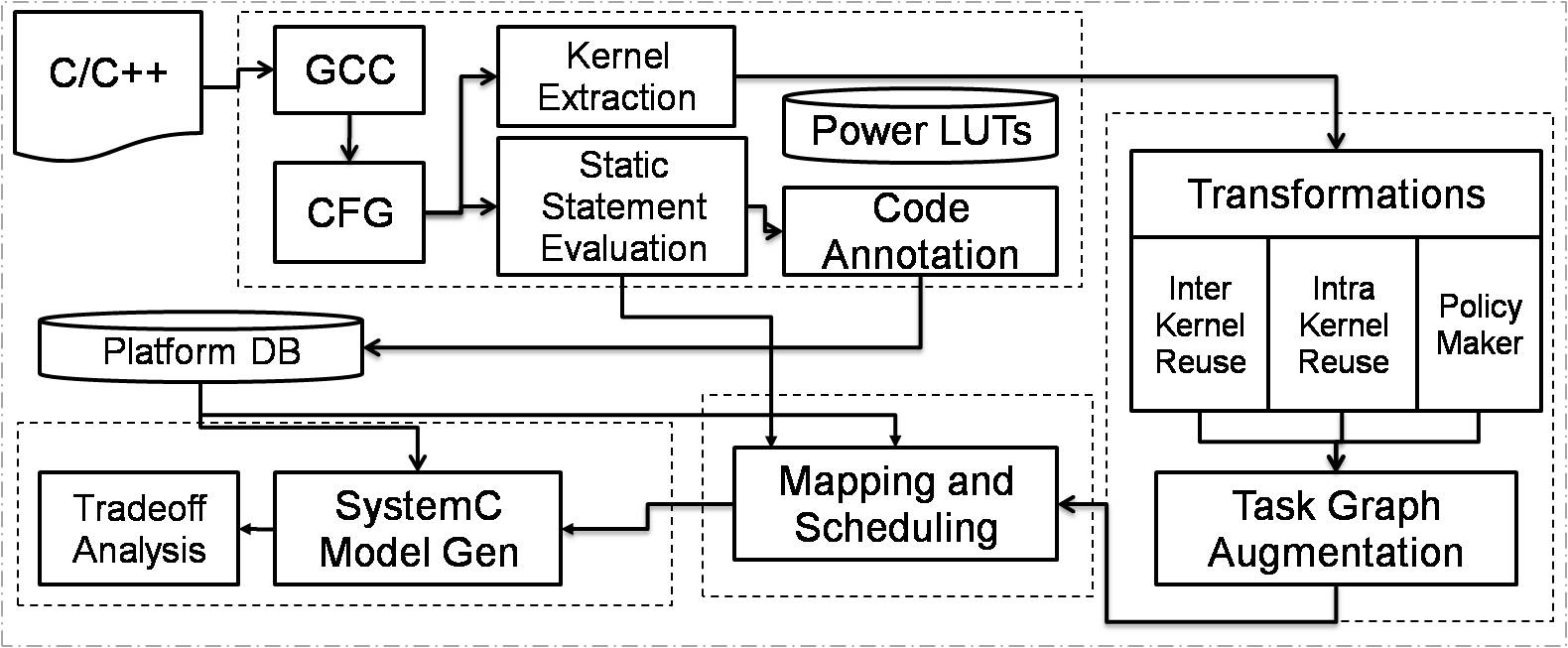
Figure 1 shows CAM’s block diagram. Given a series of constraints, a mixture of power, performance, security, reliability, and temperature, CAM will take an application and try to map it onto the desired embedded system. Currently CAM supports a wide spectrum of platforms, ranging from simple chip-multiprocessors, to dedicated hardware models. CAM consists of four main parts. The first is the front end which extracts all the necessary information from the application and generates the input models to our framework. The second part is the transformations and analysis engine which is responsible for applying different source code level optimizations to increase the application’s parallelism and determine data reuse opportunities as well as generate an augmented task graph which has been annotated with different application information which will be used by our scheduler. The next part is the mapping and scheduling heuristics which will take the augmented task graph and given the set of constraints, it will optimize the scheduling and mapping for the given platform. Finally, the back end consists of a model generation which will take the application’s code and generate performance models which are then plugged into CAM’s SystemC modeling engine.
Reliable and Secure Memory Systems for Future Data-Center-on-a-Chip Platforms
The dual effects of larger die sizes and technology scaling, combined with aggressive voltage scaling for power reduction, increase the error rates for on-chip memories. Traditional on-chip memory reliability techniques (e.g., ECC) incur significant power and performance overheads. In this paper, we propose a low-power-and-performance-overhead Embedded RAID (E-RAID) strategy and present Embedded RAIDs-on-Chip (E-RoC), a distributed dynamically managed reliable memory subsystem for bus-based Chip-Multiprocessors. E-RoC achieves reliability through redundancy by optimizing RAID-like policies tuned for on-chip distributed memories. We achieve on-chip reliability of memories through the use of Distributed Dynamic ScratchPad Allocatable Memories (DSPAMs) and their allocation policies. We exploit aggressive voltage scaling to reduce power consumption overheads due to parallel DSPAM accesses, and rely on the E-RoC manager to automatically handle any resulting voltage-scaling-induced errors. We demonstrate how E-RAIDs can further enhance the fault tolerance of traditional memory reliability approaches by designing E-RAID levels that exploit ECC. Finally, we show the power and flexibility of the E-RoC concept by showing the benefits of having a heterogeneous E-RAID levels that fit each application's needs (fault tolerance, power/energy, performance). Our experimental results on CHStone/Mediabench II benchmarks show that our E-RAID levels converge to 100%Yield much faster than traditional ECC approaches. Moreover, E-RAID levels that exploit ECC can guarantee 99.9%Yield at ultra low Vdd on average, where as traditional ECC approaches were able to attain at most 99.1%Yield. We observe an average of 22%dynamic power consumption increase by using traditional ECC approaches, where as our E-RAID schemes are able to save power consumption an average of 27%, while incurring worst-case 2% higher performance overheads than traditional ECC approaches. By voltage scaling the memories, we see that traditional ECC approaches are able to save static energy by 6.4%(average), where as our E-RAID approaches achieve 23.4%static energy savings (average). Finally, we observe that mixing E-RAID levels allows us to further reduce the dynamic power consumption by up to 150% at the cost of an average 5%increase in execution time over traditional approaches.
Our current efforts at providing reliable memory systems have led us to the invention of Embedded RAIDs-on-Chip (E-RoC) Technology. We have taken the E-RoC technology a step further and applied its concepts to highly scalable NoC platforms, leading us to developing a massively scalable and highly reliable on-chip memory subsystem manager (Currently being filed for disclosure). We also have other ongoing efforts that deal with the concept of critical data mapping onto hetereogeneous memory subsystems.
On-Chip Memory Virtualization
Emerging multicore platforms are increasingly deploying dis- tributed scratchpad memories to achieve lower energy and area together with higher predictability; but this requires transparent and efficient software management of these criti- cal resources. In this paper, we introduce SPMVisor, a hard- ware/software layer that virtualizes the scratchpad mem- ory space in order to facilitate the use of distributed SPMs in an efficient, transparent and secure manner. We intro- duce the notion of virtual scratchpad memories (vSPMs), which can be dynamically created and managed as regu- lar SPMs. To protect the on-chip memory space, the SP- MVisor supports vSPM-level and block-level access control lists. In order to efficiently manage the on-chip real-estate, our SPMVisor supports policy-driven allocation strategies based on privilege levels. Our experimental results on Me- diabench/CHStone benchmarks running on various Chip- Multiprocessor configurations and software stacks (RTOS, virtualization, secure execution) show that SPMVisor en- hances performance by 71% on average and reduces power consumption by 79% on average.
Trusted Environment Generation(SLIDES)
Secure software execution on chip-multiprocessor platforms is compromised by threats such as software-based side channel attacks that expose information from shared memory. The increasing amount of shared (memory or computational) resources on emerging chip-multiprocessors further exacerbates security threats, highlighting the need for secure policies to manage on-chip resources. We present PoliMakE, a methodology that enables exploration and generation of customized policies to guarantee secure software execution on a chip-multiprocessor system in the presence of software-based side channel attacks. PoliMakE analyzes an application's security needs and generates a series of custom policies that dictate how to safely execute tasks and efficiently manage the computational, communication, and memory resources. Our experimental results on DRM, JPEG as well as some synthetic applications show that PoliMakE enables secure software execution with minimal performance overhead, while reducing power consumption, since the policies are customized to efficiently utilize the available on-chip resources. For the case study of running DRM in secure mode concurrently with JPEG encoding, we are able to observe 61% performance improvement when compared to standard approaches. Our policy generation engine is able to generate policies in only a matter of minutes for secure applications with hundreds of tasks. Unsecure applications were observed to resume execution up to 99% faster than with the traditional halt approach.
iCostale: Adaptive Cost Optimization for Storage Clouds (IBM-Storage)
The unprecedented volume of data generated by contemporary business users and consumers has created enor- mous data storage and management challenges. In order to control data storage cost, many users are moving their data to online storage clouds, and applying capacity usage reducing data transformation techniques like de-duplication, compression, and transcoding. These give rise to several challenges, such as which cloud to choose, and what data transformation techniques to apply for optimizing cost. This paper presents an integrated storage service called iCostale that reduces the overall cost of data storage through automatic selection and placement of users data into one of many storage clouds. Further, it intelligently transforms data based on its type, access frequency, transformation overhead, and the cost model of the storage cloud providers. We demonstrate the efficacy of iCostale through a series of micro- and application- level benchmarks. Our experimental results show that, through intelligent data placement and transformation, iCostale can reduce overall cost of data storage by more than 50%.
ParaDisE: parallel discovery engine for enterprise datacenters (IBM-Storage)
Automatic discovery and monitoring of IT resources is a critical part of enterprise systems management. In addition to ascertaining internal device configurations, this discovery process may also need to capture the capabilities, usage, connectivity, availability, and other information related to various IT components. Systems resource management (SRM) tools typically implement this discovery process using device specific APIs, custom agents and/or some standard-based solution (like WBEM and CIM). The discovery actions need to be systematically planned; an inefficient implementation or scheduling may easily take from a few minutes to several hours to complete in a large heterogeneous enterprise datacenter. This paper discusses the various challenges associated in discovering a datacenter environment and presents an autonomic monitoring framework called 'ParaDisE' that builds upon well-known industry standards and reduces the overall discovery time by more than 50%.
Optimal Prefetching (IBM-Storage)
Prefetching is a widely used technique in modern data storage systems. We study the most widely used class of prefetching algorithms known as sequential prefetching. There are two problems that plague the state-of-the-art sequential prefetching algorithms: (i) cache pollution, which occurs when prefetched data replaces more useful prefetched or demand-paged data, and (ii) prefetch wastage, which happens when prefetched data is evicted from the cache before it can be used. A sequential prefetching algorithm can have a fixed or adaptive degree of prefetch and can be either synchronous (when it can prefetch only on a miss), or asynchronous (when it can also prefetch on a hit). To capture these distinctions we define four classes of prefetching algorithms: Fixed Synchronous (FS), Fixed Asynchronous (FA), Adaptive Synchronous (AS), and Adaptive Asynchronous (AsynchA). We find that the relatively unexplored class of AsynchA algorithms is in fact the most promising for sequential prefetching. We provide a first formal analysis of the criteria necessary for optimal throughput when using an AsynchA algorithm in a cache shared by multiple steady sequential streams. We then provide a simple implementation called AMP (Adaptive Multi-stream Prefetching), which adapts accordingly leading to near optimal performance for any kind of sequential workload and cache size.