
by COREY SCHANINGER and LAKSHMI THYAGARAJAN
Project report here. Demo site here.
This group put together a web interface and backend system that would search for a path between any two actors in IMDB. There are 1.5 million actors connected by 1.6 million movies. The key challenge of this project was to make queries fast for the user given the amount of paths. The current system doesn't calculate shortest path, but rather fastest path.
Future work includes a live updating of the search as it tries to find the shortest path, allowing the user to disallow certain connections and including other kinds of connections besides just being in a movie together.
Example: Nicolas Cage -> Amos & Andrew (1993) -> Jeff Blumenkrantz -> Anastasia (1997) -> Meg Ryan
Queries can take between 1 and and 183 seconds depending on the actor pair.
by Even Cheng and Karthik Raman
Project report here. GUI not deployed to the web.
Let's say that you happen to know multiple languages. Why should your search engine give you results in just one? Instead maybe it should give you the best results in any language that you happen to know? That's the premise of this project.
Tell the computer the languages that you know and it will translate your query into all of those languages and find the best results from it's different language specific indices all ranked together. The key challenges for this project were managing translations and developing rankings on different corpora that could be compared.
by Guangqiang Li and Ye Wang
Project report here. GUI not deployed to the web.
Real time search is hot! It's the thrill of the moment to find out what's trending in the twitter-sphere. But wait? Why do I want to know everyone's trending terms? This project was about figuring out what is hot among just your friends. This group applied PageRank to Twitter to create TwitterRank. The key challenge for this project was determining how to create a graph from tweets, then using that graph to identify trending terms.
by Nadine Amsel and Nathanael Lenart
Project report here. GUI not deployed to the web.
Why can't music visualizers be fully awesome? Well now they can with PhotoLyrics. Just upload your mp3 to the photolyrics server and it will be sliced and diced to give you back a slidehow of pictures based on the lyrics of the song. The key challenge for this project was similar to the TweetRank project. How do you determine what an important word is in the lyrics of a song? Well this project based it on it's tf-idf score from wikipedia.
The result is that when a user uploads "Eye of the Tiger", the system gets the info from the id3 tags in the file, gets the lyrics from the song from the web, determines which words are the most interesting and then shows a slideshow based on the interesting images.
Future enhancements include making this into a plug-in for iTunes
by Phitchayaphong Tantikul and Hye Jung Choi
Project report here. GUI located here.
Although there is a lot of code sharing that is going on on the web right now, how many people are actually search code search engines for things to cut and paste? I bet very few. So did the authors of this project who focussed on developers who are searching for code because they need a quick refresher on how to program with a particular data structure or need to remember how to connect to a socket. So this project is a search engine for code tutorials. The key challenge for this project was finding the pages that had both code and text in it, crawling it, parsing it, indexing it, and then presenting it to users in a clever way that showed both the code and a snippet talking about how to use it.
It's an information retrieval engine that I would use all the time!
by Xiaozhi Yu
Project report here. GUI not deployed to the web.
This project implemented a really well engineered implementation of PageRank for Hadoop. Some things that I learned from this project were how to iterate multiple MapReduce jobs from one uploaded jar, and I just appreciated the beauty of the way that the output file from one iteration was fed directly into the next iteration without any processing. Of course since this is on MapReduce this naturally scales to really large datasets.

by Minh Doan, Ching-wei Huang, Siripen Pongpaichet
Project report here. GUI not deployed to the web.
This project was another great use of MapReduce. Instead of finding the PageRank of the pages in wikipedia however, these authors using pagerank to find dense clusters: sets of pages with dense interconnections among them. This algorithm could be applied to any graph data structure, but on the web graph it will identify lots of self-referencing pages. This would be helpful for identifying clusters of link farms, spammers who are all linking to each other, or other unusual occurences in the graph. In the case of wikipedia it found collections of pages that were about the same thing. A set of pages about the mountains of France, and a set of pages describing the Federalist papers.
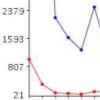
by Ali Bagherzandi and Kerim Yassin Oktay
Project report here. GUI located here. Video demo here.
This project took on the challenge of increasing the speed of our wikipedia search engine and also increasing the set of words which could be considered in the cosine ranking. The key challenge here was how to reduce the size of the posting list into something that could be quickly read from disk - as this was the main performance bottleneck. The answer was gamma coding which is a technique that stores small numbers with fewer bits than larger numbers. Normally integers have an assumed upper bound, INT_MAX, gamma_coding makes no such assumption and efficiently represents numbers that have no upper bound. By using gamma coding the posting list size was reduced and queries were much much faster.