All publications
Trees in TeX.
D. Eppstein.
TUGboat 6 (1): 31, 1985.
This note in the TeX user's group newsletter described a set of macros for drawing trees, using TeX's boxes-and-glue mechanisms to line up the nodes at each level of the tree.
(TeX source code – Nelson Beebe's TeX tree drawing bibliography)
A heuristic approach to program inversion.
D. Eppstein.
9th Int. Joint Conf. Artificial
Intelligence, Los Angeles, 1985, pp. 219–221.
Program transformation. Given a (lisp) program for an invertible function, how do we automatically find a program for the inverse function? Considers more general simultaneous inverses of multiple functions. The heuristic part involves type inference for finding conditionals to use in certain if statements.
On the \(\mathsf{NP}\)-completeness of cryptarithms.
D. Eppstein.
SIGACT News 18 (3): 38–40, 1987,
doi:10.1145/24658.24662.
A cryptarithm (also known as an alphametic) is a puzzle in which the digits of a mathematical formula (typically addition of two large numbers) are replaced by letters; the goal is to determine which letter stands for which digits. If arithmetic is done in a polynomially large radix, the problem becomes \(\mathsf{NP}\)-complete.
Speeding up dynamic programming.
D. Eppstein,
Z. Galil,
and
R. Giancarlo.
29th IEEE Symp. Foundations of
Comp. Sci., White Plains, New York, 1988, pp. 488–496,
doi:10.1109/SFCS.1988.21965.
Worksh. Algorithms for Molecular Genetics, Bethesda, Maryland,
1988.
Tech. Rep. CUCS-379-88, Computer Science Dept., Columbia University,
1988.
Appeared as "Efficient algorithms with applications to molecular
biology" in
Int. Advanced Workshop on Sequences, Positano, Italy, 1988.
Sequences: Combinatorics, Compression, Security, Transmission,
R. M. Capocelli, ed., Springer, 1990,
pp. 59–74,
doi:10.1007/978-1-4612-3352-7_5.
The FOCS and Positano versions of this paper merged my results on a dynamic program used for RNA secondary structure prediction, with Raffaele's on sequence comparison. The Bethesda talk and the TR version both used the longer title "Speeding up dynamic programming with application to the computation of RNA structure", and included only the RNA result, which used a mild convexity assumption on certain costs to save two orders of magnitude in total time. This work incited a boom in computational biology within the theory community that is still going strong. But the RNA results were quickly improved by a log factor [Aggarwal et al. at the same FOCS] and never made it into a journal paper.
Efficient algorithms for sequence analysis with concave and
convex gap costs.
D. Eppstein.
Ph.D. thesis, Columbia University, 1989.
Includes results from "Speeding up dynamic programming", "Sequence comparison with mixed convex and concave costs", and "Sparse dynamic programming".
Sequence comparison with mixed convex and concave
costs.
D. Eppstein.
Tech. Rep. CUCS-382-88, Computer Science Dept., Columbia University, 1988.
J. Algorithms 11 (1): 85–101, 1990,
doi:10.1016/0196-6774(90)90031-9.
Gives an algorithm for finding the minimum number of mutations needed to transform one input string into another, in a general model in which substrings may be inserted or deleted at a cost depending nonlinearly on the substring length. The time bound depends on the number of times the second derivative of the cost function changes sign.
Reset sequences for monotonic automata.
D. Eppstein.
15th Int. Coll. Automata, Languages and Programming,
Tampere, Finland, 1988.
Springer, Lecture Notes in Comp. Sci. 317, 1988, pp. 230–238,
doi:10.1007/3-540-19488-6_119.
SIAM J. Computing 19 (3): 500–510, 1990,
doi:10.1137/0219033.
Automata theory. A reset sequence for a DFA is an input such that, no matter which state the DFA starts in, it ends up after the input in a known state. These have been used by Natarajan and Goldberg for certain robot motion planning problems (in fact the conference version of this paper used the title "Reset sequences for finite automata with application to design of parts orienters"), and also in coding theory where they arise in the design of self-synchronizing codes. This paper considers DFAs in which the transition functions respect a given cyclic ordering of the states, and shows that their shortest reset sequences can be found quickly. It also considers parallel algorithms for the problem. There remains open a gap between n2 and n3 in the maximum length of reset sequences for general automata.
Parallel algorithmic techniques for combinatorial
computation.
D. Eppstein and
Z. Galil.
Ann. Rev. Comput. Sci. 3: 233–283, 1988.
Invited talk by Z. Galil,
16th Int. Coll. Automata, Languages and
Programming, Stresa, Italy, 1989.
Springer, Lecture Notes in Comp. Sci. 372, 1989,
pp. 304–318, doi:10.1007/BFb0035768.
This survey on parallel algorithms emphasized the use of basic subroutines such as prefix sums, Euler tours, ear decomposition, and matrix multiplication for solving more complicated graph problems.
Horizon theorems for lines and polygons.
M. Bern,
D. Eppstein,
P. Plassman,
and F. Yao.
Discrete and Computational Geometry:
Papers from the DIMACS Special Year,
J. Goodman, R. Pollack, and W. Steiger, eds.,
DIMACS Series in Discrete Mathematics and Theoretical Computer
Science 6, Amer. Math. Soc., 1991, 45–66.
The total complexity of the cells in a line arrangement that are cut by another line is at most \(15n/2\). The complexity of cells cut by a convex \(k\)-gon is \(O(n\alpha(n,k))\). The first bound is tight, but it remains open whether the second is, or whether only linear complexity is possible.
The expected extremes in a Delaunay triangulation.
M. Bern,
D. Eppstein, and F. Yao.
18th Int. Coll. Automata, Languages and Programming,
Madrid, Spain, 1991.
Springer, Lecture Notes in Comp. Sci. 510, 1991, 674–685,
doi:10.1007/3-540-54233-7_173.
Int. J. Comp. Geom. & Appl.
1 (1): 79–92, 1991,
doi:10.1142/S0218195991000074.
Discusses the expected behavior of Delaunay triangulations for points chosen uniformly at random (without edge effects). The main result is that within a region containing \(n\) points, the expected maximum degree is \(O(\log n / \log\log n)\).
Planar orientations with low out-degree and compaction of
adjacency matrices.
M. Chrobak and D. Eppstein.
Theor. Comp. Sci. 86 (2): 243–266, 1991,
doi:10.1016/0304-3975(91)90020-3.
Describes efficient sequential and parallel algorithms for orienting the edges of an undirected planar graph so that each vertex has few outgoing edges. From such an orientation one can test in constant time whether a given edge exists. One consequence is a parallel algorithm to list all subgraphs isomorphic to \(K_3\) or \(K_4\). More recently this paper has been cited for its applications to scheduling update operations in parallel finite element methods.
Equipartitions of graphs.
D. Eppstein,
J. Feigenbaum, and
C.L. Li.
Discrete Mathematics 91 (3): 239–248, 1991, doi:10.1016/0012-365X(90)90233-8.
Considers partitions of the vertices of a graph into equal subsets, with few pairs of subsets connected by edges. (Equivalently we view the graph as a subgraph of a product in which one factor is sparse.) A random graph construction shows that such a factorization does not always exist.
Fast optimal parallel algorithms for maximal matching in sparse graphs.
H. Asuri,
M. Dillencourt,
D. Eppstein,
G. Lueker,
and
M. Molodowitch.
Tech. Rep. 92-01, ICS, UCI, 1992.
We later discovered that the same results were published in a SPAA paper by Greg Shannon.
Sets of points with many halving lines.
D. Eppstein.
Tech. Rep. 92-86, ICS, UCI, 1992.
I used genetic algorithms to search for small configurations of points bisected by lines in many combinatorially distinct ways.
Finding minimum area \(k\)-gons.
D. Eppstein,
M. Overmars,
G. Rote, and
G. Woeginger.
Disc. Comp. Geom. 7 (1): 45–58, 1992,
doi:10.1007/BF02187823.
Uses dynamic programming to choose sets of \(k\) points optimizing various criteria on the quality of their convex hull (in particular area). The time complexity (cubic in \(n\)) was later improved to quadratic in my paper "New algorithms for minimum area \(k\)-gons", which however continues to use the same dynamic program as a subroutine.
Simultaneous strong separations of
probabilistic and unambiguous complexity classes.
D. Eppstein,
L. Hemachandra,
J. Tisdall,
and
B. Yener.
Int. Conf. Computing and Information, Toronto,
North-Holland, 1989, pp. 65–70.
Tech. Rep. 335, Dept. Comp. Sci., U. Rochester, 1990.
Mathematical Systems Theory 25 (1): 23–36, 1992,
doi:10.1007/BF01368782.
Structural complexity theory. Constructs oracles in which \(\mathsf{BPP}\) (a probabilistic complexity class) and \(\mathsf{UP}\) (the class of problems with a unique "witness") contain languages that in a very strong sense are not contained in the other class. The conference version used the title "Probabilistic and unambiguous computation are incomparable".
Maintenance of a minimum spanning forest in a dynamic plane graph.
D. Eppstein,
G.F. Italiano,
R. Tamassia,
R.E. Tarjan,
J. Westbrook,
and M. Yung.
1st ACM-SIAM Symp. Discrete Algorithms,
San Francisco, 1990, pp. 1–11.
J. Algorithms 13 (1): 33–54, 1992
(special issue for 1st Symp. Discrete Algorithms),
doi:10.1016/0196-6774(92)90004-V.
Corrigendum, J. Algorithms 15: 173, 1993,
doi:10.1006/jagm.1993.1036.
The complement of a minimum spanning tree is a maximum spanning tree in the dual graph. By applying this fact we can use a modified form of Sleator and Tarjan's dynamic tree data structure to update the MST in logarithmic time per update.
The farthest point Delaunay triangulation minimizes angles.
D. Eppstein.
Tech. Rep. 90-45, ICS, UCI, 1990.
Comp. Geom. Theory & Applications 1: 143–148, 1992, doi:10.1016/S0925-7721(98)00031-5.
Given a collection of points in convex position, the sharpest angle determined by any triple can be found as a corner of a triangle in the farthest point Delaunay triangulation.
Parallel recognition of series parallel graphs.
D. Eppstein.
Information & Computation 98: 41–55, 1992,
doi:10.1016/0890-5401(92)90041-D.
Characterizes two-terminal series graphs in terms of a tree-like structure in their ear decompositions. Uses this characterization to construct parallel algorithms that recognize these graphs and construct their series-parallel decompositions.
Finding the k smallest spanning trees.
D. Eppstein.
2nd Scand. Worksh. Algorithm Theory, Bergen, Norway, 1990.
Springer, Lecture Notes in Comp. Sci. 447, 1990, pp. 38–47,
doi:10.1007/3-540-52846-6_76.
BIT 32: 237–248, 1992,
doi:10.1007/BF01994879.
(special issue for 2nd Scand. Worksh. Algorithm Theory).
By removing edges not involved in some solution, and contracting edges involved in all solutions, we reduce the problem to one in a graph with \(O(k)\) edges and vertices. This simplification step transforms any time bound involving \(m\) or \(n\) to one involving \(\min(m,k)\) or \(\min(n,k)\) respectively. This paper also introduces the geometric version of the \(k\) smallest spanning trees problem (the graph version was long known) which it solves using order-\((k+1)\) Voronoi diagrams.
Sparse dynamic programming.
D. Eppstein,
Z. Galil,
R. Giancarlo,
and G.F. Italiano.
1st ACM-SIAM Symp. Discrete Algorithms,
San Francisco, 1990, pp. 513–522.
"Sparse dynamic programming I: linear cost functions", J. ACM
39: 519–545, 1992,
doi:10.1145/146637.146650.
"Sparse dynamic programming II: convex and concave cost functions", J. ACM 39: 546–567, 1992,
doi:10.1145/146637.146656.
Considers sequence alignment and RNA structure problems in which the solution is constructed by piecing together some initial set of fragments (e.g. short sequences that match exactly). The method is to consider a planar point set formed by the fragment positions in the two input sequences, and use plane sweep to construct a cellular decomposition of the plane similar to the rectilinear Voronoi diagram.
Polynomial-size non-obtuse triangulation of polygons.
M. Bern
and D. Eppstein.
7th ACM Symp. Comp. Geom., North Conway, New Hampshire, 1991, pp. 342–350,
doi:10.1145/109648.109686
Int. J. Comp. Geom. & Appl. 2 (3): 241–255, 1992,
doi:10.1142/S0218195992000159
(special issue for 7th Symp. Comput. Geom.).
Erratum, Int. J. Comp. Geom. & Appl. 2 (4): 449–450, 1992,
doi:10.1142/S0218195992000305.
Any simple polygon can be triangulated with quadratically many nonobtuse triangles. Mostly subsumed by recent results of Bern et al described in "Faster circle packing".
Efficient algorithms for sequence analysis.
D. Eppstein,
Z. Galil,
R. Giancarlo,
and G.F. Italiano.
International Advanced Workshop on
Sequences, Positano, Italy, 1991.
Sequences II: Methods in Communication, Security, and Computer Science,
R.M. Capocelli, A. De Santis, and U. Vaccaro, eds.,
Springer, 1993, pp. 225–244,
doi:10.1007/978-1-4613-9323-8_17.
Surveys results on speeding up certain dynamic programs used for sequence comparison and RNA structure prediction.
Improved bounds for intersecting triangles and halving planes.
D. Eppstein.
Tech. Rep. 91-60, ICS, UCI, 1991.
J. Combinatorial Theory Ser. A 62: 176–182, 1993,
doi:10.1016/0097-3165(93)90082-J.
Reduces the polylogarithmic term in an upper bound for the three-dimensional k-set problem.
A bug in the proof was corrected by Nivasch and Sharir.
Connectivity, graph minors, and subgraph multiplicity.
D. Eppstein.
Tech. Rep. 92-06, ICS, UCI, 1992.
J. Graph Th. 17: 409–416, 1993,
doi:10.1002/jgt.3190170314.
It was known that planar graphs have \(O(n)\) subgraphs isomorphic to \(K_3\) or \(K_4\). That is, \(K_3\) and \(K_4\) have linear subgraph multiplicity. This paper shows that the graphs with linear subgraph multiplicity in the planar graphs are exactly the 3-connected planar graphs. Also, the graphs with linear subgraph multiplicity in the outerplanar graphs are exactly the 2-connected outerplanar graphs.
More generally, let \(\mathcal{F}\) be a minor-closed family, and let \(x\) be the smallest number such that some complete bipartite graph \(K_{x,y}\) is a forbidden minor for \(\mathcal{F}\). Then the \(x\)-connected graphs have linear subgraph multiplicity for \(\mathcal{F}\), and there exists an \((x-1)\)-connected graph (namely \(K_{x-1,x-1}\)) that does not have linear subgraph multiplicity. When \(x\le 3\) or when \(x=4\) and the minimal forbidden minors for \(\mathcal{F}\) are triangle-free, then the graphs with linear subgraph multiplicity for \(\mathcal{F}\) are exactly the \(x\)-connected graphs.
Please refer only to the journal version, and not the earlier technical report: the technical report had a bug that was repaired in the journal version.
Edge insertion for optimal triangulations.
M. Bern,
H. Edelsbrunner,
D. Eppstein,
S. Mitchell,
and
T.S. Tan.
1st Latin Amer. Symp. Theoretical Informatics, Sao Paulo, 1992.
Springer, Lecture Notes in Comp. Sci. 583, 1992, pp. 46–60,
doi:10.1007/BFb0023816.
Tech. Rep. EDC UILU-ENG-92-1702, Univ. Illinois, Urbana-Champaign, 1992.
Disc. & Comp. Geom. 10: 47–65, 1993,
doi:10.1007/BF02573962.
One standard way of constructing Delaunay triangulations is by iterated local improvement, in which each step flips the diagonal of some quadrilateral. For many other optimal triangulation problems, flipping is insufficient, but the problems can instead be solved by a more general local improvement step in which a new edge is added to the triangulation, cutting through several triangles, and the region it cuts through is retriangulated on both sides.
Visibility with a moving point of view.
M. Bern,
D.P. Dobkin,
D. Eppstein, and
R. Grossman.
1st ACM-SIAM Symp. Discrete Algorithms,
San Francisco, 1990, pp. 107–118.
Algorithmica 11: 360–378, 1994,
doi:10.1007/BF01187019
An investigation of 3d visibility problems in which the viewing position moves along a straight flight path, with various assumptions on the complexity of the viewed scene.
Efficient sequential and parallel algorithms for
computing recovery points in trees and paths.
M. Chrobak,
D. Eppstein,
G.F. Italiano,
and
M. Yung.
2nd ACM-SIAM Symp. Discrete Algorithms, San Francisco, 1991, pp. 158–167.
ALCOM Report 91-74, University of Rome, 1991.
Described slightly superlinear algorithms for partitioning a tree into a given number of subtrees, making them all as short as possible. Frederickson at the same conference further improved the sequential time to linear. There may still be something worth publishing in the parallel algorithms.
Provably good mesh generation.
M. Bern,
D. Eppstein, and
J. Gilbert.
31st IEEE Symp. Foundations of Comp. Sci.,
St. Louis, Missouri, 1990, pp. 231–241,
doi:10.1109/FSCS.1990.89542.
J. Comp. Sys. Sci. 48: 384–409, 1994,
doi:10.1016/S0022-0000(05)80059-5
(special issue for 31st FOCS).
In this paper, we construct triangulations of point sets and polygons by using quadtrees to add extra vertices to the input. As a result we can guarantee that all triangles have angles bounded away from zero, using a number of triangles within a constant of optimal; this was the first paper to provide simultaneous bounds on mesh element quality and mesh complexity of this form, and therefore the first to provide finite element mesh generation algorithms that guarantee both the robustness of the algorithm against unexpected input geometries and the quality of its output.
In the same paper we also use quadtrees to triangulate planar point sets so that all angles are non-obtuse, using linearly many triangles, and to triangulate higher dimensional point sets with no small solid angles and a number of simplices within a constant of optimal. Also, we can augment any higher dimensional point set so the Delaunay triangulation has linear complexity.
In later follow-up work, I showed that the same technique can also be used to find a triangulation whose edges have total length within a constant factor of optimal. Bern, Mitchell, and Ruppert showed that alternative methods can be used to triangulate any polygon without obtuse angles; see "Faster circle packing with application to nonobtuse triangulation" for an algorithmic improvement to their technique. Additionally, with Bern, Chew, and Ruppert, we showed that any point set in higher dimensions can be triangulated with nonobtuse simplices. Bern and I surveyed these and related results in our paper "Mesh generation and optimal triangulation".
Dynamic three-dimensional linear programming.
D. Eppstein.
Tech. Rep. 91-53, ICS, UCI, 1991.
32nd IEEE Symp. Foundations of Comp. Sci.,
San Juan, Puerto Rico, 1991, pp. 488–494,
doi:10.1109/SFCS.1991.185410.
ORSA J. Computing 4: 360–368, 1992,
doi:10.1287/ijoc.4.4.360
(special issue on computational geometry).
Uses Dobkin-Kirkpatrick hierarchies to perform linear programming queries in the intersection of several convex polyhedra. By maintaining a collection of halfspaces as several subsets, represented by polyhedra, this leads to algorithms for a dynamic linear program in which updates change the set of constraints. The fully dynamic results have largely been subsumed by Agarwal and Matoušek, but this paper also includes polylog time results for semi-online problems, and uses them to give a fast randomized algorithm for the planar 2-center problem (later improved by various authors, most recently in "Faster Construction of Planar Two-Centers", which re-uses the data structures described here).
Persistence, offline algorithms, and space compaction.
D. Eppstein.
Tech. Rep. 91-54, ICS, UCI, 1991.
Considers persistence for a naive form of dynamic algorithm in which each update rebuilds a static solution. The space bounds for this can often be reduced by maintaining an offline solution over a sequence of updates constructed from an Euler tour of the persistent update history tree.
Approximating the minimum weight Steiner triangulation.
D. Eppstein.
Tech. Rep. 91-55, ICS, UCI, 1991.
3rd ACM-SIAM Symp. Discrete Algorithms, Orlando, 1992, pp. 48–57.
Disc. Comp. Geom. 11: 163–191, 1994,
doi:10.1007/BF02574002.
Quadtree based triangulation gives a large but constant factor approximation to the minimum weight triangulation of a point set or convex polygon, allowing extra Steiner points to be added as vertices. Includes proofs of several bounds on triangulation weight relative to the minimum spanning tree or non-Steiner triangulation.
A conjecture from this paper, that for convex polygons the only points that need to be added are on the polygon boundary, turns out to be false. There is a counterexample in "Minimum-weight Steiner triangulation of convex polygons requires interior Steiner points".
New algorithms for minimum area \(k\)-gons.
D. Eppstein.
Tech. Rep. 91-59, ICS, UCI, 1991.
3rd ACM-SIAM Symp. Discrete Algorithms, Orlando, 1992, pp. 83–86.
Shows that the minimum area polygon containing \(k\) of \(n\) points must be near a line determined by two points, and uses this observation to find the polygon quickly. Merged with "Iterated nearest neighbors and finding minimal polytopes" in the journal version.
New algorithms for minimum measure simplices and one-dimensional
weighted Voronoi diagrams.
D. Eppstein and
J. Erickson.
Tech. Rep. 92-55, ICS, UCI, 1992.
Looks at space complexity of finding minimum simplices – solves the problem in \(O(n^2)\) space and \(O(n^d)\) time (matching the best known time bounds) or in linear space at the expense of an additional log in time. Also finds one-dimensional multiplicatively weighted Voronoi diagrams in linear time for sorted inputs (\(O(n\log n)\) was known).
Iterated nearest neighbors and finding minimal polytopes.
D. Eppstein and
J. Erickson.
Tech. Rep. 92-71, ICS, UCI, 1992.
4th ACM-SIAM Symp. Discrete Algorithms, Austin, 1993, pp. 64–73.
Disc. Comp. Geom. 11: 321–350, 1994,
doi:10.1007/BF02574012.
Showed that for various optimization criteria, the optimal polygon containing \(k\) of \(n\) points must be near one of the points, hence one can transform time bounds involving several factors of \(n\) to bounds linear in \(n\) but polynomial in \(k\). Used as a subroutine are data structures for finding several nearest neighbors in rectilinear metric spaces, and algorithms for finding the deepest point in an arrangement of cubes or spheres.
Tree-weighted neighbors and geometric \(k\) smallest spanning trees.
D. Eppstein.
Tech. Rep. 92-77, ICS, UCI, 1992.
Int. J. Comp. Geom. & Appl. 4: 229–238, 1994,
doi:10.1142/S0218195994000136.
"Finding the \(k\) smallest spanning trees" used higher order Voronoi diagrams to reduce the geometric \(k\) smallest spanning tree problem to the graph problem. Here I instead use nearest neighbors for a modified distance function where the bottleneck shortest path length is subtracted from the true distance between points. The result improves the planar time bounds and extends more easily to higher dimensions.
On the number of minimal 1-Steiner trees.
B. Aronov,
M. Bern,
and D. Eppstein.
Disc. & Comp. Geom. 12: 29–34, 1994,
doi:10.1007/BF02574363.
Given a \(d\)-dimensional set of \(n\) points, the number of combinatorially different minimum spanning trees that can be formed by adding one more point is within a polylogarithmic factor of \(n^d\).
Arboricity and bipartite subgraph listing algorithms.
D. Eppstein.
Tech. Rep. 94-11, ICS, UCI, 1994.
Inf. Proc. Lett. 51: 207–211, 1994, doi:10.1016/0020-0190(94)90121-X.
For any sparse family of graphs, one can list in linear time all complete bipartite subgraphs of a graph in the family. There are \(O(n)\) complete bipartite subgraphs of a graph in the family, and the sum of the numbers of vertices in these subgraphs is also \(O(n)\).
These results can also be interpreted as a form of formal concept analysis. If a set of objects and attributes is sparse (e.g., if it is generated by adding objects and attributes one at a time, where each newly-added object is given \(O(1)\) attributes and each newly-added attribute is held by \(O(1)\) objects) then the total size of all concepts in its concept lattice is linear, and this lattice may be generated in linear time.
Offline algorithms for dynamic minimum spanning tree problems.
D. Eppstein.
2nd Worksh. Algorithms and Data Structures, Ottawa, Canada, 1991.
Springer, Lecture Notes in Comp. Sci. 519, 1991, pp. 392–399,
doi:10.1007/BFb0028278.
Tech. Rep. 92-04, ICS, UCI, 1992.
J. Algorithms 17: 237–250, 1994, doi:10.1006/jagm.1994.1033.
Given a sequence of edge insertions and deletions in a graph, finds the corresponding sequence of minimum spanning tree changes, in logarithmic time per update. Similarly solves the planar geometric version of the problem (using a novel "mixed MST" formulation in which part of the input is a graph and part is a point set) in time \(O(\log^2 n)\) for the Euclidean metric and \(O(\log n\log\log n)\) for the rectilinear metric.
Dynamic Euclidean minimum spanning trees and extrema of binary functions.
D. Eppstein.
Tech. Rep. 92-05, ICS, UCI, 1992.
Tech. Rep. 92-88, ICS, UCI, 1992.
Disc. Comp. Geom. 13: 111–122, 1995,
doi:10.1007/BF02574030.
Shows that bichromatic nearest neighbors can be maintained under point insertion and deletion essentially as quickly as known solutions to the post office problem, and that the minimum spanning tree can be maintained in the same time except for an additive \(O(\sqrt n)\) needed for solving the corresponding graph problem. TR 92-88's title was actually "Fully dynamic maintenance of Euclidean minimum spanning trees and maxima of decomposable functions". TR 92-05's title left out the part about maxima; that version gave a slower algorithm superseded by the result in 92-88.
Dynamic half-space reporting, proximity problems, and
geometric minimum spanning trees.
P.K. Agarwal,
D. Eppstein, and
J. Matoušek.
33rd IEEE Symp. Foundations of
Comp. Sci., Pittsburgh, 1992, pp. 80–89,
doi:10.1109/SFCS.1992.267816.
This conference paper merged my results from "Dynamic Euclidean minimum spanning trees" with results of my co-authors on nearest neighbors and halfspace range searching.
Ten algorithms for Egyptian fractions.
D. Eppstein.
Mathematica in Education and Research 4 (2): 5–15, 1995.
Number theory. I survey and implement in Mathematica several methods for representing rational numbers as sums of distinct unit fractions. One of the methods involves searching for paths in a certain graph using a \(k\) shortest paths heuristic.
Also available in HTML and Mathematica notebook formats. See also "Egyptian fractions with denominators from sequences closed under doubling".
Asymptotic speed-ups in constructive solid geometry.
D. Eppstein.
Tech. Rep. 92-87, ICS, UCI, 1992.
Algorithmica 13: 462–471, 1995,
doi:10.1007/BF01190849.
Finds boundary representations of CSG objects. Uses techniques from dynamic graph algorithms, including a tree partitioning technique of Frederickson and a new data structure for maintaining the value of a Boolean expression with changing variables in time \(O(\log n / \log\log n)\) per update.
Subquadtratic nonobtuse triangulation of convex polygons.
D. Eppstein.
Tech. Rep. 91-61, ICS, UCI, 1991.
This was merged into "triangulating polygons without large angles". We find a grid-like structure in the input polygon, which is then thinned out using a complicated divide-and-conquer scheme. The results are largely subsumed by the method of Bern et al. described in "Faster circle packing".
Triangulating polygons without large angles.
M. Bern,
D. Dobkin,
and D. Eppstein.
8th ACM Symp. Comp. Geom., Berlin, 1992, pp. 222–231,
doi:10.1145/142675.142722.
Int. J. Comp. Geom. & Appl. 5: 171–192, 1995,
doi:10.1142/S0218195995000106
(special issue for 8th Symp. Comput. Geom.)
Follows up "Polynomial size non-obtuse triangulation of polygons"; improves the number of triangles by relaxing the requirements on their angles. Again mostly subsumed by results of Bern et al described in "Faster circle packing".
Mesh generation and optimal triangulation.
M. Bern
and D. Eppstein.
Tech. Rep. CSL-92-1, Xerox PARC, 1992.
Computing in Euclidean Geometry,
D.-Z. Du and F.K. Hwang, eds.,
World Scientific, 1992, pp. 23–90.
Revised
version in Computing in Euclidean Geometry, 2nd ed.,
D.-Z. Du and F.K. Hwang, eds.,
World Scientific, 1995, pp. 47–123,
doi:10.1142/9789812831699_0003.
Considers both heuristics and theoretical algorithms for finding good triangulations and tetrahedralizations for surface interpolation and unstructured finite element meshes. Note that the online copy here omits the figures.
A deterministic linear time algorithm for geometric separators
and its applications.
D. Eppstein,
G.L. Miller, and
S.-H. Teng.
9th ACM Symp. Comp. Geom., San Diego, 1993, pp. 99–108,
doi:10.1145/160985.161005.
Fundamenta Informaticae 22: 309–330, 1995,
doi:10.3233/FI-1995-2241
(special issue on computational geometry).
Teng and others previously showed that certain geometric graphs had small separators that could be found by lifting the graph to a sphere one dimension up and choosing a random great circle. Here we show that epsilon-cuttings and the method of conditional expectations can be used to guide a deterministic prune-and-search method for the same problem. Applications include finding the intersection graph of a collection of spheres and computing or approximating the maximum number of spheres having a common intersection.
Sparsification—A technique for speeding up dynamic graph algorithms.
D. Eppstein,
Z. Galil,
G.F. Italiano, and A. Nissenzweig.
33rd IEEE Symp. Foundations of Comp. Sci., Pittsburgh, 1992, pp. 60–69,
doi:10.1109/SFCS.1992.267818.
Tech. Rep. RC 19272 (83907), IBM, 1993.
Tech. Rep. CS96-11, Univ. Ca' Foscari di Venezia, Oct. 1996.
J. ACM 44 (5): 669–696, 1997, doi:10.1145/265910.265914.
Uses a divide and conquer on the edge set of a graph, together with the idea of replacing subgraphs by sparser certificates, to make various dynamic algorithms as fast on dense graphs as they are on sparse graphs. Applications include random generation of spanning trees as well as finding the \(k\) minimum weight spanning trees for a given parameter \(k\).
Improved sparsification.
D. Eppstein,
Z. Galil, and
G.F. Italiano.
Tech. Rep. 93-20, ICS, UCI, 1993.
Saves a log factor over dynamic graph algorithms in "Sparsification" and their applications, by dividing vertices instead of edges. Merged into the journal version of "Sparsification".
Separator based sparsification for dynamic planar graph algorithms.
D. Eppstein,
Z. Galil,
G.F. Italiano, and T. Spencer.
25th ACM Symp. Theory of Computing, San Diego, 1993, pp. 208–217,
doi:10.1145/167088.167159.
Replaces portions of a hierarchical separator decomposition with smaller certificates to achieve fast update times for various dynamic planar graph problems. Applications include finding the k best spanning trees of a planar graph.
Separator based sparsification I:
planarity testing and minimum spanning trees.
D. Eppstein,
Z. Galil,
G.F. Italiano, and T. Spencer.
J. Comp. Sys. Sci. 52: 3–27, 1996, doi:10.1006/jcss.1996.0002
(special issue for 25th STOC).
First half of journal version of Separator based sparsification for dynamic planar graph algorithms.
Separator based sparsification II: edge and vertex connectivity.
D. Eppstein,
Z. Galil,
G.F. Italiano, and T. Spencer.
Tech. Rep. CS96-13, Univ. Ca' Foscari di Venezia, Oct. 1996.
SIAM
J. Computing 28 (1): 341–381, 1999,
doi:10.1137/S0097539794269072.
Second half of journal version of Separator based sparsification for dynamic planar graph algorithms.
Algorithms for proximity problems in higher dimensions.
M. T. Dickerson and D. Eppstein.
Comp. Geom. Theory & Applications 5: 277–291, 1996,
doi:10.1016/0925-7721(95)00009-7.
Combines a method from "Provably good mesh generation" for finding sparse high-dimensional Delaunay triangulations, a method of Dickerson, Drysdale, and Sack ["Simple algorithms for enumerating interpoint distances", IJCGA 1992] for using Delaunay triangulations to search for nearest neighbors, and a method of Frederickson for speeding up tree-based searches. The results are fast algorithms for several proximity problems such as finding the k nearest neighbors to each point in a given point set.
(Local copy of CGTA 1996 version of "algorithms for proximity problems")
Average case analysis of dynamic geometric optimization.
D. Eppstein.
Tech. Rep. 93-18, ICS, UCI, 1993.
5th ACM-SIAM Symp. Discrete Algorithms, Arlington, 1994, pp. 77–86.
Comp. Geom. Theory & Applications 6: 45–68, 1996, doi:10.1016/0925-7721(95)00018-6.
The Tech. Report used the more informative title "Updating widths and maximum spanning trees using the rotating caliper graph", which I also used for the journal submission, but the referees made me change it back. Dynamic geometry in a model of Mulmuley and Schwarzkopf in which insertions and deletions are chosen randomly among a worst-case pool of points. This paper introduces several fundamental techniques including the rotating caliper graph of a point set and a method for performing decomposible range queries in the average case setting. It has also since inspired the use of a similar model in dynamic graph algorithms.
(SODA'94 paper – Local copy of CGTA 1996 version of "average case analysis")
Dynamic geometric optimization.
D. Eppstein.
Invited talk,
3rd MSI Worksh. Computational Geometry, 1993, p. 14.
Computing the discrepancy.
D. P. Dobkin and D. Eppstein.
9th ACM Symp. Comp. Geom., San Diego, 1993, pp. 47–52,
doi:10.1145/160985.160997.
Measures how well a sample of points from a set works as a discrete approximation to the continuous measure of shapes in the set, using algorithms based on Overmars and van Leeuwen's dynamic convex hull data structure. Some versions of the problem also involve subroutines for finding the deepest point in an arrangement of quadrants or orthants.
This paper was merged with results of Mitchell to form the journal version, "Computing the discrepancy with applications to supersampling patterns".
Computing the discrepancy with applications to supersampling patterns.
D. P. Dobkin,
D. Eppstein, and
D. P. Mitchell.
ACM Trans. on Graphics 15 (4): 354–376, 1996., doi:10.1145/234535.234536
Combines "Computing the discrepancy" with experimental results of Mitchell on the discrepancies of various point sets, emphasizing the application of low-discrepancy sets to anti-aliasing in raytraced graphics.
Faster circle packing with application to nonobtuse triangulation.
D. Eppstein.
Tech. Rep. 94-33, ICS, UCI 1994.
Int. J. Comp. Geom. & Appl. 7 (5): 485–491, 1997,
doi:10.1142/S0218195997000296.
Speeds up a triangulation algorithm of Bern et al. ["Linear-Size Nonobtuse Triangulation of Polygons"] by finding a collection of disjoint circles which connect up the holes in a non-simple polygon. The method is to use a minimum spanning tree to find a collection of overlapping circles, then shrink them one by one to reduce the number of overlaps, using Sleator and Tarjan's dynamic tree data structure to keep track of the connectivity of the shrunken circles.
Approximating center points with iterated Radon points.
K. Clarkson, D. Eppstein,
G.L. Miller,
C. Sturtivant, and
S.-H. Teng.
9th ACM Symp. Comp. Geom., San Diego, 1993, pp. 91–98,
doi:10.1145/160985.161004.
Int. J. Comp. Geom. & Appl. 6 (3): 357–377, 1996,
doi:10.1142/S021819599600023X.
Given a collection of n sites, a center point is a point (not necessarily a site) such that no hyperplane through the centerpoint partitions the collection into a very small and a very large subset. Center points have been used by Teng and others as a key step in the construction of geometric separators. One can find a point with this property by choosing a random sample of the collection and applying linear programming, but the complexity of that method grows exponentially with the dimension. This paper proposes an alternate method that produces lower quality approximations (in terms of the size of the worst hyperplane partition) but takes time polynomial in both n and d.
Worst-case bounds for subadditive geometric graphs.
M. Bern
and D. Eppstein.
9th ACM Symp. Comp. Geom., San Diego, 1993, pp. 183–188,
doi:10.1145/160985.161018.
For many geometric graph problems for points in the unit square, such as minimum spanning trees, matching, and traveling salesmen, the sum of edge lengths is O(sqrt n) and the sum of dth powers of edge lengths is O(log n). We provide a "gap theorem" showing that if these bounds do not hold for a class of graphs, both sums will instead be Omega(n). For traveling salesmen the O(log n) bound is tight but for some other graphs the sum of dth powers of edge lengths is O(1).
Parallel construction of quadtrees and quality triangulations.
M. Bern,
D. Eppstein, and
S.-H. Teng.
3rd Worksh. Algorithms and Data
Structures, Montreal, 1993,
doi:10.1007/3-540-57155-8_247.
Springer, Lecture Notes in
Comp. Sci. 709, 1993, pp. 188–199.
Tech. Rep. 614, MIT Lab. for Comp. Sci., 1994.
Int. J. Comp. Geom. & Appl.
9 (6): 517–532, 1999,
doi:10.1142/S0218195999000303.
A parallelization of the quadtree constructions in "Provably good mesh generation", in an integer model of computation, based on a technique of sorting the input points using values formed by shuffling the binary representations of the coordinates. A side-effect is an efficient construction for the "fair split tree" hierarchical clustering method used by Callahan and Kosaraju for various nearest neighbor problems.
Clustering for faster network simplex pivots.
D. Eppstein.
Tech. Rep. 93-19, ICS, UCI, 1993.
5th ACM-SIAM Symp. Discrete Algorithms,
Arlington, 1994, pp. 160–166.
Networks 35 (3): 173–180, 2000,
doi:10.1002/(SICI)1097-0037(200005)35:3<173::AID-NET1>3.0.CO;2-W.
Speeds up the worst case time per pivot for various versions of the network simplex algorithm for minimum cost flow problems. Uses techniques from dynamic graph algorithms as well as some simple geometric data structures.
Finding the k shortest paths.
D. Eppstein.
35th IEEE Symp. Foundations of Comp. Sci., Santa Fe, 1994, pp. 154–165,
doi:10.1109/SFCS.1994.365697.
Tech. Rep. 94-26, ICS, UCI, 1994.
SIAM J. Computing 28 (2): 652–673, 1998, doi:10.1137/S0097539795290477.
This paper presents an algorithm that finds multiple short paths connecting two terminals in a graph (allowing repeated vertices and edges in the paths) in constant time per path after a preprocessing stage dominated by a single-source shortest path computation. The paths it finds are the k shortest in the graph, where k is a parameter given as input to the algorithm.
The k shortest paths problem has many important applications for finding alternative solutions to geographic path planning problems, network routing, hypothesis generation in computational linguistics, and sequence alignment and metabolic pathway finding in bioinformatics. Although there have been many papers on the k shortest paths problem before and after this one, it has become frequently cited in those application areas. Additionally, it marks a boundary in the theoretical study of the problem: prior theoretical work largely concerned how quickly the problem could be solved, a line of research that was closed off by the optimal time bounds of this paper. Subsequent work has focused instead on devising efficient algorithms for more complex alternative formulations of the problem that avoid the repeated vertices and other shortcomings of the alternative paths produced by this formulation.
The journal version also includes material from a separate 1995 technical report, "Finding common ancestors and disjoint paths in DAGs".
(Local copy of SICOMP 1998 version – Graehl implementation – Jiménez-Marzal implementations – Shibuya implementation – Cliff OpenStreetMap demo)
Dihedral bounds for mesh generation in high dimensions.
M. Bern,
L.P. Chew,
D. Eppstein, and
J. Ruppert.
892nd Meeting Amer. Math. Soc., Brooklyn, 1994.
Abstract in Abs. Amer. Math. Soc. 15, 1994, p. 366.
6th ACM-SIAM Symp. Discrete Algorithms,
San Francisco, 1995, pp. 189–196.
Any d-dimensional point set can be triangulated with O(nceil(d/2)) simplices, none of which has an obtuse dihedral angle. No bound depending only on n is possible if we require the maximum dihedral angle to measure at most 90-epsilon degrees or the minimum dihedral to measure at least epsilon. Includes a classification of simplices in terms of their bad angles.
Subgraph isomorphism in planar graphs and related problems.
D. Eppstein.
Tech. Rep. 94-25, ICS, UCI, 1994.
6th ACM-SIAM Symp. Discrete Algorithms,
San Francisco, 1995, pp. 632–640.
arXiv:cs.DS/9911003.
J. Graph
Algorithms and Applications 3 (3): 1–27, 1999, doi:10.7155/jgaa.00014.
Uses an idea of Baker to cover a planar graph with subgraphs of low treewidth. As a consequence, any fixed pattern can be found as a subgraph in linear time; the same methods can be used to solve other planar graph problems including vertex connectivity, diameter, girth, induced subgraph isomorphism, and shortest paths. A companion paper, "Diameter and treewidth in minor-closed graph families", presents a result announced in the conference version of this paper, that exactly characterizes the minor-closed graph families for which the same techniques apply.
Geometric lower bounds for parametric matroid optimization.
D. Eppstein.
Tech. Rep. 95-11, ICS, UCI, 1995.
27th ACM Symp. Theory of Computing, Las Vegas, 1995, pp. 662–671.
Disc. Comp. Geom. 20: 463–476, 1998,
doi:10.1007/PL00009396.
Considers graphs in which edge weights are linear functions of time. Shows nonlinear lower bounds on the number of different minimum spanning trees appearing over time by translation from geometric problem of lower envelopes of line segments. A matroid generalization has a better lower bound coming from many faces in line arrangements, and the uniform matroid problem is equivalent to the geometric k-set problem.
The centroid of points with approximate weights.
M. Bern,
D. Eppstein,
L. J. Guibas,
J. Hershberger,
S. Suri, and
J. Wolter.
3rd Eur. Symp. Algorithms,
Corfu, 1995.
Springer, Lecture Notes in
Comp. Sci. 979, 1995, pp. 460–472,
doi:10.1007/3-540-60313-1_163.
Given a set of points with weights that are not known precisely, but are known to fall within some range, considers the possible weighted centroids arising from different choices of weights in each range. The combinatorics of this problem are closely connected with those of zonotopes.
3-Coloring in time O(1.3446n): a no-MIS algorithm.
R. Beigel
and D. Eppstein.
Tech. Rep. 95-033, Electronic Coll. Computational Complexity, 1995.
36th IEEE Symp. Foundations of Comp. Sci., 1995, pp. 444–453,
doi:10.1109/SFCS.1995.492575.
DIMACS
Worksh. Faster Exact Solutions for \(\mathsf{NP}\)-Hard Problems, 2000.
Speeds up 3-coloring by solving a harder problem: constraint satisfaction in which each variable can take on one of three values and each constraint forbids a pair of variable assignments. The detailed solution involves several long hairy case analyses. Similar methods apply also to 3-list-coloring, 3-edge-coloring, and 3-SAT. The 3-SAT algorithm is fixed-parameter tractible in that it is polynomial time when the number of 3-variable clauses is \(O(\log n)\). Merged into 3-coloring in time \(O(1.3289^n)\) for the journal version.
(DIMACS abstract and DIMACS slides)
Approximation algorithms for geometric problems.
M. Bern
and D. Eppstein.
Approximation Algorithms for \(\mathsf{NP}\)-hard Problems,
D. Hochbaum, ed.,
PWS Publishing, 1996, pp. 296–345.
Considers problems for which no polynomial-time exact algorithms are known, and concentrates on bounds for worst-case approximation ratios, especially those depending intrinsically on geometry rather than on more general graph theoretic or metric space formulations. Includes sections on the traveling salesman problem, Steiner trees, minimum weight triangulation, clustering, and separation problems.
The diameter of nearest neighbor graphs.
D. Eppstein.
Tech. Rep. 92-76, ICS, UCI, 1992.
Any connected nearest neighbor forest with diameter D has O(D6) vertices. This was later further improved to O(D5) and merged with results of Paterson and Yao into "On nearest neighbor graphs".
Minimum range balanced cuts via dynamic subset sums.
D. Eppstein.
Tech. Rep. 95-10, ICS, UCI, 1995.
J. Algorithms 23: 375–385, 1997, doi:10.1006/jagm.1996.0841.
Describes data structures for maintaining the solution of a dynamically changing subset sum problem, and uses them to find a cut in a graph minimizing the difference between the heaviest and lightest cut edge.
Choosing subsets with maximum weighted average.
D. Eppstein and
D. S. Hirschberg.
Tech. Rep. 95-12, ICS, UCI, 1995.
5th MSI Worksh. on Computational Geometry, 1995, pp. 7–8.
J. Algorithms 24: 177–193, 1997, doi:10.1006/jagm.1996.0849.
Uses geometric optimization techniques to find, among n weighted values, the k to drop so as to maximize the weighted average of the remaining values. The feasibility test for the corresponding decision problem involves k-sets in a dual line arrangement.
Faster geometric k-point MST approximation.
D. Eppstein.
Tech. Rep. 95-13, ICS, UCI, 1995.
Comp. Geom. Theory & Applications 8: 231–240, 1997,
doi:10.1016/S0925-7721(96)00021-1.
Various authors have looked at a variant of geometric clustering in which one must select \(k\) points that can be connected by a small spanning tree. The problem is \(\mathsf{NP}\)-complete (for variable \(k\)); good approximations are known based on dynamic programming techniques but the time dependence on \(n\) is high. This paper describes a faster approximation algorithm based on dynamic programming in quadtrees, and a general technique based on that in "Iterated nearest neighbors" for reducing the dependence on \(n\) in any approximation algorithm.
Representing all minimum spanning trees with applications to
counting and generation.
D. Eppstein.
Tech. Rep. 95-50, ICS, UCI, 1995.
Shows how to find for any edge weighted graph G an equivalent graph EG such that the minimum spanning trees of G correspond one-for-one with the spanning trees of EG. The equivalent graph can be constructed in time O(m+n log n) given a single minimum spanning tree of G. As a consequence one can find fast algorithms for counting, listing, and randomly generating MSTs. Also discusses similar equivalent graph constructions for shortest paths, minimum cost flows, and bipartite matching.
Linear complexity hexahedral mesh generation.
D. Eppstein.
Tech. Rep. 95-51, ICS, UCI, 1995.
12th ACM Symp. Comp. Geom., Philadelphia,
1996, pp. 58–67,
doi:10.1145/237218.237237.
arXiv:cs.CG/9809109.
Comp. Geom. Theory & Applications 12: 3–16, 1999,
doi:10.1016/S0925-7721(98)00032-7
(special issue for 12th SCG).
Any simply connected polyhedron with an even number of quadrilateral sides can be partitioned into O(n) topological cubes, meeting face to face.
Finding common ancestors and disjoint paths in DAGs.
D. Eppstein.
Tech. Rep. 95-52, ICS, UCI, 1995.
This paper describes algorithms for finding pairs of vertex-disjoint paths in a DAG, either connecting two given nodes to a common ancestor, or connecting two given pairs of terminals. The main results were merged into the journal version of "Finding the k shortest paths".
Zonohedra and Zonotopes.
D. Eppstein.
Tech. Rep. 95-53, ICS, UCI, 1995.
Mathematica in Education and Research 5 (4): 15–21, 1996.
I use Mathematica to construct zonotopes and display zonohedra. Many examples are shown, including one used for a lower bound in "The centroid of points with approximate weights". This paper is also available in HTML and Mathematica notebook formats.
On nearest-neighbor graphs.
D. Eppstein,
M. S. Paterson,
and F. F. Yao.
Disc. Comp. Geom. 17: 263–282, 1997,
doi:10.1007/PL00009293.
Paterson and Yao presented a paper at ICALP showing among other things that any connected nearest neighbor forest with diameter D has O(D9) vertices. This paper is the journal version; my contribution consists of improving that bound to O(D5), which is tight.
On triangulating three-dimensional polygons.
G. Barequet,
M. Dickerson,
and D. Eppstein.
12th ACM Symp. Comp. Geom., Philadelphia, 1996, pp. 38–47.
Comp. Geom. Theory & Applications 10: 155–170, 1998, doi:10.1016/S0925-7721(98)00005-4.
It is \(\mathsf{NP}\)-complete, given a simple polygon in 3-space, to find a triangulated simply-connected surface (without extra vertices) spanning that polygon. If extra vertices are allowed, or the surface may be curved, such a surface exists if and only if the polygon is unknotted; the complexity of testing knottedness remains open. Snoeyink has shown that exponentially many extra vertices may be required for a triangulated spanning disk.
Using sparsification for parametric minimum spanning tree problems.
D. Fernández-Baca,
G. Slutzki,
and D. Eppstein.
5th Scand. Worksh. Algorithm
Theory, Reykjavik, 1996.
Springer, Lecture Notes in
Comp. Sci. 1097, 1996, pp. 149–160,
doi:10.1007/3-540-61422-2_128.
Nordic J. Computing
3 (4): 352–366, 1996 (special issue for 5th SWAT).
Given a graph with edge weights that are linear functions of a parameter, finds the sequence of minimum spanning trees produced as the parameter varies, in total time \(O(mn\log n)\), by combining ideas from "Sparsification" and "Geometric lower bounds". Also solves various problems of optimizing the parameter value, including one closely related to that in "Choosing subsets with maximum weighted average".
Faster construction of planar two-centers.
D. Eppstein.
Tech. Rep. 96-12, ICS, UCI, 1996.
8th ACM-SIAM Symp. Discrete Algorithms, New Orleans, 1997, pp. 131–138.
Improving on a recent breakthrough of Sharir, we use data structures from "Dynamic three-dimensional linear programming" to find two circular disks of minimum radius covering a set of points in the Euclidean plane, in randomized expected time O(n log2 n).
Dynamic connectivity in digital images.
D. Eppstein.
Tech. Rep. 96-13, ICS, UCI, 1996.
Inf. Proc. Lett. 62: 121–126, 1997,
doi:10.1016/S0020-0190(97)00056-2.
Any algorithm that maintains the connected components of a bitmap image must take \(\Omega(\log n/\log\log n)\) time per change to the image. The problem can be solved in \(O(\log n)\) time per change using dynamic planar graph techniques. We discuss applications to computer Go and other games.
On the parity of graph spanning tree numbers.
D. Eppstein.
Tech. Rep. 96-14, ICS, UCI, 1996.
Any bipartite Eulerian graph, any Eulerian graph with evenly many vertices, and any bipartite graph with evenly many vertices and edges, has an even number of spanning trees. More generally, a graph has evenly many spanning trees if and only if it has an Eulerian edge cut.
Beta-skeletons have unbounded dilation.
D. Eppstein.
Tech. Rep. 96-15, ICS, UCI, 1996.
arXiv:cs.CG/9907031.
Comp. Geom. Theory & Applications 23: 43–52, 2002, doi:10.1016/S0925-7721(01)00055-4.
Beta-skeletons are geometric graphs used among other purposes for empirical network analysis and minimum weight triangulation. A fractal construction shows that, for any beta>0, the beta-skeleton of a point set can have arbitrarily large dilation: Omega(nc), where c is a constant depending on beta and going to zero in the limit as beta goes to zero. In particular this applies to the Gabriel graph. We also show upper bounds on dilation of the same form.
Spanning trees and spanners.
D. Eppstein.
Tech. Rep. 96-16, ICS, UCI, 1996.
Handbook of Computational Geometry, J.-R. Sack and J. Urrutia,
eds., Elsevier, 1999, pp. 425–461,
doi:10.1016/b978-044482537-7/50010-3.
Surveys results in geometric network design theory, including algorithms for constructing minimum spanning trees and low-dilation graphs.
Application Challenges to Computational Geometry.
The
Computational Geometry Impact Task Force
Report.
Tech.
Rep. TR-521-96, Princeton University, April 1996.
Advances in Discrete and Computational Geometry – Proc. 1996 AMS-IMS-SIAM
Joint Summer Research Conf. Discrete and Computational Geometry: Ten
Years Later, Contemporary Mathematics 223, Amer. Math. Soc., 1999, pp. 407–423.
Optimal point placement for mesh smoothing.
N. Amenta,
M. Bern,
and D. Eppstein.
8th ACM-SIAM Symp. Discrete
Algorithms, New Orleans, 1997, pp. 528–537.
Symp.
Computational Geometry Approaches to Mesh Generation,
SIAM 45th Anniversary Mtg., Stanford, 1997.
arXiv:cs.CG/9809081.
J. Algorithms 30: 302–322, 1999, doi:10.1006/jagm.1998.0984
(special issue for SODA 1997).
We study finite element mesh smoothing problems in which we move vertex locations to optimize the shapes of nearby triangles. Many such problems can be solved in linear time using generalized linear programming; we also give efficient algorithms for some non-LP-type mesh smoothing problems. One lemma may be of independent interest: the locus of points in Rd from which a d-1 dimensional convex set subtends a given solid angle is convex.
Dynamic graph algorithms.
D. Eppstein,
Z. Galil,
and G.F. Italiano.
Tech. Rep. CS96-11, Univ. Ca' Foscari di Venezia, Oct. 1996.
Algorithms and Theoretical Computing Handbook,
M. J. Atallah, ed., CRC Press, 1999, chapter 8.
2nd. ed., CRC Press, 2010, Vol. I: General Concepts and Techniques, chapter 9, pp. 9-1 – 9-28.
An efficient algorithm for shortest paths in vertical and horizontal
segments.
D. Eppstein and
D. Hart.
5th Worksh. Algorithms and Data Structures, Halifax, Nova Scotia, 1997.
Springer, Lecture Notes in
Comp. Sci. 1272, 1997, pp. 234–247,
doi:10.1007/3-540-63307-3_63.
We show how to find shortest paths along the segments of an arrangement of \(n\) vertical and horizontal line segments in the plane, in time \(O(n^{3/2})\).
Guest editor's foreword to special issue of papers from the
34th Annual Symposium on Foundations of Computer Science.
D. Eppstein.
J. Comp. Sys. Sci. 54:263, 1997,
doi:10.1006/jcss.1997.1469.
The crust and the beta-skeleton: combinatorial curve
reconstruction.
N. Amenta,
M. Bern,
and D. Eppstein.
Graphical Models & Image Processing 60/2 (2): 125–135, 1998, doi:10.1006/gmip.1998.0465.
We consider the problem of "connect the dots": if we have an unknown smooth curve from which sample points have been selected, we would like to find a curve through the sample points that approximates the unknown curve. We show that if the local sample density is sufficiently high, a simple algorithm suffices: form the Delaunay triangulation of the sample points together with their Voronoi vertices, and keep only those Delaunay edges connecting original sample points. There have been many follow-up papers suggesting alternative methods, generalizing the problem to the reconstruction of curves with sharp corners or to curves and surfaces in higher dimensions, etc.
Computational geometry and parametric matroid optimization.
D. Eppstein.
Invited talk,
5th Int. Symp. Parametric Optimization, Chiba, Japan, 1997.
This talk surveys some connections from computational geometry to parametric matroids: the results of my paper "Geometric lower bounds", new upper bounds from a paper by Tamal Dey, and a problem from constructive solid geometry with the potential to lead to stronger lower bounds.
Quadrilateral meshing by circle packing.
M. Bern
and D. Eppstein.
2nd CGC
Worksh. Computational Geometry, Durham, North Carolina, 1997.
6th Int. Meshing Roundtable, Park
City, Utah, 1997, pp. 7–19.
arXiv:cs.CG/9908016.
Int. J. Comp. Geom. & Appl. 10 (4): 347–360, 2000,
doi:10.1142/S0218195900000206.
We use circle-packing methods to generate quadrilateral meshes for polygonal domains, with guaranteed bounds both on the quality and the number of elements. We show that these methods can generate meshes of several types:
The elements form the cells of a Voronoi diagram,
The elements each have two opposite 90 degree angles,
All elements are kites, or
All angles are at most 120 degrees.
In each case the total number of elements is \(O(n)\). The 120-degree bound is optimal; if a simply-connected region has all angles at least 120 degrees, any mesh of that region has a 120 degree angle.
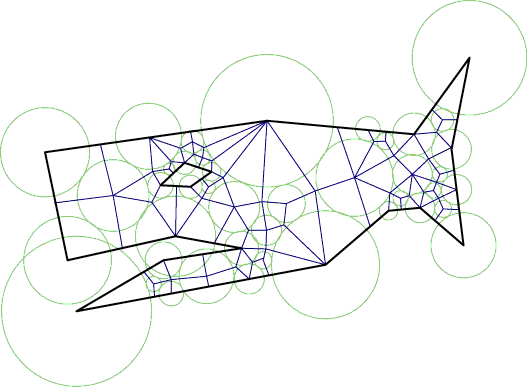
Fast hierarchical
clustering and other applications of dynamic closest pairs.
D. Eppstein.
9th ACM-SIAM Symp. Discrete Algorithms,
San Francisco, 1998, pp. 619–628.
arXiv:cs.DS/9912014.
J. Experimental
Algorithmics 5 (1): 1–23, 2000, doi:10.1145/351827.351829.
This paper shows how to use my dynamic closest pair data structure from "Dynamic Euclidean minimum spanning trees" for some non-geometric problems including hierarchical clustering, greedy matching, and TSP heuristics. Experiments show variants of my data structures to be faster than previously used heuristics.
Raising roofs, crashing cycles, and playing pool: applications of
a data structure for finding pairwise interactions.
D. Eppstein and
J. Erickson.
14th ACM Symp. Comp. Geom., Minneapolis, 1998, pp. 58–67,
doi:10.1145/276884.276891.
Disc. Comp. Geom. 22 (4): 569–592, 1999,
doi:10.1007/PL00009479
(special issue for SCG 1998).
We use my dynamic closest pair data structure from "Dynamic Euclidean minimum spanning trees" to detect collisions among a collection of moving objects in sublinear time per collision. As one application, we can construct the straight skeleton of Aichholzer et al (and the mitered offset curves from which it is defined) in subquadratic time.
Geometric thickness of complete graphs.
M. Dillencourt,
D. Eppstein, and
D. S. Hirschberg.
6th Int. Symp. Graph Drawing,
Montreal, August 1998.
Springer, Lecture Notes in
Comp. Sci. 1547, 1998, pp. 102–110,
doi:10.1007/3-540-37623-2_8.
arXiv:math.CO/9910185.
J. Graph
Algorithms and Applications 4 (3): 5–17, 2000, doi:10.7155/jgaa.00023
(special issue for GD98).
We define a notion of geometric thickness, intermediate between the previously studied concepts of graph thickness and book thickness: a graph has geometric thickness T if its vertices can be embedded in the plane, and its edges partitioned into T subsets, so that each subset forms a planar straight line graph. We then give upper and lower bounds on the geometric thickness of complete graphs.
Diameter and treewidth in minor-closed graph families.
D. Eppstein.
arXiv:math.CO/9907126.
Algorithmica 27: 275–291, 2000,
doi:10.1007/s004530010020
(special issue on treewidth, graph minors, and algorithms).
This paper introduces the diameter-treewidth property (later known as bounded local treewidth): a functional relationship between the diameter of its graph and its treewidth. Previously known results imply that planar graphs have bounded local treewidth; we characterize the other minor-closed families with this property. Specifically, minor-closed family F has bounded local treewidth if and only if there exists an apex graph G that is not in F; an apex graph is a graph that can be made planar by removing a single vertex. The minor-free families that exclude an apex graph (and therefore have bounded local treewidth) include the bounded-genus graphs (for which, as with planar graphs, we show a linear bound for the treewidth as a function of the diameter) and K3,a-free graphs. As a consequence, subgraph isomorphism for subgraphs of bounded size and approximations to several \(\mathsf{NP}\)-hard optimization problems can be computed efficiently on these graphs, extending previous results for planar graphs.
Some of these results were announced in the conference version of "subgraph isomorphism for planar graphs and related problems" but not included in the journal version. Since its publication, there have been many more works on local treewidth. The class of problems that could be solved quickly on graphs of bounded local treewidth was extended and classified by Frick and Grohe, "Deciding first-order properties of locally tree-decomposable structures", J. ACM 48: 1184–1206, 2001, doi:10.1145/504794.504798; the proof that bounded local treewidth is equivalent to having an excluded apex minor was simplified, and the dependence of the treewidth on diameter improved, by Demaine and Hajiaghayi, "Diameter and treewidth in minor-closed graph families, revisited", Algorithmica 40: 211–215, 2004. The concept of local treewidth is the basis for the theory of bidimensionality, a general framework for fixed-parameter-tractable algorithms and approximation algorithms in minor-closed graph families; for a survey, see Demaine and Hajiaghayi, "The bidimensionality theory and its algorithmic applications", The Computer J. 51: 292–302, 2008.
Shortest paths in an arrangement with k line orientations.
D. Eppstein and
D. Hart.
10th ACM-SIAM Symp. Discrete Algorithms, Baltimore, 1999, pp. 310–316.
We show how to find shortest paths between two points on the lines of an arrangement of \(n\) lines with \(k\) distinct orientations, in time \(O(n+k^2)\).
A disk-packing algorithm for an origami magic trick.
M. Bern,
E. Demaine,
D. Eppstein, and
B. Hayes.
Int. Conf. Fun with
Algorithms, Elba, June 1998.
Proceedings in Informatics 4, Carleton Scientific, Waterloo, Canada, 1999,
pp. 32–42.
Origami3: Proc. 3rd
Int. Mtg. Origami Science, Math, and Education (Asilomar,
California, 2001), A K Peters, 2002, pp. 17–28.
We apply techniques from "Quadrilateral meshing by circle packing" to a magic trick of Houdini: fold a piece of paper so that with one straight cut, you can form your favorite polygon.
Parametric and kinetic minimum spanning trees.
P. K. Agarwal,
D. Eppstein,
L. J. Guibas,
and
M. R. Henzinger.
39th IEEE Symp. Foundations of Comp. Sci., 1998, pp. 596–605,
doi:10.1109/SFCS.1998.743510.
We describe algorithms for maintaining the minimum spanning tree in a graph in which the edge weights are piecewise linear functions of time that may change unpredictably. We solve the problem in time \(O(n^{2/3}\operatorname{polylog} n)\) per combinatorial change to the tree for general graphs, and in time \(O(n^{1/4}\operatorname{polylog} n)\) per combinatorial change to the tree for planar graphs.
Algorithms for coloring quadtrees.
M. Bern,
D. Eppstein, and
B. Hutchings.
arXiv:cs.CG/9907030.
Algorithmica 32 (1): 87–94, 2002,
doi:10.1007/s00453-001-0054-2.
We consider several variations of the problem of coloring the squares of a quadtree so that no two adjacent squares are colored alike. We give simple linear time algorithms for 3-coloring balanced quadtrees with edge adjacency, 4-coloring unbalanced quadtrees with edge adjacency, and 6-coloring balanced or unbalanced quadtrees with corner adjacency. The number of colors used by the first two algorithms is optimal; for the third algorithm, 5 colors may sometimes be needed.
Incremental and decremental maintenance of planar width.
D. Eppstein.
arXiv:cs.CG/9809038.
10th ACM-SIAM Symp. Discrete Algorithms,
Baltimore, 1999, pp. S899-S900.
J.
Algorithms 37 (2): 570–577, 2000,
doi:10.1006/jagm.2000.1107.
We show how to maintain the width of a planar point set, subject to insertions or deletions (but not both) in time O(nc) per update for any c > 0. The idea is to apply our dynamic closest pair data structure to an appropriate measure of distance between pairs of convex hull features.
Regression depth and center points.
N. Amenta,
M. Bern,
D. Eppstein, and
S.-H. Teng.
arXiv:cs.CG/9809037.
3rd CGC
Worksh. Computational Geometry, Brown Univ., 1998.
Disc. Comp. Geom. 23 (3): 305–323, 2000,
doi:10.1007/PL00009502.
We show that, for any set of \(n\) points in \(d\) dimensions, there exists a hyperplane with regression depth at least \(\lceil n/(d+1)\rceil\), as had been conjectured by Rousseeuw and Hubert. Dually, for any arrangement of \(n\) hyperplanes in \(d\) dimensions there exists a point that cannot escape to infinity without crossing at least \(\lceil n/(d+1)\rceil\) hyperplanes. We also apply our approach to related questions on the existence of partitions of the data into subsets such that a common plane has nonzero regression depth in each subset, and to the computational complexity of regression depth problems.
Guest editor's forward to special issue on dynamic graph algorithms.
D. Eppstein.
Algorithmica 22 (3): 233–234, 1998,
doi:10.1007/PL00009222.
Setting parameters by example.
D. Eppstein.
arXiv:cs.DS/9907001.
40th
IEEE Symp. Foundations of Comp. Sci., 1999, pp. 309–318,
doi:10.1109/SFFCS.1999.814602.
SIAM J. Computing 32 (3): 643–653, 2003,
doi:10.1137/S0097539700370084.
We introduce a class of "inverse parametric optimization" problems, in which one is given both a parametric optimization problem and a desired optimal solution; the task is to determine parameter values that lead to the given solution. We use low-dimensional linear programming and geometric sampling techniques to solve such problems for minimum spanning trees, shortest paths, and other optimal subgraph problems, and discuss applications in multicast routing, vehicle path planning, resource allocation, and board game programming.
The distribution of cycle lengths in graphical models for iterative decoding.
X. Ge,
D. Eppstein, and
P. Smyth.
arXiv:cs.DM/9907002.
Tech.
Rep. 99-10, ICS, UCI, 1999.
IEEE Int. Symp. Information
Theory, Sorrento, Italy, 2000,
doi:10.1109/ISIT.2000.866440.
IEEE Trans. Information Theory 47 (6): 2549–2553, 2001,
doi:10.1109/18.945266.
We compute the expected numbers of short cycles of each length in certain classes of random graphs used for turbocodes, estimate the probability that there are no such short cycles involving a given vertex, and experimentally verify our estimates. The scarcity of short cycles may help explain the empirically observed accuracy of belief-propagation based error-correction algorithms. Note, the TR, conference, and journal versions of this paper have slightly different titles.
Ununfoldable polyhedra.
M. Bern,
E. Demaine,
D. Eppstein,
E. Kuo,
A. Mantler, and
J. Snoeyink.
arXiv:cs.CG/9908003.
Tech. rep.
CS-99-04, Univ. of Waterloo, Dept. of Computer Science, Aug. 1999.
11th Canad. Conf. Comp. Geom., 1999, paper 38.
4th CGC
Worksh. Computational Geometry, Johns Hopkins Univ., 1999.
Comp. Geom. Theory & Applications 24 (2): 51–62, 2003,
doi:10.1016/S0925-7721(02)00091-3 (special
issue for 4th CGC Worksh.).
We prove the existence of polyhedra in which all faces are convex, but which can not be cut along edges and folded flat.
Note variations in different versions: the CCCG one was only Bern, Demain, Eppstein, and Kuo, and the WCG one had the title "Ununfoldable polyhedra with triangular faces". The journal version uses the title "Ununfoldable polyhedra with convex faces" and the combined results from both conference versions.
Hinged dissections of polyominos and polyforms.
E. Demaine,
M. Demaine,
D. Eppstein,
G. Frederickson,
and
E. Friedman.
arXiv:cs.CG/9907018.
11th
Canad. Conf. Comp. Geom., 1999, paper 37.
Computational Geometry: Theory and Applications 31 (3): 237–262, 2005,
doi:10.1016/j.comgeo.2004.12.008
(special issue for 11th CCCG).
We show that, for any n, there exists a mechanism formed by connecting polygons with hinges that can be folded into all possible n-ominos. Similar results hold as well for n-iamonds, n-hexes, and n-abolos.
Emerging challenges in computational topology.
M. Bern,
D. Eppstein, et al.
arXiv:cs.CG/9909001.
This is the report from the ACM Workshop on Computational Topology run by Marshall and myself in Miami Beach, June 1999. It details goals, current research, and recommendations in this emerging area of collaboration between computer science and mathematics.
Tangent spheres and triangle centers.
D. Eppstein.
arXiv:math.MG/9909152.
Amer. Math. Monthly 108 (1): 63–66, 2001,
doi:10.1080/00029890.2001.11919724,
jstor:2695679.
Any four mutually tangent spheres determine three coincident lines through opposite pairs of tangencies. As a consequence, we define two new triangle centers. These centers arose as part of a compass-and-straightedge construction of Soddy circles; also available are some Mathematica calculations of trilinear coordinates for the new triangle centers.
Multivariate regression depth.
M. Bern
and D. Eppstein.
arXiv:cs.CG/9912013.
16th ACM Symp. Comp. Geom., Hong Kong, 2000, pp. 315–321,
doi:10.1145/336154.336218.
Disc. Comp. Geom. 28 (1): 1–17, 2002,
doi:10.1007/s00454-001-0092-1.
We generalize regression depth to k-flats. The k=0 case gives the classical notion of center points. We prove that for any set of n points in Rd there always exists a k-flat with depth at least a constant fraction of n. As a consequence, we derive a linear-time (1+epsilon)-approximation algorithm for the deepest flat. The full version of this paper also includes results from "Computing the depth of a flat".
Searching for spaceships.
D. Eppstein.
arXiv:cs.AI/0004003.
MSRI Combinatorial Game Theory Research Worksh., July 2000.
More Games of No Chance,
R. J. Nowakowski, ed., MSRI Publications 42, pp. 433–453.
We describe software that searches for spaceships in Conway's Game of Life and related two-dimensional cellular automata. Our program searches through a state space related to the de Bruijn graph of the automaton, using a method that combines features of breadth first and iterative deepening search, and includes fast bit-parallel graph reachability and path enumeration algorithms for finding the successors of each state. Successful results include a new 2c/7 spaceship in Life, found by searching a space with 2^126 states.
Graphs for dynamic geometry.
D. Eppstein.
Invited talk,
Worksh. Dynamic Graph Algorithms, Victoria, Canada, 2000.
This talk surveys work on computational geometry algorithms that use dynamic graph data structures, and the different kinds of geometric graph arising in this work.
3-coloring in time O(1.3289^n).
R. Beigel
and D. Eppstein.
arXiv:cs.DS/0006046.
J. Algorithms
54:2 (2005) 168-204, doi:10.1016/j.jalgor.2004.06.008.
Journal paper combining 3-coloring algorithms from our FOCS '95 paper with improved bounds from our SODA '01 paper.
One-dimensional peg solitaire, and duotaire.
C. Moore
and D. Eppstein.
arXiv:math.CO/0006067 and
math.CO/0008172.
MSRI Combinatorial Game Theory Research Worksh., July 2000.
Santa Fe Inst. working paper 00-09-050, September 2000.
More Games of No Chance,
R. J. Nowakowski, ed., MSRI Publications 42, pp. 341–350.
We describe by a regular expression the one-dimensional peg-solitaire positions reducible to a single peg, and provide a linear-time algorithm (based on finding shortest paths in an associated DAG) for reducing any such position to the minimum number of pegs. We then investigate impartial games in which players alternate peg solitaire moves in an attempt to be the one to move last.
(Cris' MSRI talk on streaming video – Cris' publications page)
Phutball endgames are hard.
E. Demaine,
M. Demaine,
and D. Eppstein.
arXiv:cs.CC/0008025.
More Games of No Chance,
R. J. Nowakowski, ed., MSRI Publications 42, pp. 351–360.
We show that, in John Conway's board game Phutball (or Philosopher's Football), it is \(\mathsf{NP}\)-complete to determine whether the current player has a move that immediately wins the game. In contrast, the similar problems of determining whether there is an immediately winning move in checkers, or a move that kings a man, are both solvable in polynomial time.
Fast approximation of centrality.
D. Eppstein and
J. Wang.
arXiv:cs.DS/0009005.
12th ACM-SIAM Symp. Discrete Algorithms,
Washington, 2001, pp. 228–229.
J. Graph Algorithms & Applications 8 (1): 39–45, 2004, doi:10.7155/jgaa.00081.
We use random sampling to quickly estimate, for each vertex in a graph, the average distance to all other vertices.
Improved algorithms for 3-coloring, 3-edge-coloring, and constraint
satisfaction.
D. Eppstein.
arXiv:cs.DS/0009006.
12th ACM-SIAM Symp. Discrete Algorithms,
Washington, 2001, pp. 329–337.
Summarizes recent improvements to "3-Coloring in time O(1.3446n): a no-MIS algorithm". Merged with that paper for the journal version.
Computing the depth of a flat.
M. Bern
and D. Eppstein.
arXiv:cs.CG/0009024.
12th ACM-SIAM Symp. Discrete Algorithms,
Washington, 2001, pp. 700–701.
We compute the regression depth of a k-flat in a set of n d-dimensional points, in time O(nd-2), an order of magnitude faster than the best known algorithms for computing the depth of a point or of a hyperplane. The results from this conference paper have been merged into the full version of "Multivariate Regression Depth".
Internet packet filter management and rectangle geometry.
D. Eppstein and S. Muthukrishnan.
arXiv:cs.CG/0010018.
12th ACM-SIAM Symp. Discrete Algorithms,
Washington, 2001, pp. 827–835.
Rule sets for internet routers and firewalls can be represented as sets of prioritized rectangles; the rule to use for a packet is the maximum priority rectangle containing its (source,destination) address pair. We develop efficient data structures for performing these queries, and find an O(n3/2) time algorithm for testing whether a rule set contains any ambiguities.
Small maximal independent sets and faster exact graph coloring.
D. Eppstein.
arXiv:cs.DS/0011009.
7th Worksh. Algorithms and Data
Structures, Providence, Rhode
Island, 2001.
Springer, Lecture
Notes in Comp. Sci. 2125, 2001, pp. 462–470,
doi:10.1007/3-540-44634-6_42.
J. Graph
Algorithms and Applications 7 (2): 131–140, 2003,
doi:10.7155/jgaa.00064
(special issue for WADS'01).
We show that any graph can be colored in time O(2.415n), by a dynamic programming procedure in which we extend partial colorings on subsets of the vertices by adding one more color for a maximal independent set. The time bound follows from limiting our attention to maximal independent subsets that are small relative to the previously colored subset, and from bounding the number of small maximal independent subsets that can occur in any graph.
(WADS'01 independent set proceedings version -- WADS'01 independent set talk slides)
Optimal Möbius transformations for information visualization
and meshing.
M. Bern
and D. Eppstein.
arXiv:cs.CG/0101006.
7th Worksh. Algorithms and Data
Structures, Providence, Rhode
Island, 2001.
Springer, Lecture
Notes in Comp. Sci. 2125, 2001, pp. 14–25, doi:10.1007/3-540-44634-6_3.
We give linear-time quasiconvex programming algorithms for finding a Möbius transformation of a set of spheres in a unit ball or on the surface of a unit sphere that maximizes the minimum size of a transformed sphere. We can also use similar methods to maximize the minimum distance among a set of pairs of input points. We apply these results to vertex separation and symmetry display in spherical graph drawing, viewpoint selection in hyperbolic browsing, and element size control in conformal structured mesh generation.
(WADS'01 Möbius proceedings version -- WADS'01 Möbius talk slides)
Optimization over zonotopes and training support vector machines.
M. Bern
and D. Eppstein.
arXiv:cs.CG/0105017.
7th Worksh. Algorithms and Data
Structures, Providence, Rhode
Island, 2001.
Springer, Lecture
Notes in
Comp. Sci. 2125, 2001, pp. 111–121,
doi:10.1007/3-540-44634-6_11.
We use the ellipsoid method to develop (theoretically) efficient algorithms for optimizing linear functions on intersections of zonotopes, and show how to apply this to train soft-margin support vector classifiers.
(WADS'01 zonotope proceedings version -- WADS'01 zonotope talk slides)
Hinged kite mirror dissection.
D. Eppstein.
arXiv:cs.CG/0106032.
We show that any polygon can be cut into kites, connected into a chain by hinges at their vertices, and that this hinged assemblage can be unfolded and refolded to form the mirror image of the polygon.
Vertex-unfoldings of simplicial manifolds.
E. Demaine,
D. Eppstein,
J. Erickson,
G. Hart, and
J. O'Rourke.
Tech. Reps. 071 and 072, Smith College, 2001.
arXiv:cs.CG/0107023 and
cs.CG/0110054.
18th ACM Symp. Comp. Geom., Barcelona, 2002, pp. 237–243,
doi:10.1145/513400.513429.
Discrete Geometry: In honor of W. Kuperberg's 60th birthday,
Pure and Appl. Math. 253, Marcel Dekker, pp. 215–228, 2003.
We unfold any polyhedron with triangular faces into a planar layout in which the triangles are disjoint and are connected in a sequence from vertex to vertex
Topological issues in hexahedral meshing.
D. Eppstein.
Invited talk at
Conf. Algebraic
Topology Methods in Computer Science, Stanford, 2001.
We consider the problem of subdividing a polyhedral domain in R^3 into cuboids meeting face-to-face. For topological subdivisions (cell complexes in which each cell is combinatorially equivalent to a cube, but may not be embedded as a polyhedron) and simply-connected domains, a simple necessary and sufficient condition for the existence of a hexahedral mesh is known: a domain with quadrilateral faces can be meshed if and only if there is an even number of faces. However, conditions for the existence of polyhedral meshes remain open, as do the topological versions of the problem for more complicated domain topologies.
Flipping cubical meshes.
M. Bern
D. Eppstein, and
J. Erickson.
arXiv:cs.CG/0108020.
10th Int. Meshing Roundtable, Newport Beach, 2001, pp. 19–29.
Engineering with Computers 18 (3): 173–187, 2002,
doi:10.1007/s003660200016.
We examine flips in which a set of mesh cells connected in a similar pattern to a subset of faces of a cube or hypercube is replaced by cells in the pattern of the complementary subset. We show that certain flip types preserve geometric realizability of a mesh, and use this to study the question of whether every topologically meshable domain is geometrically meshable. We also study flip graph connectivity, and prove that the flip graph of quadrilateral meshes has exactly two connected components.
Note that the Meshing Roundtable version was by Bern and Eppstein. Erickson was added as a co-author during the revisions for the journal version.
Triangles and squares.
D. Eppstein.
Invited talk at EuroConf. Combinatorics, Graph Theory, and Applications,
Bellaterra, Spain, 2001, p. 114.
Which unit-side-length convex polygons can be formed by packing together unit squares and unit equilateral triangles? For instance one can pack six triangles around a common vertex to form a regular hexagon. It turns out that there is a pretty set of 11 solutions. We describe connections from this puzzle to the combinatorics of 3- and 4-dimensional polyhedra, using illustrations from the works of M. C. Escher and others.
Separating geometric thickness from book thickness.
D. Eppstein.
arXiv:math.CO/0109195.
We show that geometric thickness and book thickness are not asymptotically equivalent: for every \(t\), there exists a graph with geometric thickness two and book thickness \(\ge t\).
The minimum expectation selection problem.
D. Eppstein and
G. Lueker.
10th Int. Conf. Random Structures and Algorithms, Poznan, Poland, August
2001.
arXiv:cs.DS/0110011.
Random Structures and Algorithms 21: 278–292, 2002,
doi:10.1002/rsa.10061.
We define the min-min expectation selection problem (resp. max-min expectation selection problem) to be that of selecting k out of n given discrete probability distributions, to minimize (resp. maximize) the expectation of the minimum value resulting when independent random variables are drawn from the selected distributions. Such problems can be viewed as a simple form of two-stage stochastic programming. We show that if d, the number of values in the support of the distributions, is a constant greater than 2, the min-min expectation problem is \(\mathsf{NP}\)-complete but admits a fully polynomial time approximation scheme. For d an arbitrary integer, it is \(\mathsf{NP}\)-hard to approximate the min-min expectation problem with any constant approximation factor. The max-min expectation problem is polynomially solvable for constant d; we leave open its complexity for variable d. We also show similar results for binary selection problems in which we must choose one distribution from each of n pairs of distributions.
Global optimization of mesh quality.
D. Eppstein.
Tutorial at
10th Int. Meshing Roundtable, Newport Beach, 2001.
Delaunay triangulation has been a staple of triangular mesh generation for a long time. Why? As well as being simple, fast, and visually pleasing, Delaunay triangulations can be shown to be optimal for various measures of mesh quality; for instance, they avoid sharp angles to the maximum extent possible. We review these and other results on construction of meshes that optimize given quality measures, including recent work on postprocessing tetrahedral meshes to eliminate slivers.
A steady state model for graph power laws.
D. Eppstein and
J. Wang.
2nd Int.
Worksh. Web Dynamics, Honolulu, 2002.
arXiv:cs.DM/0204001.
We propose a random graph model that (empirically) appears to have a power law degree distribution. Unlike previous models, our model is based on a Markov process rather than incremental growth. We compare our model with others in its ability to predict web graph clustering behavior.
Fat 4-polytopes and fatter 3-spheres.
D. Eppstein,
G. Kuperberg,
and
G. Ziegler.
arXiv:math.CO/0204007.
Discrete Geometry: In honor of W. Kuperberg's 60th birthday,
Pure and Appl. Math. 253, Marcel Dekker, pp. 239–265, 2003.
We introduce the fatness parameter of a 4-dimensional polytope \(P\), \((f_1+f_2)/(f_0+f_3)\). It is open whether all 4-polytopes have bounded fatness. We describe a hyperbolic geometry construction that produces 4-polytopes with fatness > 5.048, as well as the first infinite family of 2-simple, 2-simplicial 4-polytopes and an improved lower bound on the average kissing number of finite sphere packings in \(\mathbb{R}^3\). We show that fatness is not bounded for the more general class of strongly regular CW decompositions of the 3-sphere.
Separating thickness from geometric thickness.
D. Eppstein.
arXiv:math.CO/0204252.
10th Int. Symp. Graph Drawing, Irvine, 2002.
Springer, Lecture Notes in
Comp. Sci. 2528, 2002, pp. 150–161,
doi:10.1007/3-540-36151-0_15.
In Towards a Theory of Geometric Graphs, AMS, 2004, Contemporary
Math 342, J. Pach, ed., pp. 75–86,
doi:10.1090/conm/342/06132.
We show that thickness and geometric thickness are not asymptotically equivalent: for every t, there exists a graph with thickness three and geometric thickness > t. The proof uses Ramsey-theoretic arguments similar to those in "Separating book thickness from thickness".
Algorithms for media.
D. Eppstein and
J.-C. Falmagne.
arXiv:cs.DS/0206033.
Int.
Conf. Ordinal and Symbolic Data Analysis, Irvine, 2003.
Discrete Applied Mathematics 156 (8): 1308–1320, 2008,
doi:10.1016/j.dam.2007.05.035.
Falmagne recently introduced the concept of a medium, a combinatorial object encompassing hyperplane arrangements, topological orderings, acyclic orientations, and many other familiar structures. We find efficient solutions for several algorithmic problems on media: finding short reset sequences, shortest paths, testing whether a medium has a closed orientation, and listing the states of a medium given a black-box description.
Möbius-invariant natural neighbor interpolation.
M. Bern
and D. Eppstein.
arXiv:cs.CG/0207081.
14th ACM-SIAM Symp. Discrete Algorithms,
Baltimore, 2003, pp. 128–129.
Natural neighbor interpolation is a well-known technique for fitting a surface to scattered data, with some nice properties including smoothness everywhere except the data and exact fitting of linear functions. The interpolated surface is formed from a weighted combination of data values at the "natural neighbors" (neighbors in the Delaunay triangulation), with weights related to Voronoi cell areas. We describe a variation of natural neighbor interpolation, using different weights based on Delaunay circle angles, that remains invariant when the data is transformed by Möbius transformations, and reconstructs harmonic functions in the limit of dense data on a circle.
Dynamic generators of topologically embedded graphs.
D. Eppstein.
arXiv:cs.DS/0207082.
14th ACM-SIAM Symp. Discrete Algorithms,
Baltimore, 2003, pp. 599–608.
We describe a decomposition of graphs embedded on 2-dimensional manifolds into three subgraphs: a spanning tree, a dual spanning tree, and a set of leftover edges with cardinality determined by the genus of the manifold. This tree-cotree decomposition allows us to find efficient data structures for dynamic graphs (allowing updates that change the surface), better constants in bounded-genus graph separators, and efficient algorithms for tree-decomposition of bounded-genus bounded-diameter graphs.
Reference caching using unit distance redundant codes for
activity reduction on address buses.
D. Eppstein and
T. Givargis.
Worksh. Embedded System
Codesign (ESCODES'02), San Jose, 2002, pp. 43–48.
J. Microprocessors
& Microsystems 29 (4): 145–153, 2005,
doi:10.1016/j.micpro.2004.08.001.
We study the problem of minimizing transitions in address signals on a bus. The UDRC part of the title refers to an algorithm for coding signals with at most one transition per signal (using an increased number of wires); we combine this with a scheme for caching previously coded addresses and use trace data to compare our technique with previous approaches.
Optimized color gamuts for tiled displays.
M. Bern
and D. Eppstein.
arXiv:cs.CG/0212007.
19th ACM Symp. Comp. Geom., San Diego, 2003, pp. 274–281,
doi:10.1145/777792.777834.
We consider the problem of finding a large color space that can be generated by all units in multi-projector tiled display systems. Viewing the problem geometrically as one of finding a large parallelepiped within the intersection of multiple parallelepipeds, and using colorimetric principles to define a volume-based objective function for comparing feasible solutions, we develop an algorithm for finding the optimal gamut in time \(O(n^3)\), where \(n\) denotes the number of projectors in the system. We also discuss more efficient quasiconvex programming algorithms for alternative objective functions based on maximizing the quality of the color space extrema.
Confluent drawings: visualizing non-planar diagrams in a planar way.
M. Dickerson,
D. Eppstein,
M. T. Goodrich,
and
J. Meng.
arXiv:cs.CG/0212046.
11th Int. Symp. Graph Drawing, Perugia, Italy, 2003.
Springer, Lecture Notes in
Comp. Sci. 2912, 2004, pp. 1–12,
doi:10.1007/978-3-540-24595-7_1.
J. Graph
Algorithms and Applications
(special issue for GD'03) 9 (1): 31–52, 2005,
doi:10.7155/jgaa.00099.
We describe a new method of drawing graphs, based on allowing the edges to be merged together and drawn as "tracks" (similar to train tracks). We present heuristics for finding such drawings based on my previous algorithms for finding maximal bipartite subgraphs, prove that several important families of graphs have confluent drawings, and provide examples of other graphs that can not be drawn in this way.
Möbius transformations in scientific computing.
D. Eppstein.
Talk at SIAM Conf. on Computational Science and
Engineering, San Diego, 2003.
This talk, for the CSE session on combinatorial scientific computing, surveys my work with Marshall Bern on optimal Möbius transformation and Möbius-invariant natural neighbor transformation.
Tiling space and slabs with acute tetrahedra.
D. Eppstein,
J. M. Sullivan,
and A. Üngör.
arXiv:cs.CG/0302027.
Comp. Geom. Theory & Applications 27 (3): 237–255, 2004,
doi:10.1016/j.comgeo.2003.11.003.
We show it is possible to triangulate three-dimensional space using only tetrahedra with acute dihedral angles. We present several constructions to achieve this, including one in which all dihedral angles are less than 77.08 degrees, and another which tiles a slab in space.
The traveling salesman problem for cubic graphs.
D. Eppstein.
arXiv:cs.DS/0302030.
8th Worksh. Algorithms and Data
Structures, Ottawa, 2003.
Springer, Lecture Notes in
Comp. Sci. 2748, 2003, pp. 307–318,
doi:10.1007/978-3-540-45078-8_27.
J. Graph Algorithms and Applications 11 (1): 61–81,
2007, doi:10.7155/jgaa.00137.
We find improved exponential-time algorithms for exact solution of the traveling salesman problem on graphs of maximum degree three and four. We also consider related problems including counting the number of Hamiltonian cycles in such graphs.
The case analysis for the cycle-listing algorithm is missing a case, and the algorithms for both finding the minimum-weight Hamiltonian cycle and listing all Hamiltonian cycles in cubic graphs have been improved by others; see my blog post "Cubic salespeople revisited" for details.
Lazy algorithms for dynamic closest pair with arbitrary distance
measures.
J. Cardinal and
D. Eppstein.
Tech. Rep. 502,
Univ. Libre de Bruxelles, Computer Science Dept., 2003.
Worksh. Algorithm Engineering and
Experiments (ALENEX), New Orleans, 2004, pp. 112–119.
We modify my previous data structures for dynamic closest pairs, to use a lazy deletion mechanism, and show in experiments that the results are an improvement on the unmodified structures.
Quasiconvex analysis of backtracking algorithms.
D. Eppstein.
arXiv:cs.DS/0304018.
15th ACM-SIAM Symp. Discrete Algorithms,
New Orleans, 2004, pp. 781–790.
ACM Trans. Algorithms 2 (4): 492–509 (special issue for SODA 2004), 2006, doi:10.1145/1198513.1198515.
We consider a class of multivariate recurrences frequently arising in the worst case analysis of Davis-Putnam-style exponential time backtracking algorithms for \(\mathsf{NP}\)-hard problems. We describe a technique for proving asymptotic upper bounds on these recurrences, by using a suitable weight function to reduce the problem to that of solving univariate linear recurrences; show how to use quasiconvex programming to determine the weight function yielding the smallest upper bound; and prove that the resulting upper bounds are within a polynomial factor of the true asymptotics of the recurrence. We develop and implement a multiple-gradient descent algorithm for the resulting quasiconvex programs, using a real-number arithmetic package for guaranteed accuracy of the computed worst case time bounds.
The journal version uses the longer title "Quasiconvex analysis of multivariate recurrence equations for backtracking algorithms".
Depth and arrangements.
D. Eppstein.
Invited talk at DIMACS Worksh. on Data Depth, New Brunswick, NJ, 2003.
Invited
talk at MSRI Introductory Worksh. Discrete & Computational Geometry,
Berkeley, CA, 2003.
Surveys projective duality and its uses in algorithms for robust regression. The MSRI talk used the alternative title "Computational geometry and robust statistics" but contained essentially the same content.
(DIMACS'03 depth talk slides – video and slides of MSRI talk)
Quasiconvex programming.
D. Eppstein.
Invited talk at DIMACS Worksh. on Geometric Optimization, New Brunswick,
NJ, 2003.
Plenary talk at ALGO 2004,
Bergen, Norway, 2004.
arXiv:cs.CG/0412046.
Combinatorial and Computational Geometry, Goodman, Pach, and
Welzl, eds., MSRI Publications 52, 2005, pp. 287–331.
Defines quasiconvex programming, a form of generalized linear programming in which one seeks the point minimizing the pointwise maximum of a collection of quasiconvex functions. Surveys algorithms for solving quasiconvex programs either numerically or via generalizations of the dual simplex method from linear programming, and describe varied applications of this geometric optimization technique in meshing, scientific computation, information visualization, automated algorithm analysis, and robust statistics.
(DIMACS'03 quasiconvex programming talk slides – ALGO talk slides)
Guest editor's forward.
D. Eppstein.
Disc. Comp. Geom. 30: 1–2, 2003
(special issue for 17th Symp. Comp. Geom.)
Testing bipartiteness of geometric intersection graphs.
D. Eppstein.
arXiv:cs.CG/0307023.
15th ACM-SIAM Symp. Discrete Algorithms,
New Orleans, 2004, pp. 853–861.
ACM Trans. Algorithms 5(2):15, 2009, doi:10.1145/1497290.1497291.
We consider problems of partitioning sets of geometric objects into two subsets, such that no two objects within the same subset intersect each other. Typically, such problems can be solved in quadratic time by constructing the intersection graph and then applying a graph bipartiteness testing algorithm; we achieve subquadratic times for general objects, and O(n log n) times for balls in R^d or simple polygons in the plane, by using geometric data structures, separator based divide and conquer, and plane sweep techniques, respectively. We also contrast the complexity of bipartiteness testing with that of connectivity testing, and provide evidence that for some classes of object, connectivity is strictly harder due to a computational equivalence with Euclidean minimum spanning trees.
Deterministic sampling and range counting in geometric data streams.
A. Bagchi,
A. Chaudhary,
D. Eppstein, and
M. T. Goodrich.
arXiv:cs.CG/0307027.
20th ACM Symp. Comp. Geom., Brooklyn, 2004, pp. 144–151,
doi:10.1145/997817.997842.
ACM Trans. Algorithms 3(2):A16, 2007, doi:10.1145/1240233.1240239.
We describe an efficient streaming-model construction of epsilon-nets and epsilon-approximations, and use it to find deterministic streaming-model approximation algorithms for iceberg range queries and for various robust statistics problems.
Selected open problems in graph drawing.
F. J. Brandenburg,
D. Eppstein,
M. T. Goodrich,
S. G. Kobourov,
G. Liotta,
and
P. Mutzel.
11th Int. Symp. Graph Drawing, Perugia, Italy, 2003.
Springer, Lecture Notes in
Comp. Sci. 2912, 2004, pp. 515–539,
doi:10.1007/978-3-540-24595-7_55.
We survey a number of open problems in theoretical and applied graph drawing.
Uninscribable four-regular polyhedron.
M. Dillencourt
and D. Eppstein.
Electronic Geometry Models 2003.08.001.
We find an example of a three-dimensional polyhedron, with four edges per vertex, that can not be placed in convex position with all vertices on the surface of a sphere.
Hyperbolic geometry, Möbius transformations, and geometric optimization.
D. Eppstein.
Invited
talk at MSRI Introductory Worksh. Discrete & Computational Geometry,
Berkeley, CA, 2003.
Describes extensions of computational geometry algorithms to hyperbolic geometry, including an output-sensitive 3d Delaunay triangulation algorithm of Boissonat et al. and my own research on optimal Möbius transformation.
The geometric thickness of low degree graphs.
C. Duncan,
D. Eppstein, and
S. Kobourov.
arXiv:cs.CG/0312056.
20th ACM Symp. Comp. Geom., Brooklyn, 2004, pp. 340–346,
doi:10.1145/997817.997868.
We show that graphs with maximum degree four have geometric thickness at most two, by partitioning them into degree two subgraphs and applying simultaneous embedding techniques.
Single-strip triangulation of manifolds with arbitrary topology.
D. Eppstein and
M. Gopi.
13th Video Review of
Computational Geometry, 2004.
20th ACM Symp. Comp. Geom., Brooklyn, 2004, pp. 455–456,
doi:10.1145/997817.997888
(abstract for video).
25th Conf. Eur. Assoc. for Computer Graphics (EuroGraphics '04),
Grenoble, 2004 (2nd best paper award).
Computer Graphics Forum 23 (3): 371–379, 2004,
doi:10.1111/j.1467-8659.2004.00768.x.
arXiv:cs.CG/0405036.
We describe a new algorithm, based on graph matching, for subdividing a triangle mesh (without boundary) so that it has a Hamiltonian cycle of triangles, and prove that this subdivision process increases the total number of triangles in the mesh by at most a factor of 3/2. We also prove lower bounds on the increase needed for meshes with and without boundary.
The effect of faults on network expansion.
A. Bagchi,
A. Bhargava,
A. Chaudhary,
D. Eppstein, and
C. Scheideler.
arXiv:cs.DC/0404029.
16th ACM
Symp. Parallelism in Algorithms and Architectures,
Barcelona, 2004, pp. 286–293,
doi:10.1145/1007912.1007960.
Theory of
Computing Systems 39 (6): 903–928, 2006,
doi:10.1007/s00224-006-1349-0.
Studies the resilience of distributed computation networks against adversarial and random fault models; shows that, in both models, certain networks can withstand constant fault probabilities and still contain a large subnetwork with similar expansion to the original.
The lattice dimension of a graph.
D. Eppstein.
arXiv:cs.DS/0402028.
Eur. J. Combinatorics 26 (6): 585–592, 2005, doi:10.1016/j.ejc.2004.05.001.
Describes a polynomial time algorithm for isometrically embedding graphs into an integer lattice of the smallest possible dimension. The technique involves maximum matching in an auxiliary graph derived from a partial cube representation of the input.
Algorithms for drawing media.
D. Eppstein.
arXiv:cs.DS/0406020.
12th Int. Symp. Graph Drawing, New York, 2004.
Springer, Lecture Notes in Comp. Sci. 3383, 2004, pp. 173–183,
doi:10.1007/978-3-540-31843-9_19.
We describe two algorithms for finding planar layouts of partial cubes: one based on finding the minimum-dimension lattice embedding of the graph and then projecting the lattice onto the plane, and the other based on representing the graph as the planar dual to a weak pseudoline arrangement.
Due to editorial mishandling there will be no journal version of this paper: I submitted it to a journal in 2004, the reviews were supposedly sent back to me in 2005, but I didn't receive them and didn't respond to them, leading the editors to assume that I intended to withdraw the submission. Large portions of the paper have since been incorporated into my book Media Theory, making journal publication moot.
Confluent layered drawings.
D. Eppstein,
M. T. Goodrich,
and
J. Meng.
12th Int. Symp. Graph Drawing, New York, 2004.
Springer, Lecture Notes in Comp. Sci. 3383, 2004, pp. 184–194,
doi:10.1007/978-3-540-31843-9_20.
arXiv:cs.CG/0507051.
Algorithmica 47 (4): 439–452 (special issue for Graph Drawing), 2007, doi:10.1007/s00453-006-0159-8.
Describes a graph drawing technique combining ideas of confluent drawing with Sugiyama-style layered drawing. Uses a reduction to graph coloring to find and visualize sets of bicliques in each layer.
All maximal independent sets and dynamic dominance for sparse
graphs.
D. Eppstein.
arXiv:cs.DS/0407036.
16th ACM-SIAM Symp. Discrete Algorithms,
Vancouver, 2005, pp. 451–459.
ACM Trans. Algorithms 5(4):A38, 2009, doi:10.1145/1597036.1597042.
We show how to apply reverse search to list all maximal independent sets in bounded-degree graphs in constant time per set, in graphs from minor closed families in linear time per set, and in sparse graphs in subquadratic time per set. The latter two results rely on new data structures for maintaining a dynamic vertex set in a graph and quickly testing whether the set dominates all other vertices.
Minimum dilation stars.
D. Eppstein and
K. Wortman.
arXiv:cs.CG/0412025.
21st ACM Symp. Comp. Geom., Pisa, 2005, pp. 321–326,
doi:10.1145/1064092.1064142.
Comp. Geom. Theory & Applications 37 (1): 27–37, 2007, doi:10.1016/j.comgeo.2006.05.007.
We show how to test the dilation of a star, embedded in a Euclidean space of bounded dimension, in time \(O(n\log n)\), and how to find the star center that has the minimum dilation for a given set of leaf points in randomized expected time \(O(n\log n)\). For two-dimensional points, we can find the minimum dilation center, constrained to be one of the input points, in time The unconstrained center placement algorithm involves quasiconvex programming, and is used as a subroutine in the constrained center placement algorithm.
Comment on "Location-Scale Depth".
D. Eppstein.
J. Amer. Stat. Assoc. 99 (468): 976–979, 2004,
doi:10.1198/016214504000001358,
jstor:27590478.
Discusses a paper by Mizera and Müller on depth-based methods for simultaneously fitting both a center and a radius to a set of sample points, by viewing the points as lying on the boundary of a model of a higher dimensional hyperbolic space. Reformulates their method in combinatorial terms more likely to be familiar to computational geometers, and discusses the algorithmic implications of their work.
Improved combinatorial group testing for
real-world problem sizes.
D. Eppstein,
M. T. Goodrich,
and D. S. Hirschberg.
9th Worksh. Algorithms and Data Structures, Waterloo, 2005.
Springer, Lecture Notes in Comp. Sci. 3608, 2005, pp. 86–98,
doi:10.1007/11534273_9.
arXiv:cs.DS/0505048.
SIAM J. Computing 36 (5): 1360–1375, 2007,
doi:10.1137/050631847.
We study practically efficient methods for finding few flawed items among large sets of items, by testing whether there exist flaws in each of a small number of batches of items.
The skip quadtree: a simple dynamic data structure
for multidimensional data.
D. Eppstein,
M. T. Goodrich,
and
J. Z. Sun.
21st ACM Symp. Comp. Geom., Pisa, 2005, pp. 296–305,
doi:10.1145/1064092.1064138.
arXiv:cs.CG/0507049.
Int. J. Comp. Geom. & Appl. 18(1-2): 131–160, 2008,
doi:10.1142/S0218195908002568.
We describe a data structure consisting of a sequence of compressed quadtrees for successively sparser samples of an input point set, with connections between the same squares in successive members of the sequence. Using this structure, we can insert or delete points and answer approximate range queries and approximate nearest neighbor queries in O(log n) time per operation.
Skip-webs: efficient distributed data structures for
multi-dimensional data sets.
L. Arge,
D. Eppstein,
and
M. T. Goodrich.
Proc. 24th ACM SIGACT-SIGOPS Symp. Principles of Distributed Computing
(PODC 2005), Las Vegas, July 2005, pp. 69–76,
doi:10.1145/1073827.
arXiv:cs.DC/0507050.
Describes efficient distributed versions of skip quadtrees and related spatial searching structures.
The weighted maximum-mean subtree and other bicriterion subtree problems.
J. Carlson
and D. Eppstein.
arXiv:cs.CG/0503023.
Proc. 10th Scand. Worksh. Algorithm Theory (SWAT 2006).
Springer, Lecture Notes in Comp. Sci. 4059, 2006, pp. 397–408,
doi:10.1007/11785293_37.
We give a linear time algorithm for pruning a node-weighted tree to maximize the average node weight of the pruned subtree; this problem was previously studied under the less obvious name "The Fractional Prize-Collecting Steiner Tree Problem on Trees".
See also my blog post "Optimal subtrees".
Delta-confluent drawings.
D. Eppstein,
M. T. Goodrich,
and
J. Meng.
13th Int. Symp. Graph Drawing, Limerick, Ireland, 2005.
Springer, Lecture Notes in Comp. Sci. 3843, 2006, pp. 165–176,
doi:10.1007/11618058_16.
arXiv:cs.CG/0510024.
We characterize the graphs that can be drawn confluently with a single confluent track that is tree-like except for three-way Delta junctions, as being exactly the distance hereditary graphs. Based on this characterization, we develop efficient algorithms for drawing these graphs.
Nonrepetitive paths and cycles in graphs with application to Sudoku.
D. Eppstein.
arXiv:cs.DS/0507053.
We describe algorithms and hardness results for finding paths in edge-labeled graphs such that no two consecutive edges have the same label, and use our algorithms to implement heuristics for a program that automatically solves and generates Sudoku puzzles.
Drawings of planar graphs with few slopes and segments.
V. Dujmović,
D. Eppstein,
M. Suderman,
and
D. R. Wood.
arXiv:math.CO/0606450.
Comp.
Geom. Theory & Applications 38: 194–212, 2007,
doi:10.1016/j.comgeo.2006.09.002.
We study straight-line drawings of planar graphs with few segments and few slopes. Optimal results are obtained for all trees. Tight bounds are obtained for outerplanar graphs, 2-trees, and planar 3-trees. We prove that every 3-connected plane graph on n vertices has a plane drawing with at most 5n/2 segments and at most 2n slopes. We prove that every cubic 3-connected plane graph has a plane drawing with three slopes (and three bends on the outerface).
Cubic partial cubes from simplicial arrangements.
D. Eppstein.
arXiv:math.CO/0510263.
Electronic
J. Combinatorics 13(1), Paper R79, 2006,
doi:10.37236/1105.
We show how to construct a cubic partial cube from any simplicial arrangement of lines or pseudolines in the projective plane. As a consequence, we find nine new infinite families of cubic partial cubes as well as many sporadic examples.
Single triangle strip and loop on manifolds with boundaries.
A. Bushan,
P. Diaz-Gutierrez,
D. Eppstein, and
M. Gopi.
Tech. Rep. 05-11, UC Irvine, School of Information and Computer Science,
2005.
Proc. 19th Brazilian Symp. Computer Graphics and Image Processing
(SIBGRAPI 2006), pp. 221–228,
doi:10.1109/SIBGRAPI.2006.41.
This follows on to our previous paper on using graph matching to cover a triangulated polyhedral model with a single triangle strip by extending the algorithms to models with boundaries. We provide two methods: one is based on using an algorithm for the Chinese Postman problem to find a small set of triangles to split in order to find a perfect matching in the dual mesh, while the other augments the model with virtual triangles to remove the boundaries and merges the strips formed by our previous algorithm on this augmented model. We implement the algorithms and report some preliminary experimental results.
Approximate weighted farthest neighbors and minimum dilation stars.
J. Augustine,
D. Eppstein, and
K. Wortman.
arXiv:cs.CG/0602029.
Proc. 16th Annual International Computing and Combinatorics Conference
(COCOON 2010), Nha Trang, Vietnam.
Springer, Lecture Notes in
Comp. Sci. 6196, 2010, pp. 90–99,
doi:10.1007/978-3-642-14031-0_12.
Discrete
Mathematics, Algorithms and Applications 2 (4): 553–565, 2010, doi:10.1142/S1793830910000887.
The problem is to quickly find, in a set of sites with weights, the site maximizing the product of its weight with its distance from the query point. Our solution combines known results on core-sets with a reduction from the weighted to the unweighted problem that works in any metric space. This leads to fast approximation algorithms for the constrained minimum dilation star problem in any fixed dimension.
Guard placement for efficient point-in-polygon proofs.
D. Eppstein,
M. T. Goodrich,
and
N. Sitchinava.
arXiv:cs.CG/0603057.
23rd ACM Symp. Comp. Geom., Gyeongju, South Korea, 2007, pp. 27–36,
doi:10.1145/1247069.1247075.
The problem is to place as few wedges as possible in the plane such that a desired polygon can be formed as some monotone Boolean combination of the wedges. The motivation is for wireless devices to prove that they are located within a target area by their ability to communicate with a subset of base stations (the wedges). We provide upper and lower bounds on the number of wedges needed for several classes of polygons.
Squarepants in a tree: sum of subtree clustering and hyperbolic pants decomposition.
D. Eppstein.
arXiv:cs.CG/0604034.
18th ACM-SIAM Symp. Discrete Algorithms,
New Orleans, 2007, pp. 29–38.
ACM Trans. Algorithms 5(3): Article 29, 2009, doi:10.1145/1541885.1541890.
We find efficient constant factor approximation algorithms for hierarchically clustering of a point set in any metric space, minimizing the sum of minimimum spanning tree lengths within each cluster, and in the hyperbolic or Euclidean planes, minimizing the sum of cluster perimeters. Our algorithms for the hyperbolic and Euclidean planes can also be used to provide a pants decomposition with approximately minimum total length.
Interconnect criticality driven delay relaxation.
L. Singhal,
E. Bozorgzadeh,
and D. Eppstein.
IEEE Trans. CAD 26 (10): 1803–1817, 2007,
doi:10.1109/TCAD.2007.896319.
We consider a problem of assigning delays to components in a circuit so that each component is part of a critical path, but the number of edges belonging to critical paths is minimized. We show the problem to be NP-complete via a reduction from finding independent dominating sets in bipartite graphs minimizing dominated edges, and give experimental results on heuristics.
Upright-quad drawing of \(st\)-planar learning spaces.
D. Eppstein.
arXiv:cs.CG/0607094.
14th Int. Symp. Graph Drawing, Karlsruhe, Germany, 2006.
Springer, Lecture Notes in
Comp. Sci. 4372, 2007, pp. 282–293, doi:10.1007/978-3-540-70904-6_28.
J. Graph Algorithms and Applications 12 (1): 51–72, 2008, doi:10.7155/jgaa.00159 (special
issue for GD'06).
We consider graph drawing algorithms for learning spaces, a type of \(st\)-oriented partial cube derived from antimatroids and used to model states of knowledge of students. We show how to draw any \(st\)-planar learning space so all internal faces are convex quadrilaterals with the bottom side horizontal and the left side vertical, with one minimal and one maximal vertex. Conversely, every such drawing represents an \(st\)-planar learning space. We also describe connections between these graphs and arrangements of translates of a quadrant.
(GD'06 talk slides for "upright-quad drawing" – blog post, "Upright-quad drawing"))
Trees with convex faces and optimal angles.
J. Carlson
and D. Eppstein.
arXiv:cs.CG/0607113.
14th Int. Symp. Graph Drawing, Karlsruhe, Germany, 2006.
Springer, Lecture Notes in
Comp. Sci. 4372, 2007, pp. 77–88, doi:10.1007/978-3-540-70904-6_9.
We consider drawings of trees which, if the leaf edges were extended to infinite rays, would form partitions of the plane into unbounded convex polygons. For such a drawing the edges may be chosen independently without any possibility of edge crossing. We show how to choose the angles of such drawings to optimize the angular resolution of the drawing.
(GD06 talk slides – blog post, "Trees with convex faces and optimal angles")
Choosing colors for geometric graphs via color space embeddings.
M. Dillencourt,
D. Eppstein, and
M. T. Goodrich.
arXiv:cs.CG/0609033.
14th Int. Symp. Graph Drawing, Karlsruhe, Germany, 2006.
Springer, Lecture Notes in
Comp. Sci. 4372, 2007, pp. 294–305, doi:10.1007/978-3-540-70904-6_29.
We show how to choose colors for the vertices of a graph drawing in such a way that all colors are easily distinguishable, but such that adjacent vertices have especially dissimilar colors, by considering the problem as one of embedding the graph into a three-dimensional color space.
(GD'06 talk slides for "choosing colors" – Blog post: A multicolored checkerboard)
Happy endings for flip graphs.
D. Eppstein.
arXiv:cs.CG/0610092.
23rd ACM Symp. Comp. Geom., Gyeongju, South Korea, 2007, pp. 92–101,
doi:10.1145/1247069.1247084.
J. Computational Geometry 1 (1): 3–28, 2010, doi:10.20382/jocg.v1i1a2.
We show that the triangulations of a finite point set form a flip graph that can be embedded isometrically into a hypercube, if and only if the point set has no empty convex pentagon. Point sets of this type include convex subsets of lattices, points on two lines, and several other infinite families. As a consequence, flip distance in such point sets can be computed efficiently.
Manhattan orbifolds.
D. Eppstein.
arXiv:math.MG/0612109.
Topology and
its Applications 157 (2): 494–507, 2009, doi:10.1016/j.topol.2009.10.008.
We investigate a class of metrics for 2-manifolds in which, except for a discrete set of singular points, the metric is locally isometric to an L1 metric, and show that with certain additional conditions such metrics are injective. We use this construction to find the tight span of squaregraphs and related graphs, and we find an injective metric that approximates the distances in the hyperbolic plane analogously to the way the rectilinear metrics approximate the Euclidean distance.
Edges and switches, tunnels and bridges.
D. Eppstein,
M. van Kreveld,
E. Mumford, and
B. Speckmann.
23rd European Workshop on Computational Geometry (EWCG'07), Graz, 2007.
10th Worksh. Algorithms and Data Structures, Halifax, Nova Scotia, 2007,
doi:10.1007/978-3-540-73951-7_8.
Springer, Lecture Notes in Comp. Sci. 4619, 2007, pp. 77–88.
Tech.
Rep. UU-CS-2007-042, Utrecht Univ., Dept. of Information and
Computing Sciences, 2007.
arXiv:0705.0413.
Comp.
Geom. Theory & Applications 42 (8): 790–802, 2009, doi:10.1016/j.comgeo.2008.05.005 (special issue
for EWCG'07).
We show how to solve several versions of the problem of casing graph drawings: that is, given a drawing, choosing to draw one edge as upper and one lower at each crossing in order to improve the drawing's readability.
Space-efficient straggler identification in round-trip data
streams via Newton's identities and invertible Bloom filters.
D. Eppstein, and
M. T. Goodrich.
10th Worksh. Algorithms and Data Structures, Halifax, Nova Scotia, 2007.
Springer, Lecture Notes in Comp. Sci. 4619, 2007, pp. 637–648.
arXiv:0704.3313.
IEEE
Trans. Knowledge and Data Engineering 23 (2): 297–306, 2011, doi:10.1109/TKDE.2010.132.
We consider data structures for handling streams of check-in and check-out requests, and that must identify the set of check-ins that are not matched by a corresponding check-out. We show that, if this set has size k, it is possible to handle this problem in space O(k log n) by a deterministic data structure. However, if check-outs may occur that do not match any check-in, then no low-space deterministic solution is possible; instead, we provide a randomized solution with near-optimal space and high probability of answering queries correctly.
On verifying and engineering the well-gradedness of a
union-closed family.
D. Eppstein,
J.-C. Falmagne,
and
H. Uzun.
arXiv:0704.2919.
38th Meeting of the European Mathematical Psychology Group, Luxembourg, 2007.
J. Mathematical Psychology 53 (1): 34–39, 2009, doi:10.1016/j.jmp.2008.09.002.
We describe tests for whether the union-closure of a set family is well-graded, and algorithms for finding a minimal well-graded union-closed superfamily of a given set family.
Recognizing partial cubes in quadratic time.
D. Eppstein.
arXiv:0705.1025.
19th ACM-SIAM Symp. Discrete Algorithms,
San Francisco, 2008, pp. 1258–1266.
J. Graph Algorithms and Applications 15 (2): 269–293, 2011,
doi:10.7155/jgaa.00226.
We show how to test whether a graph is a partial cube, and if so embed it isometrically into a hypercube, in time O(n2), improving previous O(nm)-time solutions; here n is the number of vertices and m is the number of edges. The ideas are to use bit-parallelism to speed up previous approaches to the embedding step, and to verify that the resulting embedding is isometric using an all-pairs shortest path algorithm from "algorithms for media".
Geometry of partial cubes.
D. Eppstein.
Invited talk at 6th Slovenian International Conference on Graph Theory,
Bled, Slovenia, 2007.
I survey some of my recent results on geometry of partial cubes, including lattice dimension, graph drawing, cubic partial cubes, and partial cube flip graphs of triangulations.
The Complexity of Bendless Three-Dimensional Orthogonal Graph Drawing.
D. Eppstein.
arXiv:0709.4087.
Proc. 16th Int. Symp. Graph Drawing, Heraklion, Crete, 2008.
Springer, Lecture Notes in Comp. Sci. 5417, 2009, pp. 78–89,
doi:10.1007/978-3-642-00219-9_9.
J. Graph Algorithms and Applications 17 (1): 35–55, 2013, doi:10.7155/jgaa.00283.
Defines a class of orthogonal graph drawings formed by a point set in three dimensions for which axis-parallel line contains zero or two vertices, with edges connecting pairs of points on each nonempty axis-parallel line. Shows that the existence of such a drawing can be defined topologically, in terms of certain two-dimensional surface embeddings of the same graph. Based on this equivalence, describes algorithms, graph-theoretic properties, and hardness results for graphs of this type.
Media Theory: Interdisciplinary Applied Mathematics.
D. Eppstein,
J.-C. Falmagne, and
S. Ovchinnikov.
Springer, 2007, ISBN 978-3-540-71696-9,
doi:10.1007/978-3-540-71697-6.
Many combinatorial structures such as the set of acyclic orientations of a graph, weak orderings of a set of elements, or chambers of a hyperplane arrangement have the structure of a partial cube, a graph in which vertices may be labeled by bitvectors in such a way that graph distance equals Hamming distance. This book analyzes these structures in terms of operations that change one vertex to another by flipping a single bit of the bitvector labelings. It incorporates material from several of my papers including "Algorithms for media", "Algorithms for drawing media", "Upright-quad drawing of st-planar learning spaces", and "The Lattice dimension of a graph".
(Publisher's web site – Reinhard Suck's review in J. Math. Psych. – Reinhard Suck's review in MathSciNet)

Learning sequences.
D. Eppstein.
arXiv:0803.4030.
How to implement an antimatroid, with applications in computerized education.
Principles of Graph Drawing.
D. Eppstein.
Talk
at Inst. for Mathematical Behavioral Sciences, May 2008.
Talk at Technical University of Eindhoven, September 2008.
Approximate Topological Matching of Quadrilateral Meshes.
D. Eppstein,
M. T. Goodrich,
E. Kim,
and R. Tamstorf.
Proc. IEEE
Int. Conf. Shape Modeling and Applications (SMI 2008), Stony Brook,
New York, pp. 83–92, doi:10.1109/SMI.2008.4547954.
The Visual Computer
25 (8): 771–783, 2009, doi:10.1007/s00371-009-0363-z.
We formalize problems of finding large approximately-matching regions of two related but not completely isomorphic quadrilateral meshes, show that these problems are \(\mathsf{NP}\)-complete, and describe a natural greedy heuristic that is guaranteed to find good matches when the mismatching parts of the meshes are small.
(Preprint)
Motorcycle graphs: canonical quad mesh partitioning.
D. Eppstein,
M. T. Goodrich,
E. Kim,
and R. Tamstorf.
Proc. 6th Symp. Geometry Processing, Copenhagen, Denmark, 2008.
Computer Graphics Forum 27 (5): 1477–1486, 2008, doi:10.1111/j.1467-8659.2008.01288.x.
We use a construction inspired by the motorcycle graphs previously used in straight skeleton construction, to partition quadrilateral meshes into a small number of structured submeshes. Our construction is canonical in that two copies of the same mesh will always be partitioned in the same way, and can be used to speed up graph isomorphism computations for geometric models in feature animation.
Straight skeletons of three-dimensional polyhedra.
G. Barequet,
D. Eppstein,
M. T. Goodrich, and
A. Vaxman.
arXiv:0805.0022.
Proc. 16th European Symp. Algorithms, Karlsruhe, Germany,
2008.
Springer, Lecture Notes in Comp. Sci. 5193, 2008, pp. 148–160., doi:10.1007/978-3-540-87744-8_13
A straight skeleton is defined by the locus of points crossed by the edges and vertices of a polyhedron as it undergoes a continuous shrinking process in which the faces move inwards at constant speed. We resolve some ambiguities in the definition of these shapes, define efficient algorithms for polyhedra with axis-parallel faces, show that arbitrary polyhedra have strictly more complicated straight skeletons, and report on results from an implementation of our algorithm for arbitrary polyhedra.
Succinct greedy geometric routing using hyperbolic geometry.
D. Eppstein and
M. T. Goodrich.
arXiv:0806.0341.
Proc. 16th Int. Symp. Graph Drawing, Heraklion, Crete, 2008
(under the different title "Succinct greedy graph drawing in the
hyperbolic plane"),
Springer, Lecture Notes in Comp. Sci. 5417, 2009, pp. 14–25,
doi:10.1007/978-3-642-00219-9_3.
IEEE Transactions on Computing 60 (11): 1571–1580, 2011,
doi:10.1109/TC.2010.257.
Greedy drawing is an idea for encoding network routing tables into the geometric coordinates of an embedding of the network, but most previous work in this area has ignored the space complexity of these encoded tables. We refine a method of R. Kleinberg for embedding arbitrary graphs into the hyperbolic plane, which uses linearly many bits to represent each vertex, and show that only logarithmic bits per point are needed.
Isometric diamond subgraphs.
D. Eppstein.
arXiv:0807.2218.
Proc. 16th Int. Symp. Graph Drawing, Heraklion, Crete, 2008.
Springer, Lecture Notes in Comp. Sci. 5417, 2009, pp. 384–389,
doi:10.1007/978-3-642-00219-9_37.
We describe polynomial time algorithms for determining whether an undirected graph may be embedded in a distance-preserving way into the hexagonal tiling of the plane, the diamond structure in three dimensions, or analogous structures in higher dimensions. The graphs that may be embedded in this way form an interesting subclass of the partial cubes.
Studying (non-planar) road networks through an algorithmic lens.
D. Eppstein, and
M. T. Goodrich.
arXiv:0808.3694.
Proc. 16th ACM SIGSPATIAL Int. Conf. Advances in Geographic
Information Systems (ACM GIS 2008), Article 16, doi:10.1145/1463434.1463455 (best paper award).
Invited talk at INFORMS 2009, San Diego.
We examine US road network data and show that, contrary to the assumptions of much past GIS work, these networks are highly nonplanar. We introduce a class of "multiscale dispersed" networks that better fit the data; these networks are defined by a family of disks of varying sizes such that, if a small number of outliers is removed, the remaining disks cover each point of the plane a constant number of times. As we show, these networks have good graph separators, allowing for efficient algorithms for minimum spanning trees, graph Voronoi diagrams, and related problems.
Self-overlapping curves revisited.
D. Eppstein and
E. Mumford.
arXiv:0806.1724.
20th ACM-SIAM Symp. Discrete Algorithms,
New York, 2009, pp. 160–169, doi:10.1137/1.9781611973068.19.
We consider problems of determining when a curve in the plane is the projection of a 3d surface with no vertical tangents. Several problems of this type are \(\mathsf{NP}\)-complete, but can be solved in polynomial time if a casing of the curve is also given.
Linear-time algorithms for geometric graphs with sublinearly many
crossings.
D. Eppstein,
M. T. Goodrich, and
D. Strash.
arXiv:0812.0893.
20th ACM-SIAM Symp. Discrete Algorithms,
New York, 2009, pp. 150–159, doi:10.1137/1.9781611973068.18.
SIAM J. Computing 39 (8): 3814–3829, 2010, doi:10.1137/090759112.
If a connected graph corresponds to a set of points and line segments in the plane, in such a way that the number of crossing pairs of line segments is sublinear in the size of the graph by an iterated-log factor, then we can find the arrangement of the segments in linear time. It was previously known how to find the arrangement in linear time when the number of crossings is superlinear by an iterated-log factor, so the only remaining open case is when the number of crossings is close to the size of the graph.
Finding large clique minors is hard.
D. Eppstein.
arXiv:0807.0007.
J. Graph Algorithms and Applications 13 (2): 197–204, 2009,
doi:10.7155/jgaa.00183.
Proves that it's \(\mathsf{NP}\)-complete to compute the Hadwiger number of a graph.
Planar Voronoi diagrams for sums of convex functions, smoothed
distance and dilation.
M. Dickerson,
D. Eppstein, and
K. Wortman.
arXiv:0812.0607.
7th Int. Symp. Voronoi Diagrams in Science and Engineering (ISVD
2010), Quebec City, Canada, pp. 13–22, doi:10.1109/ISVD.2010.12.
Investigates Voronoi diagrams for a "smoothed distance" in which the distance between two points p and q is inversely weighted by the perimeter of triangle opq for a fixed point o, its relation to dilation of star networks centered at o, and its generalization to minimization diagrams of certain convex functions. When the function to be minimized is suitably well-behaved, its level sets form pseudocircles, the bisectors of the minimization diagram form pseudoline arrangements, and the diagram itself has linear complexity.
Area-universal rectangular layouts.
D. Eppstein,
E. Mumford,
B. Speckmann, and
K. Verbeek.
arXiv:0901.3924.
25th Eur. Worksh. Comp. Geom., Brussels, Belgium, 2009.
25th ACM Symp. Comp. Geom., Aarhus, Denmark, 2009, pp. 267–276, doi:10.1145/1542362.1542411.
A partition of a rectangle into smaller rectangles is "area-universal" if any vector of areas for the smaller rectangles can be realized by a combinatorially equivalent partition. These partitions may be applied, for instance, to cartograms, stylized maps in which the shapes of countries have been distorted so that their areas represent numeric data about the countries. We characterize area-universal layouts, describe algorithms for finding them, and discuss related problems. The algorithms for constructing area-universal layouts are based on the distributive lattice structure of the set of all layouts of a given dual graph.
Merged with "Orientation-constrained rectangular layouts" to form the journal version, "Area-universal and constrained rectangular layouts".
Animating a continuous family of two-site distance function
Voronoi diagrams (and a proof of a complexity bound on the number of
non-empty regions).
M. Dickerson
and D. Eppstein.
25th ACM Symp. Comp. Geom., Aarhus, Denmark, 2009, video and
multimedia track, pp. 92–93, doi:10.1145/1542362.1542380.
We investigate distance from a pair of sites defined as the sum of the distances to each site minus a parameter times the distance between the two sites. A given set of \(n\) sites defines \(n(n-1)/2\) pairs and \(n(n-1)/2\) distances in this way, from which we can determine a Voronoi diagram. As we show, for a wide range of parameters, the diagram has relatively few regions because the pairs that have nonempty Voronoi regions must be Delaunay edges.
The Fibonacci dimension of a graph.
S. Cabello,
D. Eppstein, and
S. Klavžar.
IMFM Preprint
1084, Institute of Mathematics, Physics and Mechanics, Univ. of of
Ljubljana, 2009.
arXiv:0903.2507.
Electronic J. Combinatorics 18(1), Paper P55, 2011, doi:10.37236/542.
We investigate isometric embeddings of other graphs into Fibonacci cubes, graphs formed from the families of fixed-length bitstrings with no two consecutive ones.
The \(h\)-index of a graph and its application to dynamic subgraph statistics.
D. Eppstein and
E. S. Spiro.
arXiv:0904.3741.
Algorithms and Data Structures Symposium (WADS), Banff, Canada.
Springer, Lecture Notes in Comp. Sci. 5664, 2009, pp. 278–289,
doi:10.1007/978-3-642-03367-4_25.
J. Graph
Algorithms and Applications 16 (2): 543–567, 2012, doi:10.7155/jgaa.00273.
We define the \(h\)-index of a graph to be the maximum \(h\) such that the graph has \(h\) vertices each of which has degree at least \(h\). We show that the \(h\)-index, and a partition of the graph into high and low degree vertices, may be maintained in constant time per update. Based on this technique, we show how to maintain the number of triangles in a dynamic graph in time \(O(h)\) per update; this problem is motivated by Markov Chain Monte Caro simulation of the Exponential Random Graph Model used for simulation of social networks. We also prove bounds on the \(h\)-index for scale-free graphs and investigate the behavior of the \(h\)-index on a corpus of real social networks.
On the approximability of geometric and geographic generalization
and the min-max bin covering problem.
W. Du,
D. Eppstein,
M. T. Goodrich,
G. Lueker.
arXiv:0904.3756.
Algorithms and Data Structures Symposium (WADS), Banff, Canada.
Springer, Lecture Notes in Comp. Sci. 5664, 2009, pp. 242–253,
doi:10.1007/978-3-642-03367-4_22.
We investigate several simplified models for k-anonymization in databases, show them to be hard to solve exactly, and provide approximation algorithms for them.
The min-max bin covering problem is closely related to one of our models. An input to this problem consists of a collection of items with sizes and a threshold size. The items must be grouped into bins such that the total size within each bin is at least the threshold, while keeping the maximum bin size as small as possible.
Orientation-constrained rectangular layouts.
D. Eppstein and
E. Mumford.
arXiv:0904.4312.
Algorithms and Data Structures Symposium (WADS), Banff, Canada.
Springer, Lecture Notes in Comp. Sci. 5664, 2009, pp. 266–277,
doi:10.1007/978-3-642-03367-4_24.
We show how to find a stylized map in which regions have been replaced by rectangles, preserving adjacencies between regions, with constraints on the orientations of adjacencies between regions. For an arbitrary dual graph representing a set of adjacencies, and an arbitrary set of orientation constraints, we can determine whether there exists a rectangular map satisfying those constraints in polynomial time. The algorithm is based on a representation of the set of all layouts for a given dual graph as a distributive lattice, and on Birkhoff's representation theorem for distributive lattices.
Merged with "Area-universal rectangular layouts" to form the journal version, "Area-universal and constrained rectangular layouts".
Optimal embedding into star metrics.
D. Eppstein and
K. Wortman.
arXiv:0905.0283.
Algorithms and Data Structures Symposium (WADS), Banff, Canada (best
paper award).
Springer, Lecture Notes in Comp. Sci. 5664, 2009, pp. 290–301,
doi:10.1007/978-3-642-03367-4_26.
We provide an \(O(n^3\log^2 n)\) algorithm for finding a non-distance-decreasing mapping from a given metric into a star metric with as small a dilation as possible. The main idea is to reduce the problem to one of parametric shortest paths in an auxiliary graph. Specifically, we transform the problem into the parametric negative cycle detection problem: given a graph in which the edge weights are linear functions of a parameter \(\lambda\), find the minimum value of \(\lambda\) for which the graph contains no negative cycles. We find a new strongly polynomial time algorithm for this problem, and use it to solve the star metric embedding problem.
Combinatorics and geometry of finite and infinite squaregraphs.
H.-J. Bandelt,
V. Chepoi,
and D. Eppstein.
arXiv:0905.4537.
SIAM J. Discrete Math. 24 (4): 1399–1440, 2010, doi:10.1137/090760301.
Characterizes squaregraphs as duals of triangle-free hyperbolic line arrangements, provides a forbidden subgraph characterization of them, describes an algorithm for finding minimum subsets of vertices that generate the whole graph by medians, and shows that they may be isometrically embedded into Cartesian products of five (but not, in general, fewer than five) trees.
Graph-theoretic solutions to computational geometry problems.
D. Eppstein.
Invited talk, the 35th International
Workshop on Graph-Theoretic Concepts in Computer Science (WG 2009),
Montpellier, France, 2009.
Springer, Lecture Notes in Comp. Sci. 5911, 2009, pp. 1–16,
doi:10.1007/978-3-642-11409-0_1.
arXiv:0908.3916.
We survey problems in computational geometry that may be solved by constructing an auxiliary graph from the problem and solving a graph-theoretic problem on the auxiliary graph. The problems considered include the art gallery problem, partitioning into rectangles, minimum diameter clustering, bend minimization in cartogram construction, mesh stripification, optimal angular resolution, and metric embedding.
Optimal angular resolution for face-symmetric drawings.
D. Eppstein and
K. Wortman.
arXiv:0907.5474.
J. Graph Algorithms and Applications 15 (4): 551–564, 2011,
doi:10.7155/jgaa.00238.
We consider drawings of planar partial cubes in which all interior faces are centrally symmetric convex polygons, as in my previous paper Algorithms for Drawing Media. Among all drawings of this type, we show how to find the one with optimal angular resolution. The solution involves a transformation from the problem into the parametric negative cycle detection problem: given a graph in which the edge weights are linear functions of a parameter λ, find the minimum value of λ for which the graph contains no negative cycles.
Curvature-aware fundamental cycles.
P. Diaz-Gutierrez,
D. Eppstein, and
M. Gopi.
17th Pacific Conf. Computer Graphics and Applications, Jeju, Korea,
2009.
Computer
Graphics Forum 28 (7): 2015–2024, 2009, doi:10.1111/j.1467-8659.2009.01580.x.
Considers heuristic modifications to the tree-cotree decomposition of my earlier paper Dynamic generators of topologically embedded graphs, to make the set of fundamental cycles found as part of the decomposition follow the contours of a given geometric model.
Going off-road: transversal complexity in road networks.
D. Eppstein,
M. T. Goodrich, and
L. Trott.
arXiv:0909.2891.
Proc. 17th ACM
SIGSPATIAL Int. Conf. Advances in Geographic Information Systems,
Seattle, 2009, pp. 23–32, doi:10.1145/1653771.1653778.
Shows both theoretically and experimentally that the number of times a random line crosses a road network is asymptotically upper bounded by the square root of the number of road segments.
Paired approximation problems and incompatible inapproximabilities.
D. Eppstein.
arXiv:0909.1870.
21st ACM-SIAM Symp. Discrete Algorithms, Austin, Texas, 2010,
pp. 1076–1086,
doi:10.1137/1.9781611973075.87.
Considers situations in which two hard approximation problems are presented by means of a single input. In many cases it is possible to guarantee that one or the other problem can be approximated to within a better approximation ratio than is possible for approximating it as a single problem. For instance, it is possible to find either a (1+ε)-approximation to a 1-2 TSP defined from a graph or a nε-approximation to the maximum independent set of the same graph, despite lower bounds showing nonexistence of approximation schemes for 1-2 TSP and nonexistence of approximations better than n1 − ε for independent set. However, for some other pairs of problems, such as hitting set and set cover, we show that solving the paired problem approximately is no easier than solving either problem independently.
Optimally fast incremental Manhattan plane embedding and planar
tight span construction.
D. Eppstein.
arXiv:0909.1866.
J. Computational Geometry 2 (1): 144–182, 2011, doi:10.20382/jocg.v2i1a8.
Shows that, when the tight span of a finite metric space is homeomorphic to a subset of the plane, it has the geometry of a Manhattan orbifold and can be constructed in time linear in the size of the input distance matrix. As a consequence, it can be tested in the same time whether a metric space is isometric to a subset of the L1 plane.
Hyperconvexity and metric embedding.
D. Eppstein.
Invited talk, Fifth
William Rowan Hamilton Geometry and Topology Workshop,
Dublin, Ireland, 2009.
Invited talk at IPAM Workshop on Combinatorial Geometry, UCLA, 2009.
Surveys hyperconvex metric spaces, tight spans, and my work on Manhattan orbifolds, tight span construction, and optimal embedding into star metrics.
Growth and decay in life-like cellular automata.
D. Eppstein.
arXiv:0911.2890.
Game of Life Cellular Automata (Andrew Adamatzky, ed.),
Springer, 2010, pp. 71–98, doi:10.1007/978-1-84996-217-9_6.
We classify semi-totalistic cellular automaton rules according to whether patterns can escape any finite bounding box and whether patterns can die out completely, with the aim of finding rules with interesting behavior similar to Conway's Game of Life. We survey a number of such rules.
Steinitz theorems for orthogonal polyhedra.
D. Eppstein and
E. Mumford.
arXiv:0912.0537.
26th Eur. Worksh. Comp. Geom., Dortmund, Germany, 2010.
26th ACM Symp. Comp. Geom., Snowbird, Utah, 2010, pp. 429–438, doi:10.1145/1810959.1811030.
J. Computational Geometry 5 (1): 179–244, 2014, doi:10.20382/jocg.v5i1a10.
We provide a graph-theoretic characterization of three classes of nonconvex polyhedra with axis-parallel sides, analogous to Steinitz's theorem characterizing the graphs of convex polyhedra.
The journal version has the slightly different title "Steinitz theorems for simple orthogonal polyhedra".

Ramified rectilinear polygons: coordinatization by dendrons.
H.-J. Bandelt,
V. Chepoi,
and D. Eppstein.
arXiv:1005.1721.
Disc. Comp. Geom.
54 (4): 771–797, 2015, doi:10.1007/s00454-015-9743-5.
We characterize the graphs that can be isometrically embedded into the Cartesian product of two trees (partial double dendrons), and the metric spaces obtained as the median complexes of these graphs. These spaces include the space of geodesic distance in axis-parallel polygons in the L1 plane, hence the title. An algorithm based on lexicographic breadth-first search can be used to recognize partial double dendrons in linear time.
Cloning Voronoi diagrams via retroactive data structures.
M. Dickerson,
D. Eppstein, and
M. T. Goodrich.
arXiv:1006.1921.
18th Eur. Symp. Algorithms, Liverpool, 2010.
Springer, Lecture
Notes in
Comp. Sci. 6346, 2010, pp. 362–373, doi:10.1007/978-3-642-15775-2_31.
We analyze the security of an online geometric database that allows planar nearest-neighbor queries but that does not wish the entire database to be copied by a competitor. We show that, under several models of how the query answers are returned, the database can be copied in a linear or near-linear number of queries. Our method for the competitor to copy the database is based on simulating Fortune's sweep-line algorithm for Voronoi diagrams, backtracking when the simulation discovers the existence of another point that invalidates earlier parts of the Voronoi diagram construction, and using retroactive data structures to perform the backtracking steps efficiently.
Regular labelings and geometric structures.
D. Eppstein.
arXiv:1007.0221.
Invited to 22nd Canadian Conference on Computational Geometry (CCCG 2010).
Invited to Proc. 21st International Symposium on Algorithms and Computation
(ISAAC 2010), Jeju, Korea, 2010.
Springer, Lecture
Notes in
Comp. Sci. 6506, 2010, p. 1, doi:10.1007/978-3-642-17517-6_1.
We survey regular labelings for straight-line embedding of planar graphs on grids, rectangular partitions, and orthogonal polyhedra, and the many similarities between these different types of labeling.
Flows in one-crossing-minor-free graphs.
E. Chambers and
D. Eppstein.
arXiv:1007.1484.
Proc. 21st International Symposium on Algorithms and Computation
(ISAAC 2010), Jeju, Korea, 2010.
Springer, Lecture
Notes in
Comp. Sci. 6506, 2010, pp. 241–252, doi:10.1007/978-3-642-17517-6_23.
J. Graph Algorithms
and Applications 17 (3): 201–220, 2013, doi:10.7155/jgaa.00291.
We show that the maximum flow problem can be solved in near-linear time for K5-minor-free and K3,3-minor-free graphs. The same result also holds for H-minor-free graphs when H can be embedded in the plane with one crossing and a structural decomposition of the input flow graph is given.
Listing all maximal cliques in sparse graphs in near-optimal time.
D. Eppstein,
M. Löffler, and
D. Strash.
arXiv:1006.5440.
Workshop on Exact Algorithms for \(\mathsf{NP}\)-Hard Problems, Dagstuhl, Germany, 2010.
Proc. 21st International Symposium on Algorithms and Computation
(ISAAC 2010), Jeju, Korea, 2010.
Springer, Lecture Notes in
Comp. Sci. 6506, 2010, pp. 403–414, doi:10.1007/978-3-642-17517-6_36.
We describe an algorithm for finding all maximal cliques in a graph, in time O(dn3d/3) where n is the number of vertices and d is the degeneracy of the graph, a standard measure of its sparsity. This time bound matches the worst-case output size for these parameters. The algorithm modifies the Bron-Kerbosch algorithm for maximal cliques by ordering the vertices by degree in the outer recursive call of the algorithm.
For the journal version, see "Listing all maximal cliques in large sparse real-world graphs," which combines results from this and a different conference paper.
Drawing graphs in the plane with a prescribed outer face and
polynomial area.
E. Chambers,
D. Eppstein,
M. T. Goodrich, and
M. Löffler.
Proc. 18th Int. Symp. Graph Drawing, Konstanz, Germany, 2010.
Springer, Lecture Notes in
Comp. Sci. 6502, 2011, pp. 129–140, doi:10.1007/978-3-642-18469-7_12.
arXiv:1009.0088.
J. Graph
Algorithms and Applications 16 (2): 243–259, 2012, doi:10.7155/jgaa.00257.
Tutte's method of spring embeddings allows any triangulated planar graph to be drawn so that the outer face has any pre-specified convex shape, but it may place vertices exponentially close to each other. Alternative graph drawing methods provide polynomial-area straight line drawings but do not allow the outer face shape to be specified. We describe a drawing method that combines both properties: it has polynomial area, and can match any pre-specified shape of the outer face, even a shape in which some of the vertices have 180 degree angles. We apply our results to drawing polygonal schemas for graphs embedded on surfaces of positive genus.
Lombardi drawings of graphs.
C. Duncan,
D. Eppstein,
M. T. Goodrich,
S. Kobourov, and
M. Nöllenburg.
Proc. 18th Int. Symp. Graph Drawing, Konstanz, Germany, 2010.
Springer, Lecture Notes in
Comp. Sci. 6502, 2011, pp. 195–207, doi:10.1007/978-3-642-18469-7_18.
arXiv:1009.0579.
Invited talk at 7th Dutch Computational Geometry Day, Eindhoven, the
Netherlands, 2010.
J. Graph
Algorithms and Applications 16 (1): 85–108, 2012, doi:10.7155/jgaa.00251 (special issue
for GD 2010).
In honor of artist Mark Lombardi, we define a Lombardi drawing to be a drawing of a graph in which the edges are drawn as circular arcs and at each vertex they are equally spaced around the vertex so as to achieve the best possible angular resolution. We describe algorithms for constructing Lombardi drawings of regular graphs, 2-degenerate graphs, graphs with rotational symmetry, and several types of planar graphs. A program for the rotationally symmetric case, the Lombardi Spirograph, is available online.
Drawing trees with perfect angular resolution and polynomial area.
C. Duncan,
D. Eppstein,
M. T. Goodrich,
S. Kobourov, and
M. Nöllenburg.
Proc. 18th Int. Symp. Graph Drawing, Konstanz, Germany, 2010.
Springer, Lecture Notes in
Comp. Sci. 6502, 2011, pp. 183–194, doi:10.1007/978-3-642-18469-7_17.
arXiv:1009.0581.
Discrete Comput. Geom. 49 (2): 157–182, 2013, doi:10.1007/s00454-012-9472-y.
We consider balloon drawings of trees, in which each subtree of the root is drawn recursively within a disk, and these disks are arranged radially around the root, with the edges at each node spaced equally around the node so as to achieve the best possible angular resolution. If we are allowed to permute the children of each node, then we show that a drawing of this type can be made in which all edges are straight line segments and the area of the drawing is a polynomial multiple of the shortest edge length. However, if the child ordering is prescribed, exponential area might be necessary. We show that, if we relax the requirement of straight line edges and draw the edges as circular arcs (a style we call Lombardi drawing) then even with a prescribed child ordering we can achieve polynomial area.
Optimal 3D angular resolution for low-degree graphs.
D. Eppstein,
M. Löffler,
E. Mumford, and
M. Nöllenburg.
Proc. 18th Int. Symp. Graph Drawing, Konstanz, Germany, 2010.
Springer, Lecture Notes in
Comp. Sci. 6502, 2011, pp. 208–219, doi:10.1007/978-3-642-18469-7_19.
arXiv:1009.0045.
J. Graph Algorithms
and Applications 17 (3): 173–200, 2013, doi:10.7155/jgaa.00290.
We show how to draw any graph of maximum degree three in three dimensions with 120 degree angles at each vertex or bend, and any graph of maximum degree four in three dimensions with the angles of the diamond lattice at each vertex or bend. In each case there are no crossings and the number of bends per edge is a small constant.
Extended dynamic subgraph statistics using h-index parameterized
data structures.
D. Eppstein,
M. T. Goodrich,
D. Strash, and
L. Trott.
Proc. 4th Int. Conf. on Combinatorial Optimization and Applications
(COCOA 2010), Hawaii, 2010.
Springer, Lecture Notes in
Comp. Sci. 6508, 2010, pp. 128–141, doi:10.1007/978-3-642-17458-2_12.
arXiv:1009.0783.
Theor. Comput. Sci.
447: 44–52, 2012, doi:10.1016/j.tcs.2011.11.034 (special issue for COCOA 2010).
An earlier paper with Spiro at WADS 2009 provided dynamic graph algorithms for counting how many copies of each possible type of subgraph there are in a larger undirected graph, when the subgraphs have at most three vertices. This paper extends the method to directed graphs and to larger numbers of vertices per subgraph.
Privacy-preserving data-oblivious geometric algorithms for
geographic data.
D. Eppstein,
M. T. Goodrich, and
R. Tamassia.
Proc. 18th ACM SIGSPATIAL Int. Conf. Advances in Geographic
Information Systems (ACM GIS 2010), San Jose, California, pp. 13–22, doi:10.1145/1869790.1869796.
arXiv:1009.1904.
An algorithm is data-oblivious if the memory access patterns it makes depend only on the input size and not on the actual input values; data-oblivious algorithms are an important building block of cryptographic protocols that allow algorithmic tasks to be solved by parties who each have some subset of the input data that they do not wish to reveal. We show how to solve several basic geometric problems data-obliviously, including construction of convex hulls, quadtrees, and well-separated pair decompositions, and computation of closest pairs and all nearest neighbors.
Densities of minor-closed graph families.
D. Eppstein.
arXiv:1009.5633.
Electronic J. Combinatorics 17(1), Paper R136, 2010, doi:10.37236/408.
For every minor-closed graph family (such as the family of planar graphs), there is a constant c such that the maximum number of edges in an n-vertex graph in the family is c(n + o(n); for instance, for planar graphs, c = 3. We call c the limiting density of the family, and we study the set of all limiting densities of all minor-closed graph families. We show that this set of limiting densities is closed and well-ordered, with order type at least ωω, and we find an exact description of the members of this set up to its first two cluster points 1 and 3/2.
Questions answered. In theory.
D. Clarke,
D. Eppstein,
K. Ghasemloo,
L. Reyzin,
A. Salamon,
P. Shor,
A. Sterling,
and
S. Venkatasubramanian.
ACM SIGACT News 41 (4): 58–60, 2010, doi:10.1145/1907450.1907532.
An overview of the Theoretical Computer Science question and answer exchange web site.
Bounds on the complexity of halfspace intersections when the
bounded faces have small dimension.
D. Eppstein and
M. Löffler.
Proc. 27th ACM Symp. on Computational Geometry, Paris, 2011, pp. 361–368,
doi:10.1145/1998196.1998257.
arXiv:1103.2575.
Discrete Comput. Geom. 50 (1): 1–21, 2013, doi:10.1007/s00454-013-9503-3.
Suppose that \(P\) is the intersection of \(n\) halfspaces in \(D\) dimensions, but that the bounded faces of \(P\) are at most \(d\)-dimensional, for some \(d\) that is much smaller than \(D\). Then in this case we show that the number of vertices of \(P\) is \(O(n^d)\), independent of \(D\). We also investigate related bounds on the number of bounded faces of all dimensions of \(P\), and algorithms for efficiently listing the vertices and bounded faces of \(P\).
On 2-site Voronoi diagrams under geometric distance functions.
G. Barequet,
M. Dickerson,
D. Eppstein,
D. Hodorkovsky, and
K. Vyatkina.
27th Eur. Worksh. Comp. Geom., Antoniushaus Morschach,
Switzerland, 2011, pp. 59–62.
Proc. 8th Int. Symp. Voronoi Diagrams in Science and
Engineering, Qing Dao, China, 2011, pp. 31–38, doi:10.1109/ISVD.2011.13.
arXiv:1105.4130.
J. Computer Science and Technology 28 (2): 267–277, 2013, doi:10.1007/s11390-013-1328-2.
We study the combinatorial complexity of generalized Voronoi diagrams that determine the closest two point sites to a query point, where the distance from the query point to a pair of sites is a combination of the individual distances to the sites and the distance from one site in the pair to the other.
Listing all maximal cliques in large sparse real-world graphs.
D. Eppstein and
D. Strash.
10th Int. Symp. Experimental Algorithms, Crete, 2011.
Springer, Lecture
Notes in Comp. Sci. 6630, 2011, pp. 364–375, doi:10.1007/978-3-642-20662-7_31.
arXiv:1103.0318.
We experiment with our degeneracy-based algorithm for listing maximal cliques in sparse graphs and show that it works well on large graphs drawn from several repositories of real-world social networks and bioinformatics networks.
For the journal version, see "Listing all maximal cliques in large sparse real-world graphs", which combines results from this and a different conference paper.
Guest editor's foreword.
D. Eppstein and
E. Gansner.
Journal of Graph Algorithms and Applications 15 (2): 3–5, 2011,
doi:10.7155/jgaa.00214
(Special Issue on Selected Papers from the Seventeenth International
Symposium on Graph Drawing, GD 2009)
Adjacency-preserving spatial treemaps.
K. Buchin,
D. Eppstein,
M. Löffler,
M. Nöllenburg, and
R. I. Silveira.
arXiv:1105.0398.
12th International Symposium on Algorithms and Data Structures (WADS 2011), New York,
2011.
Springer, Lecture Notes in Comp. Sci. 6844, 2011, pp. 159–170,
doi:10.1007/978-3-642-22300-6_14.
J. Computational Geometry 7 (1): 100–122, 2016, doi:10.20382/jocg.v7i1a6.
We study the recursive partitions of rectangles into sets of rectangles, and partitions of those rectangles into smaller rectangles, to form stylized visualizations of hierarchically subdivided geographic regions. There are several variations of varying difficulty depending on how much of the geographic information from the input we require the output to preserve.
Tracking moving objects with few handovers.
D. Eppstein,
M. T. Goodrich, and
M. Löffler.
arXiv:1105.0392.
12th International Symposium on Algorithms and Data Structures (WADS 2011), New York,
2011.
Springer, Lecture Notes in Comp. Sci. 6844, 2011, pp. 362–373,
doi:10.1007/978-3-642-22300-6_31.
We apply competitive analysis to the problem of deciding online which cell phone tower to change to when a phone moves out of the coverage region of the tower it is connected to. We show that, when the coverage regions have constant ply (at most a constant number of them overlap any point of the plane) it is possible to get within a constant factor of the minimum possible number of handovers that an offline algorithm could achieve.
What's the difference? Efficient set reconciliation without prior
context.
D. Eppstein,
M. T. Goodrich,
F. Uyeda, and
G. Varghese.
Proc. ACM SIGCOMM, Toronto, Canada, 2011,
doi:10.1145/2018436.2018462,
doi:10.1145/2043164.2018462.
We determine the symmetric difference between two similar sets of items, held by different machines on the internet, using an amount of communication bandwidth that is proportional only to the difference between the sets and with low computational overhead. Our solution technique combines the invertible Bloom filter data structure from our previous work on streaming straggler detection with a randomized sampling scheme that allows us to accurately and efficiently estimate the size of the difference.
Category-based routing in social networks: membership dimension and the small-world phenomenon.
D. Eppstein,
M. T. Goodrich,
M. Löffler,
D. Strash, and
L. Trott.
Workshop on Graph Algorithms and Applications, Zürich,
Switzerland, July 2011.
International Conference on Computational
Aspects of Social Networks (CASoN 2011), Salamanca, Spain, October
2011,
doi:10.1109/CASON.2011.6085926.
arXiv:1108.4675.
Theor. Comput. Sci. 514: 96–104, 2013, doi:10.1016/j.tcs.2013.04.027. (Special issue on Graph
Algorithms and Applications: in Honor of Professor Giorgio Ausiello)
We investigate greedy routing schemes for social networks, in which participants know categorical information about some other participants and use it to guide message delivery by forwarding messages to neighbors that have more categories in common with the eventual destination. We define the membership dimension of such a scheme to be the maximum number of categories that any individual belongs to, a natural measure of the cognitive load of greedy routing on its participants. And we show that membership dimension is closely related to the small world phenomenon: a social network can be given a category system with polylogarithmic membership dimension that supports greedy routing if, and only if, the network has polylogarithmic diameter.
Confluent Hasse diagrams.
D. Eppstein and
J. Simons.
Proc. 19th Int. Symp. Graph Drawing, Eindhoven, The Netherlands, 2011.
Springer, Lecture Notes in Comp. Sci. 7034, 2012, pp. 2–13,
doi:10.1007/978-3-642-25878-7_2.
arXiv:1108.5361.
J. Graph
Algorithms and Applications 17 (7): 689–710, 2013, doi:10.7155/jgaa.00312.
We show that a partial order has a non-crossing upward planar drawing if and only if it has order dimension two, and we use the Dedekind-MacNeille completion to find a drawing with the minimum possible number of confluent junctions.
Hardness of approximate compaction for nonplanar orthogonal graph
drawings.
M. J. Bannister and
D. Eppstein.
Proc. 19th Int. Symp. Graph Drawing, Eindhoven, The Netherlands, 2011.
Springer, Lecture Notes in Comp. Sci. 7034, 2012, pp. 367–378,
doi:10.1007/978-3-642-25878-7_35.
We show that, for several variants of the problem of compacting a grid drawing of a graph to use the minimum number of rows or minimum area, no good approximation algorithm is possible. We also develop fixed-parameter tractable algorithms and approximation algorithms showing that some of our inapproximability bounds are tight. See the journal version, "Inapproximability of orthogonal compaction", for some improvements and corrections.
Planar and poly-arc Lombardi drawings.
C. Duncan,
D. Eppstein,
M. T. Goodrich,
S. Kobourov, and
M. Löffler, and
M. Nöllenburg.
Proc. 19th Int. Symp. Graph Drawing, Eindhoven, The Netherlands, 2011.
Springer, Lecture Notes in
Comp. Sci. 7034, 2012, pp. 308–319,
doi:10.1007/978-3-642-25878-7_30.
arXiv:1109.0345.
J. Computational Geometry
9 (1): 328–355, 2018, doi:10.20382/jocg.v9i1a11.
We extend Lombardi drawing (in which each edge is a circular arc and the edges incident to a vertex must be equally spaced around it) to drawings in which edges are composed of multiple arcs, and we investigate the graphs that can be drawn in this more relaxed framework.
Randomized speedup of the Bellman–Ford algorithm.
M. J. Bannister and
D. Eppstein.
arXiv:1111.5414.
Analytic Algorithmics and Combinatorics (ANALCO12), Kyoto, Japan, 2012, pp. 41–47,
doi:10.1137/1.9781611973020.6.
The Bellman–Ford algorithm for single-source shortest paths in graphs that may have negatively weighted edges but no negative cycles can be sped up by a technique of Yen in which the graph is partitioned into two directed acyclic subgraphs and edge relaxations alternate between these two subgraphs. We show that choosing this partition randomly gains an additional factor of 2/3 in running time.
Improved grid map layout by point set matching.
D. Eppstein,
M. van Kreveld,
B. Speckmann, and
F. Staals.
28th European Workshop on Computational Geometry (EuroCG'12), Assisi,
Italy, 2012.
6th IEEE Pacific Visualization Conf. (PacificVis), Sydney, Australia, 2013,
doi:10.1109/PacificVis.2013.6596124.
Int. J. Comput. Geom. Appl. 25 (2): 101–122, 2015, doi:10.1142/S0218195915500077.
We study the problem of matching geographic regions to points in a regular grid, minimizing the distance between each region's centroid and the corresponding grid point, and preserving as much as possible the relative orientations between pairs of regions.
Inapproximability of orthogonal compaction.
M. J. Bannister,
D. Eppstein, and
J. Simons.
arXiv:1108.4705.
J. Graph Algorithms and Applications 16 (3): 651–673, 2012, doi:10.7155/jgaa.00263. (Special issue for GD 2011.)
This is the journal version of "Hardness of approximate compaction for nonplanar orthogonal graph drawings". It has stronger inapproximability bounds, and more variations of the compaction problem that are hard to approximate. In addition it includes a retraction of a buggy approximation algorithm from the conference version.
Privacy-enhanced methods for comparing compressed DNA sequences.
D. Eppstein,
M. T. Goodrich, and
P. Baldi.
arXiv:1107.3593.
Area-universal and constrained rectangular layouts.
D. Eppstein,
E. Mumford,
B. Speckmann, and
K. Verbeek.
SIAM J. Computing 41 (3): 537–564, 2012, doi:10.1137/110834032.
A combined journal version of "Area-universal rectangular layouts" and "Orientation-constrained rectangular layouts".
Solving single-digit Sudoku subproblems.
D. Eppstein.
arXiv:1202.5074.
6th International Conference on Fun with Algorithms (FUN 2012),
Venice, Italy, 2012.
Springer, Lecture Notes in
Comp. Sci. 7288, 2012, pp. 142–153, doi:10.1007/978-3-642-30347-0_16.
We find an algorithm for making all possible deductions based on the set of candidate locations for a single digit in a Sudoku puzzle; the problem is \(\mathsf{NP}\)-hard, and our algorithm takes exponential time, but the mild form of the exponential allows it to be fast for practical problem sizes.
Near-linear-time deterministic plane Steiner spanners and TSP
approximation for well-spaced point sets.
G. Borradaile and
D. Eppstein.
arXiv:1206.2254.
24th Canadian Conference on Computational Geometry (CCCG 2012),
Prince Edward Island, Canada, 2012, pp. 311–316.
Comp. Geom. Theory
& Applications 49: 8–16, 2015, doi:10.1016/j.comgeo.2015.04.005 (special issue for CCCG 2012).
When a planar point set has the property that its Delaunay triangulation has no large angles, we show how to connect it by a plane graph (having linearly many additional Steiner vertices) in which the distances between the original points are approximations to their Euclidean distance, and in which the total graph weight is at most a constant times the minimum spanning tree weight. The time to construct this graph is near-linear, the same as for integer sorting. We use this result to approximate the traveling salesman problem, for these point sets, in the same time bound.
UOBPRM: a uniform distributed obstacle-based PRM.
H.-Y. Yeh,
S. Thomas,
D. Eppstein, and
N. Amato.
IEEE/RSJ International
Conference on Intelligent Robots and Systems (IROS 2012),
Vilamoura, Algarve, Portugal, 2012, pp. 2655–2662, doi:10.1109/IROS.2012.6385875.
We use a method based on intersecting obstacles with line segments in order to uniformly sample from obstacle surfaces in the probabilistic roadmap method for robot motion planning.
Diamond-kite meshes: adaptive quadrilateral meshing and orthogonal circle packing.
D. Eppstein.
arXiv:1207.5082.
21st International Meshing Round Table, San Jose, California,
2012, pp. 261–277, doi:10.1007/978-3-642-33573-0_16.
Engineering
with Computers 30 (2): 223–235 (special issue for the 21st
Int. Meshing Roundtable), 2014, doi:10.1007/s00366-013-0327-9.
We describe a recursive subdivision of the plane into quadrilaterals in the form of rhombi and kites with 60, 90, and 120 degree angles. The vertices of the resulting quadrilateral mesh form the centers of a set of circles that cross orthogonally for every two adjacent vertices, and it has many other properties that are important in finite element meshing.
A Möbius-invariant power diagram and its applications to soap
bubbles and planar Lombardi drawing.
D. Eppstein.
Invited talk at EuroGIGA Midterm
Conference, Prague, Czech Republic, 2012.
Discrete
Comput. Geom. 52 (3): 515–550, 2014 (Special issue for SoCG 2013), doi:10.1007/s00454-014-9627-0.
This talk and journal paper combines the results from "Planar Lombardi drawings for subcubic graphs" and "The graphs of planar soap bubbles". It uses three-dimensional hyperbolic geometry to define a partition of the plane into cells with circular-arc boundaries, given an input consisting of (possibly overlapping) circular disks and disk complements, which remains invariant under Möbius transformations of the input. We use this construction as a tool to construct planar Lombardi drawings of all 3-regular planar graphs; these are graph drawings in which the edges are represented by circular arcs meeting at equal angles at each vertex. We also use it to characterize the graphs of two-dimensional soap bubble clusters as being exactly the 2-vertex-connected 3-regular planar graphs.
Planar Lombardi drawings for subcubic graphs.
D. Eppstein.
arXiv:1206.6142.
20th Int. Symp. Graph Drawing, Redmond, Washington, 2012.
Springer, Lecture Notes in Comp. Sci. 7704, 2013, pp. 126–137, doi:10.1007/978-3-642-36763-2_12.
We show that every planar graph of maximum degree three has a planar Lombardi drawing and that some but not all 4-regular planar graphs have planar Lombardi drawings. The proof idea combines circle packings with a form of Möbius-invariant power diagram for circles, defined using three-dimensional hyperbolic geometry.
For the journal version, see "A Möbius-invariant power diagram and its applications to soap bubbles and planar lombardi drawing.".
Force-directed graph drawing using social gravity and scaling.
M. J. Bannister,
D. Eppstein,
M. T. Goodrich, and
L. Trott.
arXiv:1209.0748.
20th Int. Symp. Graph Drawing, Redmond, Washington, 2012.
Springer, Lecture Notes in Comp. Sci. 7704, 2013, pp. 414–425, doi:10.1007/978-3-642-36763-2_37.
We extend force-directed methods of graph drawing by adding a force that pulls vertices towards the center of the drawing, with a strength proportional to the centrality of the vertex. Gradually scaling up this force helps avoid the tangling that would otherwise result from its use.
On the density of maximal 1-planar graphs.
F. J. Brandenburg,
D. Eppstein,
A. Gleißner,
M. T. Goodrich,
K. Hanauer, and
J. Reislhuber.
20th Int. Symp. Graph Drawing, Redmond, Washington, 2012.
Springer, Lecture Notes in Comp. Sci. 7704, 2013, pp. 327–338, doi:10.1007/978-3-642-36763-2_29.
A graph is 1-planar if it can be drawn in the plane with at most one crossing per edge, and maximal 1-planar if it is 1-planar but adding any edge would force more than one crossing on some edge or edges. Although maximal 1-planar graphs on n vertices may have as many as 4n − 8 edges, we show that there exist maximal 1-planar graphs with as few as 45n/17 + O(1) edges.
Windows into relational events: data structures for contiguous
subsequences of edges.
M. J. Bannister,
C. DuBois,
D. Eppstein, and
P. Smyth.
NIPS 2012 Workshop on Algorithmic and Statistical Approaches for Large
Social Networks, South Lake Tahoe, California, 2012 (poster and invited talk).
24th ACM-SIAM
Symp. Discrete Algorithms, New Orleans, Louisiana, 2013,
pp. 856–864,
doi:10.1137/1.9781611973105.61.
arXiv:1209.5791.
We study relational event data in which a collection of actors in a social network have a sequence of pairwise interactions. Contiguous subsequences of these interactions form graphs, and we develop efficient data structures for querying the parameters of these graphs.
The graphs of planar soap bubbles.
D. Eppstein.
arXiv:1207.3761.
Proc. 29th ACM Symp. on Computational Geometry, Rio de Janeiro,
2013, pp. 27–36, doi:10.1145/2462356.2462370.
We characterize the graphs of two-dimensional soap bubble clusters as being exactly the bridgeless 3-regular planar graphs. The proof uses the Möbius invariance of the properties characterizing these clusters together with our previous circle packing method for constructing Lombardi drawings of graphs.
For the journal version, see "A Möbius-invariant power diagram and its applications to soap bubbles and planar lombardi drawing.".
Antimatroids and balanced pairs.
D. Eppstein.
arXiv:1302.5967.
Order 31 (1): 81–99, 2014, doi:10.1007/s11083-013-9289-1.
Erratum (with V. Wiechert), doi:10.1007/s11083-014-9335-7.
We generalize the 1/3-2/3 conjecture, according to which every partial order should have a pair of items that are nearly equally likely to appear in either order in a random linear extension, to antimatroids, and we prove it for several specific types of antimatroid.
Grid minors in damaged grids.
D. Eppstein.
arXiv:1303.1136.
Electronic J. Combinatorics 21(3), Paper P3.20, 2014, doi:10.37236/3872.
We give tight bounds on the size of the largest remaining grid minor in a grid graph from which a given number of vertices have been deleted, and study several related problems.
Combinatorial pair testing: distinguishing workers from slackers.
D. Eppstein,
M. T. Goodrich,
and D. S. Hirschberg.
arXiv:1305.0110.
13th Int. Symp. Algorithms and Data Structures (WADS 2013), London, Ontario.
Springer, Lecture Notes in Comp. Sci. 8037, 2013, pp. 316–327, doi:10.1007/978-3-642-40104-6_28.
We study the problem of distinguishing workers (people who complete their assigned tasks) from slackers (people who do not contribute towards the completion of their tasks) by grouping people in pairs and assigning a task to each group.
Parameterized complexity of 1-planarity.
M. J. Bannister,
S. Cabello,
and D. Eppstein.
arXiv:1304.5591.
13th Int. Symp. Algorithms and Data Structures (WADS 2013), London, Ontario
Springer, Lecture Notes in Comp. Sci. 8037, 2013, pp. 97–108, doi:10.1007/978-3-642-40104-6_9.
J. Graph Algorithms and
Applications 22 (1): 23–49, 2018, doi:10.7155/jgaa.00457. (Special issue on Graph
Drawing Beyond Planarity.)
We show that testing whether a graph is 1-planar (drawable with at most one crossing per edge) may be performed in polynomial and fixed-parameter tractable time for graphs of bounded circuit rank, vertex cover number, or tree-depth. However, it is \(\mathsf{NP}\)-complete for graphs of bounded treewidth, pathwidth, or bandwidth.
Knowledge Spaces: Applications in Education.
J.-C.
Falmagne,
D. Albert,
C. Doble,
D. Eppstein,
and X. Hu, eds.
Springer, 2013, doi:10.1007/978-3-642-35329-1.
This edited volume collects experiences with automated learning systems based on the theory of knowledge spaces, and mathematical explorations of the theory of knowledge spaces and their efficient implementation.
Learning sequences: an efficient data structure for learning spaces.
D. Eppstein.
In Knowledge Spaces: Applications in Education,
J.-C. Falmagne, D. Albert, C. Doble, D. Eppstein, and X. Hu, eds.
Springer, 2013, pp. 287–304, doi:10.1007/978-3-642-35329-1_13.
We show how to represent a learning space by a small family of learning sequences, orderings of the items in a learning sequence that are consistent with their prerequisite relations. This representation allows for the rapid generation of the family of all consistent knowledge states and the efficient assessment of the state of knowledge of a human learner.
Projection, decomposition, and adaption of learning spaces.
D. Eppstein.
In Knowledge Spaces: Applications in Education,
J.-C. Falmagne, D. Albert, C. Doble, D. Eppstein, and X. Hu, eds.
Springer, 2013, pp. 305–322, doi:10.1007/978-3-642-35329-1_14.
In another chapter of the same book we used learning sequences to represent learning spaces and perform efficient knowledge assessment of a human learning. In this chapter we show how to use the same data structure to build learning spaces on a sample of the items of a larger learning space (an important subroutine in knowledge assessment) and to modify a learning space to more accurately model students.
A brief history of curves in graph drawing.
D. Eppstein.
Invited survey talk at Workshop on Drawing Graphs and Maps with Curves,
Dagstuhl, Germany, April 2013.
Drawing Graphs and
Maps with Curves (Dagstuhl Seminar 13151), doi:10.4230/DagRep.3.4.34,
S. G. Kobourov, M. Nöllenburg, and M. Teillaud, eds.,
Dagstuhl Reports 3(4): 40–46, 2013.
Set-difference range queries.
D. Eppstein,
M. T. Goodrich, and
J. Simons.
arXiv:1306.3482.
25th Canadian Conference on Computational Geometry, Waterloo,
Canada, 2013.
We show how to use invertible Bloom filters as part of range searching data structures that determine the differences between the members of two sets that lie in a given query range.
Universal point sets for planar graph drawings with circular arcs.
P. Angelini,
D. Eppstein,
F. Frati,
M. Kaufmann,
S. Lazard,
T. Mchedlidze,
M. Teillaud, and
A. Wolff.
HAL-Inria open archive oai:hal.inria.fr:hal-00846953.
25th Canadian Conference on Computational Geometry, Waterloo,
Canada, 2013.
J. Graph Algorithms
and Applications 18 (3): 313–324, 2014, doi:10.7155/jgaa.00324.
For every positive integer n, there exists a set of n points on a parabola, with the property that every n-vertex planar graph can be drawn without crossings with its vertices at these points and with its edges drawn as circular arcs.
Fixed parameter tractability of crossing minimization of almost-trees.
M. J. Bannister,
D. Eppstein, and
J. Simons.
arXiv:1308.5741.
21st Int. Symp. Graph Drawing, Bordeaux, France, 2013.
Springer, Lecture Notes in Comp. Sci. 8242, 2013, pp. 340–351, doi:10.1007/978-3-319-03841-4_30.
Many real-world graphs are k-almost-trees for small values of k: graphs in which, in every biconnected component, removing a spanning tree leaves at most k edges. We use kernelization methods to show that in such graphs, the 1-page and 2-page crossing numbers can be computed quickly.
Superpatterns and universal point sets.
M. J. Bannister,
Z. Cheng,
W. E. Devanny, and
D. Eppstein.
arXiv:1308.0403.
21st Int. Symp. Graph Drawing, Bordeaux, France, 2013.
Springer, Lecture Notes in Comp. Sci. 8242, 2013, pp. 208–219, doi:10.1007/978-3-319-03841-4_19.
Bannister's talk on this paper won the GD2013 best presentation award.
J. Graph Algorithms & Applications 18 (2): 177–209, 2014, doi:10.7155/jgaa.00318 (special issue for GD'13).
A superpattern of a set of permutations is a permutation that contains as a pattern every permutation in the set. Previously superpatterns had been considered for all permutations of a given length; we generalize this to sets of permutations defined by forbidden patterns; we show that the 213-avoiding permutations have superpatterns half the length of the known bound for all permutations, and that any proper permutation subclass of the 213-avoiding permutations has near-linear superpatterns. We apply these results to the construction of universal point sets, sets of points that can be used as the vertices of drawings of all n-vertex planar graphs. We use our 213-avoiding superpatterns to construct universal sets of size approximately \(n^2/4\), and we also construct near-linear universal sets for graphs of bounded pathwidth.
Drawing arrangement graphs in small grids, or how to play
planarity.
D. Eppstein.
arXiv:1308.0066.
21st Int. Symp. Graph Drawing, Bordeaux, France, 2013.
Springer, Lecture Notes in Comp. Sci. 8242, 2013, pp. 436–447, doi:10.1007/978-3-319-03841-4_38.
J. Graph Algorithms &
Applications 18 (2): 211–231, 2014, doi:10.7155/jgaa.00319 (special issue for GD'13).
The planarity game involves rearranging a scrambled line arrangement graph to make it planar. We show that the resulting graphs have drawings in grids of area n7/6, much smaller than the quadratic size bound for grid drawings of planar graphs, and we provide a strategy for planarizing these graphs that is simple enough for human puzzle solving.
Strict confluent drawing.
D. Eppstein,
D. Holten,
M. Löffler,
M. Nöllenburg, and
B. Speckmann, and
K. Verbeek.
arXiv:1308.6824.
21st Int. Symp. Graph Drawing, Bordeaux, France, 2013.
Springer, Lecture Notes in Comp. Sci. 8242, 2013, pp. 352–363, doi:10.1007/978-3-319-03841-4_31.
J. Computational Geometry 7 (1): 22–46, 2016, doi:10.20382/jocg.v7i1a2.
A confluent drawing of a graph is a set of points and curves in the plane with the property that two vertices are adjacent in the graph if and only if the corresponding points can be connected to each other by smooth paths in the drawing. We define a variant of confluent drawing, strict confluent drawing, in which a smooth path between two vertices (if it exists) must be unique. We show that it is \(\mathsf{NP}\)-complete to test whether such drawings exist, in contrast to unrestricted confluence for which the complexity remains open. Additionally, we show that finding outerplanar drawings (in which the points are on the boundary of a disk and the curves are interior to it) with a fixed cyclic vertex ordering can be performed in polynomial time. We use circle packings to find nice versions of these drawings in which all tracks are represented by piecewise-circular curves.
Convex-arc drawings of pseudolines.
D. Eppstein,
M. van Garderen,
B. Speckmann, and
T. Ueckerdt.
21st Int. Symp. Graph Drawing (poster), Bordeaux, France, 2013.
Springer, Lecture Notes in Comp. Sci. 8242, 2013, pp. 522–523.
arXiv:1601.06865.
We show that every outerplanar weak pseudoline arrangement (a collection of curves topologically equivalent to lines, each crossing at most once but possibly zero times, with all crossings belonging to an infinite face) can be straightened to a hyperbolic line arrangement. As a consequence such an arrangement can also be drawn in the Euclidean plane with each pseudoline represented as a convex piecewise-linear curve with at most two bends. In contrast, for arbitrary pseudoline arrangements, a linear number of bends is sufficient and sometimes necessary.
Small superpatterns for dominance drawing.
M. J. Bannister,
W. E. Devanny, and
D. Eppstein.
arXiv:1310.3770.
Analytic Algorithmics and Combinatorics (ANALCO14), Portland,
Oregon, 2014, pp. 92–103,
doi:10.1137/1.9781611973204.9.
We construct small universal point sets for dominance drawings of classes of acyclic graphs, by finding forbidden patterns in the permutations determined by these drawings and proving the existence of small superpatterns for the permutations with these patterns forbidden. In particular, dominance drawings of the Hasse diagrams of width-2 partial orders have universal point sets of size O(n3/2), derived from superpatterns of the same size for the 321-avoiding permutations, and dominance drawings of st-planar graphs have universal point sets of size O(n log n), derived from superpatterns for riffle shuffles.
Structures in solution spaces: Three lessons from Jean-Claude.
D. Eppstein.
Invited talk, Conference on Meaningfulness and Learning Spaces:
A Tribute to the Work of Jean-Claude Falmagne
Irvine, California, 2014.
This talk surveys my work on rectangular cartograms, the 1/3-2/3 conjecture for antimatroids, and flip distance for triangulations of point sets with no empty pentagon, and how this line of research stemmed from the work of Jean-Claude Falmagne on learning spaces.
Distance-sensitive point location made easy.
B. Aronov,
M. De Berg,
D. Eppstein,
M. Roeloffzen, and
B. Speckmann.
30th European Workshop on Computational Geometry (EuroCG 2014), Dead
Sea, Israel, March 2014.
arXiv:1602.00767
Comp. Geom. Theory
& Applications 54: 17–31, 2016, doi:10.1016/j.comgeo.2016.02.001.
We use quadtrees to handle point location queries in an amount of time that depends on the distance of the query point to the nearest region boundary.
Listing all maximal cliques in large sparse real-world graphs.
D. Eppstein,
M. Löffler, and
D. Strash.
J. Experimental
Algorithmics 18 (3): 3.1, 2013, doi:10.1145/2543629 (special issue for SEA).
This paper combines our theoretical results on clique-finding algorithms from ISAAC 2010 with our experimental results on the same algorithms from SEA 2011. We show how to list all maximal cliques in graphs of bounded degeneracy in time that is linear in the size of the graph and near-optimal in the degeneracy, and we show that low degeneracy explains the good behavior of the algorithm in our experiments on large real-world social networks.
Wear minimization for cuckoo hashing: how not to throw a lot of
eggs into one basket.
D. Eppstein,
M. T. Goodrich,
M .Mitzenmacher, and
P. Pszona.
arXiv:1404.0286.
Proc. 13th International Symposium on Experimental Algorithms (SEA
2014), Copenhagen, Denmark, 2014.
Springer, Lecture Notes in Comp. Sci. 8504, pp. 162–173, 2014, doi:10.1007/978-3-319-07959-2_14.
We study cuckoo hashing data structures in a model of flash memory in which each memory cell has a limited number of times it can be changed, so the goal is to prevent hot spots that change many times.
Automated generation of linkage loop equations for planar 1-dof
linkages, demonstrated up to 8-bar.
B. E. Parrish,
>J. M. McCarthy, and
D. Eppstein.
Proc. ASME 2014
International Design Engineering Technical Conferences and Computers
and Information in Engineering Conference, Vol. 5A: 38th Mechanisms and
Robotics Conference, Buffalo, New York, USA, August 17-20, 2014, paper
no. DETC2014-35263, doi:10.1115/DETC2014-35263.
J. Mechanisms
and Robotics 7 (1): 011006, 2015, doi:10.1115/1.4029306.
This paper reports on an implementation of an algorithm for constructing the configuration space of two-dimensional linkages with one degree of freedom.
(eScholarship conference version – eScholarship journal version)
Planar induced subgraphs of sparse graphs.
G. Borradaile,
D. Eppstein,
and P. Zhu.
arXiv:1408.5939.
22nd Int. Symp. Graph Drawing, Würzburg, Germany, 2014.
Springer, Lecture Notes
in Comp. Sci. 8871, 2014, pp. 1–12., doi:10.1007/978-3-662-45803-7_1
J. Graph Algorithms &
Applications 19 (1): 281–297, 2015, doi:10.7155/jgaa.00358.
We investigate the number of vertices that must be deleted from an arbitrary graph, in the worst case as a function of the number of edges, in order to planarize the remaining graph. We show that m/5.22 vertices are sufficient and m/(6 − o(1)) are necessary, and we also give bounds for the number of deletions needed to achieve certain subclasses of planar graphs.
The Galois complexity of graph drawing: why numerical solutions are
ubiquitous for force-directed, spectral, and circle packing drawings.
M. J. Bannister,
W. E. Devanny,
D. Eppstein, and
M. T. Goodrich.
arXiv:1408.1422.
22nd Int. Symp. Graph Drawing, Würzburg, Germany, 2014
Springer, Lecture
Notes in Comp. Sci. 8871, 2014, pp. 149–161., doi:10.1007/10.1007/978-3-662-45803-7_13
J. Graph Algorithms &
Applications 19 (2): 619–656, 2015, doi:10.7155/jgaa.00349 (special issue for GD'14).
We show that many standard graph drawing methods have algebraic solutions described by polynomials that can have unsolvable Galois groups, and that can have Galois groups whose order is divisible by large prime numbers. As a consequence certain models of exact algebraic computation are unable to construct these drawings.
Crossing minimization for 1-page and 2-page drawings of graphs
with bounded treewidth.
M. J. Bannister and
D. Eppstein.
arXiv:1408.6321.
22nd Int. Symp. Graph Drawing, Würzburg, Germany, 2014.
Springer, Lecture
Notes in Comp. Sci. 8871, 2014, pp. 210–221, doi:10.1007/10.1007/978-3-662-45803-7_18
J. Graph Algorithms &
Applications 22 (4): 577–606, 2018, doi:10.7155/jgaa.00479.
We show how to express in monadic second-order logic the problems of drawing a graph with a fixed number of crossings on a one or two page book layout. By applying Courcelle's theorem, we obtain fixed-parameter tractable algorithms for these problems, parameterized by treewidth.
Balanced circle packings for planar graphs.
M. J. Alam,
D. Eppstein,
M. T. Goodrich,
S. Kobourov, and
S. Pupyrev.
arXiv:1408.4902.
22nd Int. Symp. Graph Drawing, Würzburg, Germany, 2014.
Springer, Lecture
Notes in Comp. Sci. 8871, 2014, pp. 125–136, doi:10.1007/978-3-662-45803-7_11
The balanced circle packings of the title are systems of interior-disjoint circles, whose tangencies represent the given graph, and whose radii are all within a polynomial factor of each other. We show that these packings always exist for trees, cactus graphs, outerpaths, k-outerplanar graphs of bounded degree when k is at most logarithmic, and planar graphs of bounded treedepth. The treedepth result uses a new construction of inversive-distance circle packings.
Flat foldings of plane graphs with prescribed angles and edge lengths.
Z. Abel,
E. Demaine,
M. Demaine,
D. Eppstein,
A. Lubiw, and
R. Uehara.
arXiv:1408.6771.
22nd Int. Symp. Graph Drawing, Würzburg, Germany, 2014.
Springer, Lecture
Notes in Comp. Sci. 8871, 2014, pp. 272–283, doi:10.1007/978-3-662-45803-7_23
J. Computational
Geometry 9 (1): 74–93, 2018, doi:10.20382/jocg.v9i1a3.
Given a plane graph with fixed edge lengths, and an assignment of the angles 0, 180, and 360 to the angles between adjacent edges, we show how to test whether the angle assignment can be realized by an embedding of the graph as a flat folding on a line. As a consequence, we can determine whether two-dimensional cell complexes with one vertex can be flattened. The main idea behind the result is to show that each face of the graph can be folded independently of the other faces.
k-best enumeration.
D. Eppstein.
Encyclopedia of Algorithms, doi:10.1007/978-3-642-27848-8_733-1 (Ming-Yang Kao, ed.), Springer, added 2014.
arXiv:1412.5075.
Bull. EATCS 115, 2015.
A brief survey of algorithms for finding the k shortest paths and related k-best enumeration problems. The arXiv/EATCS version is significantly longer and with more references than the Springer version.
Linear-time algorithms for proportional apportionment.
Z. Cheng and D. Eppstein.
arXiv:1409.2603.
Proc. 25th Int. Symp. Algorithms and Computation (ISAAC 2014),
Jeonju, Korea, 2014.
Springer, Lecture
Notes in Comp. Sci. 8889, 2014, pp. 581–592, doi:10.1007/978-3-319-13075-0_46
We consider a broad class of highest averages methods for proportional allocation (the problems of allocating seats to parties after a parliamentary election, or of allocating congressmen to states based on total population). We show that these methods can be simulated by an algorithm whose running time is proportional only to the number of parties or states, independent of the number of seats allocated or the number of voters.
Minimum forcing sets for Miura folding patterns.
B. Ballinger,
M. Damian,
D. Eppstein,
R. Flatland,
J. Ginepro, and
T. Hull.
arXiv:1410.2231.
26th ACM-SIAM Symp. on Discrete Algorithms, San Diego, 2015, pp. 136–147, doi:10.1137/1.9781611973730.11.
A forcing set for an origami crease pattern is a subset of the folds with the property that, if these folds are folded the correct way (mountain vs valley) the rest of the pattern also has to be folded the correct way. We use a combinatorial equivalence with three-colored grids to construct minimum-cardinality forcing sets for the Miura-ori folding pattern and for other patterns with differing folds along the same line segments.
Folding a paper strip to minimize thickness.
E. Demaine,
D. Eppstein,
A. Hesterberg,
H. Ito,
A. Lubiw,
R. Uehara, and
Y. Uno.
arXiv:1411.6371.
9th International Workshop on Algorithms and Computation (WALCOM
2015), Dhaka, Bangladesh.
Springer, Lecture Notes in Comp. Sci. 8973 (2015), pp. 113–124, doi:10.1007/978-3-319-15612-5_11.
Journal of Discrete
Algorithms 36: 18–26, 2016, doi:10.1016/j.jda.2015.09.003 (special issue for WALCOM).
If a folding pattern for a flat origami is given, together with a mountain-valley assignment, there might still be multiple ways of folding it, depending on how some flaps of the pattern are arranged within pockets formed by folds elsewhere in the pattern. It turns out to be hard (but fixed-parameter tractable) to determine which of these ways is best with respect to minimizing the thickness of the folded pattern.
All-pairs minimum cuts in near-linear time for surface-embedded graphs.
G. Borradaile,
D. Eppstein,
A. Nayyeri,
and C. Wulff-Nilsen.
arXiv:1411.7055.
Proc. 32nd Int. Symp. Computational Geometry, Boston, 2016.
Leibniz International Proceedings in Informatics (LIPIcs) 51, pp. 22:1–22:16, doi:10.4230/LIPIcs.SoCG.2016.22.
We give the first known near-linear algorithms for constructing Gomory–Hu trees of bounded-genus graphs, and we shave a log off the time for the same problem on planar graphs.
ERGMs are hard.
M. J. Bannister,
W. E. Devanny, and
D. Eppstein.
arXiv:1412.1787.
ERGMs (exponential random graph models) are used in social science to describe probability distributions on graphs that are supposed to mimic real-world social networks. However, we show that (with features that are standard in the social science application) the distributions given by these models can be computationally infeasible to sample from or to approximate the probability of seeing a given graph.
Contact graphs of circular arcs.
M. J. Alam,
D. Eppstein,
M. Kaufmann,
S. Kobourov,
S. Pupyrev
A. Schulz, and
T. Ueckerdt.
arXiv:1501.00318.
14th Algorithms and Data Structures Symp. (WADS 2015), Victoria, BC.
Springer, Lecture Notes in Comp. Sci. 9214 (2015), pp. 1–13, doi:10.1007/978-3-319-21840-3_1.
We study the graphs formed by non-crossing circular arcs in the plane, having a vertex for each arc and an edge for each point where an arc endpoint touches the interior of another arc.
Simple recognition of Halin graphs and their generalizations.
D. Eppstein.
arXiv:1502.05334.
J. Graph Algorithms &
Applications 20 (2): 323–346, 2016, doi:10.7155/jgaa.00395.
We describe and implement a simple linear time algorithm for recognizing Halin graphs based on two simplifications of triples of degree-three vertices in such graphs. Removing some auxiliary data from the algorithm causes it to recognize a broader class of graphs that we call the D3-reducible graphs. We study the properties of these graphs, showing that they share many properties with the Halin graphs.
Finding all maximal subsequences with hereditary properties.
D. Bokal,
S. Cabello,
and D. Eppstein.
Proc. 31st Int. Symp. on Computational Geometry, Eindhoven, the
Netherlands, June 2015.
Leibniz International
Proceedings in Informatics (LIPIcs) 34, pp. 240–254, doi:10.4230/LIPIcs.SOCG.2015.240.
We study problems in which the input is a sequence of points in the plane and we wish to find, for each position in the sequence, the longest contiguous subsequence that begins at that position and has some geometric property. For many natural properties we can find all such maximal subsequences in linear or near-linear time.
Rooted cycle bases.
D. Eppstein,
>J. M. McCarthy, and
B. E. Parrish.
arXiv:1504.04931.
14th Algorithms and Data Structures Symp. (WADS 2015), Victoria, BC.
Springer, Lecture Notes in Comp. Sci. 9214 (2015), pp. 339–350, doi:10.1007/978-3-319-21840-3_28.
J. Graph Algorithms &
Applications 21 (4): 663–686, 2017, doi:10.7155/jgaa.00434.
We consider the problem of finding a cycle basis for a graph in which all basis cycles contain a specified edge. We characterize the graphs having such a basis in terms of their vertex connectivity, we show that the minimum weight cycle basis with this constraint can be found in polynomial time and is weakly fundamental, and we show that finding a fundamental cycle basis with this constraint is \(\mathsf{NP}\)-hard but fixed-parameter tractable.
The parametric closure problem.
D. Eppstein.
arXiv:1504.04073.
14th Algorithms and Data Structures Symp. (WADS 2015), Victoria, BC.
Springer, Lecture Notes in Comp. Sci. 9214 (2015), pp. 327–338, doi:10.1007/978-3-319-21840-3_27.
ACM Trans. Algorithms 14 (1):
Article 2, 2018, doi:10.1145/3147212.
We consider the minimum weight closure problem for a partially ordered set whose elements have weights that vary linearly as a function of a parameter. For several important classes of partial orders the number of changes to the optimal solution as the parameter varies is near-linear, and the sequence of optimal solutions can be found in near-linear time.
Metric dimension parameterized by max leaf number.
D. Eppstein.
arXiv:1506.01749.
J. Graph Algorithms &
Applications 19 (1): 313–323, 2015, doi:10.7155/jgaa.00360.
We prove that when a graph of bounded size has its edges subdivided to form a larger graph, it is still possible to find its metric dimension by a fixed-parameter tractable algorithm, parameterized by the pre-subdivision size of the graph.
Folding polyominoes into (poly)cubes.
O. Aichholzer,
M. Biro,
E. Demaine,
M. Demaine,
D. Eppstein,
S. P. Fekete,
A. Hesterberg,
I. Kostitsyna, and
C. Schmidt.
27th Canadian Conference on Computational Geometry, Kingston, Ontario,
Canada, 2015, pp. 101–106.
arXiv:1712.09317.
Int. J. Comp. Geom. &
Appl. 28 (3): 197–226, 2018, doi:10.1142/S0218195918500048.
We classify the polyominoes that can be folded to form the surface of a cube or polycube, in multiple different folding models that incorporate the type of fold (mountain or valley), the location of a fold (edges of the polycube only, or elsewhere such as along diagonals), and whether the folded polyomino is allowed to pass through the interior of the polycube or must stay on its surface.
Structure of graphs with locally restricted crossings.
V. Dujmović,
D. Eppstein, and
D. R. Wood.
arXiv:1506.04380.
23rd Int. Symp. Graph Drawing, Los Angeles, California, 2015.
Springer, Lecture
Notes in Comp. Sci. 9411 (2015), pp. 87–98, doi:10.1007/978-3-319-27261-0_8.
SIAM J. Discrete Math. 31 (2): 805–824, 2017, doi:10.1137/16M1062879.
The Graph Drawing version used the alternative title "Genus, treewidth, and local crossing number". We prove tight bounds on the treewidth of graphs embedded on low-genus surfaces with few crossings per edge, and nearly tight bounds on the number of crossings per edge for graphs with a given number of edges embedded on low-genus surfaces.
Track layouts, layered path decompositions, and leveled
planarity.
M. J. Bannister,
W. E. Devanny, and
V. Dujmović,
D. Eppstein, and
D. R. Wood.
arXiv:1506.09145.
24th Int. Symp. Graph Drawing, Athens, Greece, 2016.
Springer, Lecture Notes in Comp. Sci. 9801 (2016), pp. 499–510, doi:10.1007/978-3-319-50106-2_38.
Algorithmica 81 (4): 1561–1583, 2019, doi:10.1007/s00453-018-0487-5.
We introduce the concept of a layered path decomposition, and show that the layered pathwidth can be used to characterize the leveled planar graphs. As a consequence we show that finding the minimum number of tracks in a track layout of a given graph is \(\mathsf{NP}\)-complete. The GD version includes only the parts concerning track layout, and uses the title "Track Layout is Hard".
Approximate greedy clustering and distance selection for graph metrics.
D. Eppstein,
S. Har-Peled, and
A. Sidiropoulos.
arXiv:1507.01555.
J. Computational Geometry 11 (1): 629–652, 2020, doi:10.20382/jocg.v11i1a25.
We provide fast approximation algorithms for the farthest-first traversal of graph metrics.
Rigid origami vertices: Conditions and forcing sets.
Z. Abel,
J. Cantarella,
E. Demaine,
D. Eppstein,
T. Hull,
J. Ku,
R. Lang, and
T. Tachi.
arXiv:1507.01644.
J. Computational Geometry 7 (1): 171–184, 2016, doi:10.20382/jocg.v7i1a9.
We give an exact characterization of the one-vertex origami folding patterns that can be folded rigidly, without bending the parts of the paper between the folds.
Confluent orthogonal drawings of syntax diagrams.
M. J. Bannister,
D. A. Brown, and
D. Eppstein.
arXiv:1509.00818.
23rd Int. Symp. Graph Drawing, Los Angeles, California, 2015.
Springer, Lecture
Notes in Comp. Sci. 9411 (2015), pp. 260–271, doi:10.1007/978-3-319-27261-0_22.
We describe a system for transforming context-free grammars into human-readable syntax diagrams, including optimizations that change the structure of the grammar to make it more readable without affecting the language described by the grammar.
Treetopes and their graphs.
D. Eppstein.
arXiv:1510.03152.
27th ACM-SIAM
Symp. on Discrete Algorithms, Arlington, 2016, pp. 969–984, doi:10.1137/1.9781611974331.ch69.
Discrete
Comput. Geom. 64 (2), 259–289, 2020 (special issue for Branko
Grünbaum), doi:10.1007/s00454-020-00177-0.
We describe a class of polytopes of varying dimensions, whose restriction to three dimensions is the class of roofless polyhedra (Halin graphs). We call these polytopes treetopes. We show that the four-dimensional treetopes are closely related to clustered planar graph drawings, and we use this connection to recognize the graphs of four-dimensional treetopes in polynomial time.
On the planar split thickness of graphs.
D. Eppstein,
P. Kindermann,
S. G. Kobourov,
G. Liotta,
A. Lubiw,
A. Maignan,
D. Mondal,
H. Vosoughpour,
S. Whitesides, and
S. Wismath.
arXiv:1512.04839.
Proc. 12th Latin American Theoretical Informatics Symposium (LATIN
2016), Ensenada, Mexico.
Springer, Lecture Notes in Comp. Sci. 9644 (2016), pp. 403–415, doi:10.1007/978-3-662-49529-2_30.
Algorithmica 80
(3): 977–994 (special issue for LATIN), 2018, doi:10.1007/s00453-017-0328-y.
We study the problem of splitting the vertices of a given graph into a bounded number of sub-vertices (with each edge attaching to one of the sub-vertices) in order to make the resulting graph planar. It is \(\mathsf{NP}\)-complete, but can be approximated to within a constant factor, and is fixed-parameter tractable in the treewidth.
From discrepancy to majority.
D. Eppstein
and D. S. Hirschberg.
arXiv:1512.06488.
Proc. 12th Latin American Theoretical Informatics Symposium (LATIN
2016), Ensenada, Mexico.
Springer, Lecture Notes in Comp. Sci. 9644 (2016), pp. 390–402, doi:10.1007/978-3-662-49529-2_29.
Algorithmica 80
(4): 1278–1297, 2018, doi:10.1007/s00453-017-0303-7.
We provide upper and lower bounds on the query complexity of a problem in which the input is a collection of two-colored items, and the problem is to either find an item of the majority color or to determine that there is no majority, by performing queries that determine the discrepancy of fixed-size subsets of the items.
Cuckoo filter: simplification and analysis.
D. Eppstein.
arXiv:1604.06067.
Proc. 15th Scandinavian Symposium and Workshops on Algorithm
Theory (SWAT 2016), Reykjavik, Iceland.
Leibniz International
Proceedings in Informatics (LIPIcs) 53, pp. 8.1–8.12, doi:10.4230/LIPIcs.SWAT.2016.8.
A cuckoo filter is an approximate set data structure that can be used in place of a Bloom filter, but with several practical advantages: it uses less space, has better locality of reference, and can handle element deletions. We provide the first theoretical analysis of a simplified variation of cuckoo filters, showing that these advantages can be guaranteed to hold theoretically and not just experimentally.
The computational hardness of dK-series.
W. E. Devanny,
D. Eppstein, and
B. Tillman.
NetSci2016 poster session, Seoul, Korea.
The dK-series is an extension of the degree sequence of a graph to a d-dimensional tensor, describing the number of d-tuples of vertices with each possible combination of degrees and adjacencies. As we show, it is NP-hard to determine whether such a tensor represents a valid graph, for any d ≥ 3, or for d = 2 if the number of triangles in the graph is also specified (or constrained to be zero).
Models and algorithms for graph watermarking.
D. Eppstein,
M. T. Goodrich,
J. Lam,
N. Mamano,
M. Mitzenmacher, and
M. Torres.
arXiv:1605.09425.
Proc. 19th Information Security Conference (ISC 2016), Honolulu,
Hawaii.
Springer, Lecture Notes in
Comp. Sci. 9866 (2016), pp. 283–301, doi:10.1007/978-3-319-45871-7_18.
We show how to modify a small number of edges in a large social network in order to make the modified copy easy to identify, even if an adversary tries to hide the modification by permuting the vertices and flipping a much larger number of edges. The result depends on the random fluctuation of vertex degrees in such networks, and the ability to uniquely identify vertices by their adjacencies to a small number of high-degree landmark vertices. This paper won the best student paper award at ISC for its student co-authors Lam, Mamano, and Torres.
Maximizing the sum of radii of disjoint balls or disks.
D. Eppstein.
arXiv:1607.02184.
Proc. 28th Canadian Conference on Computational Geometry, Vancouver, BC,
Canada, 2016, pp. 260–265.
J. Computational Geometry 8 (1): 316–339, 2017, doi:10.20382/jocg.v8i1a12.
We show how to find a system of disjoint balls with given centers, maximizing the sum of radius of the balls. Our algorithm takes cubic time in arbitrary metric spaces and can be sped up to subquadratic time in Euclidean spaces of any bounded dimension.
Scheduling autonomous vehicle platoons through an unregulated
intersection.
J. Besa,
W. E. Devanny,
D. Eppstein, and
M. T. Goodrich.
Proc. 16th Worksh. Algorithmic Approaches for Transportation
Modelling, Optimization and Systems (ATMOS 2016), Aarhus, Denmark,
2016.
OpenAccess Series in Informatics (OASIcs) 54, Schloss
Dagstuhl (2016), pp. 5:1–5.16, doi:10.4230/OASIcs.ATMOS.2016.5.
arXiv:1609.04512.
We consider a model of vehicle scheduling in which vehicles arrive at an intersection in indivisible platoons (or individual vehicles of variable length) and the goal is to find a schedule for them to all cross the intersection without collisions, minimizing the maximum delay incurred by any platoon. We show that for many types of intersections, an optimal schedule can be found in polynomial time by a combination of dynamic programming and parametric search.
Spanning trees in multipartite geometric graphs.
A. Biniaz,
P. Bose,
D. Eppstein,
A. Maheshwari,
P. Morin, and
M. Smid.
arXiv:1611.01661.
Algorithmica 80
(11): 3177–3191, 2018, doi:10.1007/s00453-017-0375-4.
We provide near-linear-time algorithms for minimum and maximum spanning trees on Euclidean graphs given by multicolored point sets, where each point forms a vertex, and each bichromatic pair of points forms an edge with length equal to their Euclidean distance.
Covering many points with a small-area box.
M. De Berg,
S. Cabello,
O. Cheong,
D. Eppstein, and
C. Knauer.
arXiv:1612.02149.
J. Computational
Geometry 10 (1): 207–222, 2019, doi:10.20382/jocg.v10i1a8.
We give an efficient algorithm for finding the smallest axis-parallel rectangle covering a given number of points out of a larger set of points in the plane.
K-best solutions of MSO problems on tree-decomposable graphs.
D. Eppstein and
D. Kurz.
arXiv:1703.02784.
Proc. 12th International Symposium on Parameterized and Exact
Computation (IPEC 2017), Vienna, Austria, 2017.
Leibniz International
Proceedings in Informatics (LIPIcs) 89, pp. 16.1–16.13, doi:10.4230/LIPIcs.IPEC.2017.16
We show that, on graphs of bounded treewidth, for any optimization problem definable in monadic second-order logic, we can find the k best solutions in logarithmic time per solution.
Algorithms for stable matching and clustering in a grid.
D. Eppstein,
M. T. Goodrich, and
N. Mamano.
arXiv:1704.02303
Proc. 18th International Workshop on Combinatorial Image Analysis
(IWCIA 2017), Plovdiv, Bulgaria, 2017.
Springer, Lecture Notes in
Comp. Sci. 10256 (2017), pp. 117–131, doi:10.1007/978-3-319-59108-7_10.
Motivated by redistricting, we consider geometric variants of the stable matching problem in which points (such as the pixels of a discretization of the unit square) are to be matched to a smaller number of centers such that each center has the same number of matches and no match is unstable with respect to Euclidean distances. We show how to solve such problems in polylogarithmic time per matched point, experiment with practical heuristics for solving these problems, and test methods for moving the centers to improve the shape of the matched regions.
2-3 cuckoo filters for faster triangle listing and set intersection.
D. Eppstein,
M. T. Goodrich,
M. Mitzenmacher, and
M. Torres.
Proc. 36th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of
Database Systems (PODS 2017), Chicago, 2017, pp. 247–260, doi:10.1145/3034786.3056115.
We show that bit-parallel algorithm design techniques, on a machine of word size w, can speed up the time for sparse set intersection by a factor of log w/w. The main data structure underlying our algorithms is the cuckoo filter, a variant of cuckoo hash tables that has operations similar to a Bloom filter but outperforms Bloom filters in several respects.
Maximum plane trees in multipartite geometric graphs.
A. Biniaz,
P. Bose,
J.-L. De Carufel,
K. Crosbie,
D. Eppstein,
A. Maheshwari,
M. Smid.
15th Algorithms and Data Structures Symp. (WADS 2017), St. John's, Newfoundland.
Springer, Lecture
Notes in Comp. Sci. (2017), pp. 193–204, doi:10.1007/978-3-319-62127-2_17.
Algorithmica 81 (4): 1512–1534, 2019, doi:10.1007/s00453-018-0482-x.
We consider problems of constructing the maximum-length plane (non-self-crossing) spanning tree on Euclidean graphs given by multicolored point sets, where each point forms a vertex, and each bichromatic pair of points forms an edge with length equal to their Euclidean distance. We show that several such problems can be efficiently approximated.
Using multi-level parallelism and 2-3 cuckoo filters for faster
set intersection queries and sparse boolean matrix multiplication.
D. Eppstein and
M. T. Goodrich.
Brief announcement, Proc. 29th ACM Symposium on Parallelism in
Algorithms and Architectures (SPAA), Washington, DC, 2017,
pp. 137–139,
doi:10.1145/3087556.3087599
We provide parallel versions of our bit-parallel algorithms from PODS 2017 for sparse set intersection.
Defining equitable geographic districts in road networks via stable matching.
D. Eppstein,
M. T. Goodrich,
D. Korkmaz, and
N. Mamano.
arXiv:1706.09593
Proc. 25th ACM SIGSPATIAL Int. Conf. Advances
in Geographic Information Systems (ACM SIGSPATIAL 2017),
Redondo Beach, California, pp. 52:1–52:4, doi:10.1145/3139958.3140015.
We cluster road networks (modeled as planar graphs, or more generally as graphs obeying a separator theorem) with a given set of cluster centers, by matching graph vertices to centers stably according to distance: no unmatched vertex and center should have smaller distances than the matched pairs for the same points. We provide a separator-based data structure for dynamic nearest neighbor queries in planar or separated graphs, which allows the optimal stable clustering to be constructed in time \(O(n^{3/2}\log n)\). We also experiment with heuristics for fast practical construction of this clustering.
Forbidden configurations in discrete geometry.
D. Eppstein.
Paul Erdős Memorial Lecture, 29th Canadian Conference on
Computational Geometry, Ottawa, Canada, 2017.
Invited talk, 20th Japan Conference on Discrete
and Computational Geometry, Graphs, and Games, Tokyo, 2017.
Invited talk, 5th International Combinatorics Conference, Melbourne,
Australia, 2017.
Invited talk, Southern California Theory Day, Irvine, California, 2018.
Cambridge University Press, 2018.
We survey problems on finite sets of points in the Euclidean plane that are monotone under removal of points and depend only on the order-type of the points, and the subsets of points (forbidden configurations) that prevent a point set from having a given monotone property.
(CCCG'17 talk slides – CCCG talk video – SCTD talk slides – Updates, errata, and reviews)
Triangle-free penny graphs: degeneracy, choosability, and edge count.
D. Eppstein.
arXiv:1708.05152.
Proc. 25th Int. Symp. Graph Drawing, Boston, Massachusetts, 2017.
Springer, Lecture
Notes in Comp. Sci. 10692 (2018), pp. 506–513, doi:10.1007/978-3-319-73915-1_39.
J. Graph Algorithms &
Applications 22 (3): 483–499 (special issue for GD 2017), 2018, doi:10.7155/jgaa.00463.
A penny graph is the contact graph of unit disks: each disk represents a vertex of the graph, no two disks can overlap, and each tangency between two disks represents an edge in the graph. We prove that, when this graph is triangle free, its degeneracy is at most two. As a consequence, triangle-free penny graphs have list chromatic number at most three. We also show that the number of edges in any such graph is at most \(2n-\Omega(\sqrt{n})\). The journal version uses the alternative title "Edge Bounds and Degeneracy of Triangle-Free Penny Graphs and Squaregraphs".
The effect of planarization on width.
D. Eppstein.
arXiv:1708.05155.
Proc. 25th Int. Symp. Graph Drawing, Boston, Massachusetts, 2017.
Springer, Lecture
Notes in Comp. Sci. 10692 (2018), pp. 560–572, doi:10.1007/978-3-319-73915-1_43.
J. Graph Algorithms &
Applications 22 (3): 461–481 (special issue for GD 2017), 2018, doi:10.7155/jgaa.00468.
We study what happens to nonplanar graphs of low width (for various width measures) when they are made planar by replacing crossings by vertices. For treewidth, pathwidth, branchwidth, clique-width, and tree-depth, this replacement can blow up the width from constant to linear. However, for bandwidth, cutwidth, and carving width, graphs of bounded width stay bounded when we planarize them.
Crossing patterns in nonplanar road networks.
D. Eppstein and
S. Gupta.
arXiv:1709.06113.
Proc. 25th ACM SIGSPATIAL Int. Conf. Advances
in Geographic Information Systems (ACM SIGSPATIAL 2017),
Redondo Beach, California, pp. 40:1–40:9, doi:10.1145/3139958.3139999.
We show that, although an individual edge in a road network can have many crossings, real-world road networks have the property that the crossing graph of their edges is sparse. We prove that networks with this property are themselves sparse and have small separators, allowing many fast algorithms to be generalized from planar graphs to these networks.
Square-contact representations of partial 2-trees and
triconnected simply-nested graphs.
G. Da Lozzo,
W. E. Devanny,
D. Eppstein, and
T. Johnson.
arXiv:1710.00426.
Proc. 28th Int. Symp. Algorithms and Computation (ISAAC 2017),
Phuket, Thailand, 2017.
Leibniz International
Proceedings in Informatics (LIPIcs) 92, pp. 24:1–24:16, doi:10.4230/LIPIcs.ISAAC.2017.24.
We show that the \(K_{1,1,3}\)-free partial 2-trees and the Halin graphs other than \(K_4\) can all be represented as proper contact graphs of squares in the plane. Among partial 2-trees and Halin graphs, these are exactly the ones that can be embedded without nonempty triangles, which form an obstacle to the existence of square contact representations. However the graph of a square antiprism has no such representation despite being embeddable without any nonempty triangles.
Quadratic time algorithms appear to be optimal for sorting
evolving data.
J. Besa,
W. E. Devanny,
D. Eppstein,
M. T. Goodrich, and
T. Johnson.
Proc. Algorithm
Engineering & Experiments (ALENEX 2018), New Orleans, 2018,
pp. 87–96, doi:10.1137/1.9781611975055.8.
arXiv:1805.05443.
We experiment with sorting algorithms in the evolving data model, in which, at the same time as the algorithm compares pairs of elements and possibly chooses a new ordering based on the results of the comparison, an adversary randomly chooses two adjacent elements in the sorted order and swaps them. As we show, bubble sort and its variants appear to maintain an order that is within inversion distance of optimal.
Grid peeling and the affine curve-shortening flow.
D. Eppstein,
S. Har-Peled, and
G. Nivasch.
arXiv:1710.03960.
Proc. Algorithm
Engineering & Experiments (ALENEX 2018),
New Orleans, 2018, pp. 109–116, doi:10.1137/1.9781611975055.10.
Experimental Mathematics 29 (3): 306–316, 2020, doi:10.1080/10586458.2018.1466379.
We conjecture, based on experiments, that approximating a convex shape by the set of grid points inside it, for a fine enough grid, and then finding the convex layers of the resulting point set, produces curves that are close to those produced by affine curve-shortening, a continuous process on smooth curves.
NC algorithms for perfect matching and maximum flow in
one-crossing-minor-free graphs.
D. Eppstein and
V. V. Vazirani.
arXiv:1802.00084.
Proc. 30th ACM Symposium on Parallelism in
Algorithms and Architectures (SPAA 2019), Phoenix, Arizona, 2019, pp. 23–30, doi:10.1145/3323165.3323206.
SIAM J. Computing 50 (3): 1014–1033, 2021, doi:10.1137/19M1256221.
We extend Anari and Vazirani's parallel algorithm for perfect matching in planar graphs to the graph families with a forbidden minor with crossing number one, by developing a concept of mimicking networks for perfect matching.
Reactive proximity data structures for graphs.
D. Eppstein,
M. T. Goodrich, and
N. Mamano.
arXiv:1803.04555.
Proc. 13th Latin American Theoretical Informatics Symposium (LATIN
2018), Buenos Aires, Argentina.
Springer, Lecture Notes in
Comp. Sci. 10807 (2018), pp. 777–789, doi:10.1007/978-3-319-77404-6_56.
We develop data structures for solving nearest neighbor queries for dynamic subsets of vertices in a planar graph, or more generally for a graph in any graph class with small separators (polynomial expansion).
Subexponential-time and FPT algorithms for embedded flat clustered
planarity.
G. Da Lozzo,
D. Eppstein,
M. T. Goodrich, and
S. Gupta.
arXiv:1803.05465
Proc. 44th International Workshop on Graph-Theoretic Concepts in
Computer Science (WG 2018), Lübbenau, Germany.
Springer, Lecture Notes in
Comp. Sci. 11159 (2018), pp. 111–124, doi:10.1007/978-3-030-00256-5_10.
Clustered planarity is the problem of simultaneously drawing a planar graph and a clustering of its vertices (as Jordan curves surrounding the cluster) with no unnecessary crossings between edges or cluster boundaries; it remains unknown whether it can be solved in polynomial time. We provide parameterized and subexponential exact algorithms for the case where the planar embedding is fixed and the clusters form a partition of the vertices.
Faster evaluation of subtraction games.
D. Eppstein.
arXiv:1804.06515.
Proc. 9th Int. Conf. Fun with Algorithms (FUN 2018), La
Maddalena, Italy.
Leibniz International Proceedings in Informatics (LIPIcs) 100, pp. 20:1–20:12, doi:10.4230/LIPIcs.FUN.2018.20.
We show how to evaluate the set of winning heap sizes in subtraction games like subtract-a-square in near-linear time, and how to compute the nim-values more quickly than naive dynamic programming. Additionally we perform computational experiments showing that the set of winning positions forms an unexpectedly dense square-difference-free set.
Making change in 2048.
D. Eppstein.
arXiv:1804.07396.
Proc. 9th Int. Conf. Fun with Algorithms (FUN 2018), La
Maddalena, Italy.
Leibniz International Proceedings in Informatics (LIPIcs) 100, pp. 21:1–21:13, doi:10.4230/LIPIcs.FUN.2018.21.
The 2048 puzzle, modified to use any sequence of integer tile values that has arbitrarily large gaps, always terminates. The proof relates the puzzle to the greedy algorithm for making change (suboptimally) using a given system of coins.
Stable-matching Voronoi diagrams:
combinatorial complexity and algorithms.
G. Barequet,
D. Eppstein,
M. T. Goodrich, and
N. Mamano.
arXiv:1804.09411
Proc. 45th International Colloquium on Automata, Languages, and
Programming (ICALP 2018), Prague.
Leibniz International
Proceedings in Informatics (LIPIcs) 107, pp. 89:1–89:14, doi:10.4230/LIPIcs.ICALP.2018.89.
J. Computational Geometry 11 (1): 26–59, 2020, doi:10.20382/jocg.v11i1a2.
The stable-matching Voronoi diagram of a collection of point sites in the plane, each with a specified area, is a collection of disjoint regions of the plane, one for each site and having the specified area, so that no pair of a point and a site are closer to each other than to the farthest other site and point that they may be matched to. We prove nearly-matching upper and lower bounds on the combinatorial complexity of these diagrams and provide algorithms that can compute them in a polynomial number of primitive steps.
Optimally sorting evolving data.
J. Besa,
W. E. Devanny,
D. Eppstein,
M. T. Goodrich, and
T. Johnson.
arXiv:1805.03350
Proc. 45th International Colloquium on Automata, Languages, and
Programming (ICALP 2018), Prague.
Leibniz International Proceedings in Informatics (LIPIcs) 107, pp. 81:1–81:13, doi:10.4230/LIPIcs.ICALP.2018.81.
Suppose that a collection of objects has a linear order that is evolving by swaps of randomly chosen consecutive elements. We would like to maintain an approximation to this order using an algorithm that performs one comparison per swap. We show that repeated insertion sort can maintain linear inversion distance from the underlying order, the best possible.
Reconfiguration of satisfying assignments and subset sums: Easy
to find, hard to connect.
J. Cardinal,
E. Demaine,
D. Eppstein,
R. Hearn, and
A. Winslow.
arXiv:1805.04055
Proc. 24th International Computing and Combinatorics Conference
(COCOON 2018), Qingdao, China.
Springer, Lecture Notes in
Comp. Sci. 10976 (2018), pp. 365–377, doi:10.1007/978-3-319-94776-1_31.
Theor. Comput. Sci. 806: 332–343, 2020, doi:10.1016/j.tcs.2019.05.028.
For several problems with polynomial-time solutions, we show that finding a sequence of steps that converts one solution into another (maintaining a valid solution at each step) is hard. These include planar monotone not-all-equal 3-sat, subset sum on integers of polynomial magnitude, and 0-1 integer programming with a constant number of linear inequality constraints.
Geometric fingerprint matching via
oriented point-set pattern matching.
D. Eppstein,
M. T. Goodrich,
J. Jorgensen, and
M. Torres.
arXiv:1808.00561
Proc. 30th Canadian Conference on
Computational Geometry, Winnepeg, Canada, 2018, pp. 98–113.
When matching fingerprints, the data involves planar points each of which has an associated direction. Motivated by this application, we consider point matching problems in which the distance between points combines both their translational distance and the rotation needed to make their directions align. We provide fast and simple approximation schemes for matching oriented point sets under the directed Hausdorff distance with different allowed groups of transformations.
Which women mathematicians get written about on Wikipedia, and
why.
D. Eppstein.
AWM
Newsletter 48 (4): 12–14, July–August 2018.
This short opinion piece explains Wikipedia's guidelines for inclusion of articles on academics, and outlines steps to help improve Wikipedia's coverage of women in mathematics.
Parameterized leaf power recognition via embedding into graph products.
D. Eppstein and
E. Havvaei.
arXiv:1810.02452.
Proc. 13th International Symposium on Parameterized and Exact
Computation (IPEC 2018), Helsinki, Finland, 2018.
Leibniz International Proceedings in Informatics (LIPIcs) 115, 2018, pp. 16:1–16:14, doi:10.4230/LIPIcs.IPEC.2018.16.
Algorithmica 82 (8): 2337–2359, 2020 (special issue for IPEC 2018), doi:10.1007/s00453-020-00720-8
A leaf power graph is the graph formed from the leaves of a tree by making two leaves adjacent when their tree distance is at most k. We show that recognizing these graphs is fixed-parameter tractable in a combination of two parameters: k and the degeneracy of the graph.
(James Nastos has pointed out a minor error in our statement of known prior results: the figure depicting chordal graphs that are not 4-leaf powers is labeled as a complete set of forbidden subgraphs, but it is only the complete set among graphs without true twin vertices.)
The parameterized complexity of finding point sets with
hereditary properties.
D. Eppstein and
D. Lokshtanov.
arXiv:1808.02162
Proc. 13th International Symposium on Parameterized and Exact
Computation (IPEC 2018), Helsinki, Finland, 2018.
Leibniz International Proceedings in Informatics (LIPIcs) 115, 2018, pp. 11:1–11:14, doi:10.4230/LIPIcs.IPEC.2018.11.
We exhibit a hereditary property of planar point sets (depending only on the order type of a point set) such that under standard assumptions there is no fixed-parameter-tractable algorithm to find a k-point subset with the property. On the other hand, several natural classes of properties have FPT algorithms for this problem, including the properties that are true for all collinear point sets or false for at least one convex polygon.
Realization and connectivity of the graphs of origami flat foldings.
D. Eppstein.
arXiv:1808.06013.
Proc. 26th Int. Symp. Graph Drawing, Barcelona, 2018.
Springer, Lecture
Notes in Comp. Sci. 11282 (2018), pp. 541–554, doi:10.1007/978-3-030-04414-5_38.
J. Computational Geometry 10 (1): 257–280, 2019, doi:10.20382/jocg.v10i1a10.
If you fold a piece of paper flat and unfold it again, the resulting crease pattern forms a planar graph. We prove that a tree can be realized in this way (with its leaves as diverging rays that reach the boundary of the paper) if and only if all internal vertices have odd degree greater than two. On the other hand, for a folding pattern on an infinite sheet of paper with an added vertex at infinity as the endpoint of all its rays, the resulting graph must be 2-vertex-connected and 4-edge-connected.
Stable-matching Voronoi diagrams.
D. Eppstein.
Invited talk at 21st Japan Conference on Discrete and Computational Geometry, Graphs, and Games (JCDCG3), Manila, Philippines, 2018.
We survey the results from several of my earlier papers: Algorithms for stable matching and clustering in a grid, Defining equitable geographic districts in road networks via stable matching, Reactive proximity data structures for graphs, and Stable-matching Voronoi diagrams: combinatorial complexity and algorithms.
Finding maximal sets of laminar 3-separators in planar graphs in
linear time.
D. Eppstein and
B. Reed.
arXiv:1810.07825.
30th ACM-SIAM Symp. on Discrete Algorithms, San Diego, 2019, pp. 589–605, doi:10.1137/1.9781611975482.37.
Given a 3-vertex-connected planar graph, we find a hierarchical decomposition of the graph by 3-vertex separators, such that each piece of the decomposition is 4-vertex-connected, in linear time. The result has applications to an algorithm of Kawarabayashi, Li, and Reed for finding disjoint paths in nonplanar graphs.
Minor-closed graph classes with bounded layered pathwidth.
V. Dujmović,
D. Eppstein,
G. Joret,
P. Morin, and
D. R. Wood.
arXiv:1810.08314.
SIAM J. Discrete Math 34 (3): 1693–1709, 2020, doi:10.1137/18M122162X.
A minor-closed graph family has a functional relation between diameter and path width (bounded local pathwidth) if and only if it excludes an apex-tree. The same graph families are also the ones with bounded layered pathwidth: a simultaneous path decomposition and layering (sequence of subsets of vertices with all edges connecting the same subset or consecutive subsets) so that the intersection of a bag and a layer has constant size.
Cubic planar graphs that cannot be drawn on few lines.
D. Eppstein.
arXiv:1903.05256.
Proc. 35th Int. Symp. on Computational Geometry, Portland,
Oregon, June 2019.
Leibniz International
Proceedings in Informatics (LIPIcs) 129, 2019, pp. 32:1–32:15, doi:10.4230/LIPIcs.SoCG.2019.32.
J. Computational Geometry 12 (1): 178–197, 2021, doi:10.20382/v12i1a8.
We construct planar graphs whose straight drawings require a large number of lines (at least the cube root of the number of vertices) to cover all vertices. We also find series-parallel graphs and apex-trees that require a non-constant number of lines.
Counting polygon triangulations is hard.
D. Eppstein.
arXiv:1903.04737.
Proc. 35th Int. Symp. on Computational Geometry, Portland, Oregon, June 2019.
Leibniz International
Proceedings in Informatics (LIPIcs) 129, 2019, pp. 33:1–33:17, doi:10.4230/LIPIcs.SoCG.2019.33.
Discrete Comput. Geom. 64 (4): 1210–1234, 2020 (special issue for SoCG 2019), doi:10.1007/s00454-020-00251-7.
Given a polygon with holes, it is \(\#\mathsf{P}\)-complete to determine how many triangulations it has.
Applications of nearest-neighbor chains: Euclidean TSP and motorcycle graphs.
N. Mamano,
A. Efrat,
D. Eppstein,
D. Frishberg,
M. T. Goodrich, and
S. G. Kobourov,
P. Matias, and
V. Polishchuk.
arXiv:1902.06875.
Computational Geometry: Young Researchers Forum, 2019.
Proc. 30th International Symposium on Algorithms and Computation
(ISAAC 2019), Shanghai, China, 2019.
Leibniz International
Proceedings in Informatics (LIPIcs) 149, 2019, pp. 51:1–51:21, doi:10.4230/LIPIcs.ISAAC.2019.51.
We apply the nearest-neighbor chain algorithm to repeatedly find pairs of mutual nearest neighbors for different distances, speeding up the times for the multi-fragment TSP heuristic, motorcycle graphs, straight skeletons, and other problems.
Reconfiguring undirected paths.
E. Demaine,
D. Eppstein,
A. Hesterberg,
K. Jain,
A. Lubiw,
R. Uehara, and
Y. Uno.
arXiv:1905.00518.
16th Algorithms and Data Structures Symp. (WADS 2019), Edmonton,
Alberta.
Springer, Lecture
Notes in Comp. Sci. 11646 (2019), pp. 353–365, doi:10.1007/978-3-030-24766-9_26.
A motion that slides an undirected path along its length from one configuration to another in a graph (allowing moves in both directions) can be found in time that is fixed-parameter tractable in the path length. However the problem is PSPACE-complete for paths of unbounded length, even when the host graph has bounded bandwidth.
Bipartite and series-parallel graphs without planar Lombardi drawings.
D. Eppstein.
arXiv:1906.04401.
Proc. 31st Canadian Conference on
Computational Geometry, Edmonton, Canada, 2019, pp. 17–22.
J. Graph Algorithms &
Applications 25 (1): 549–562, 2021, doi:10.7155/jgaa.00571.
Not every bipartite planar graph has a planar Lombardi drawing. Not every plane series parallel graph has a planar Lombardi drawing with the same embedding. The proof involves the properties of cycles of circular-arc-quadrilaterals all sharing the same two vertices, with equal and sharp vertex angles.
Graphs in nature.
D. Eppstein.
Invited talk at Symposium on Geometry Processing, Milan, Italy, July 2019.
Invited talk at Algorithms and Data Structures Symposium, Edmonton, Canada, August 2019.
Invited talk at International Colloquium on Graph Theory and
Combinatorics, Montpellier, France, July 2022.
I survey results on characterizing the graphs formed on planar surfaces according to several natural processes: motorcycle graphs, Gilbert tessellations, and the contact graphs of line segments from needle-like crystal growth and crack formation; the graphs of planar soap bubble foams; and graphs representing the fold patterns of crumpled paper.
C-planarity testing of embedded clustered graphs with bounded
dual carving-width.
G. Da Lozzo,
D. Eppstein,
M. T. Goodrich, and
S. Gupta.
arXiv:1910.02057.
Proc. 14th International Symposium on Parameterized and Exact
Computation (IPEC 2019), Munich, Germany, 2019 (best paper award).
Leibniz International
Proceedings in Informatics (LIPIcs) 148, 2019, pp. 9:1–9:17, doi:10.4230/LIPIcs.IPEC.2019.9.
Algorithmica
83 (8): 2471–2502, 2021 (special issue for IPEC 2019), doi:10.1007/s00453-021-00839-2.
We show that finding clustered planar drawings can be done in fixed-parameter-tractable time, depending only on a single width parameter of the input clustered graph.
Homotopy height, grid-minor height and graph-drawing height.
T. Biedl,
E. Chambers,
D. Eppstein,
A. de Mesmay, and
T. Ophelders.
arXiv:1908.05706.
Proc. 27th Int. Symp. Graph Drawing, Prague, Czech Republic, 2019.
Springer, Lecture
Notes in Comp. Sci. 11904 (2019), pp. 468–481, doi:10.1007/978-3-030-35802-0_36.
We lower bound the height of a drawing of a planar graph in an integer grid by a topological invariant, the homotopy height, and show that this invariant is equal to the smallest height of a grid graph in which the given graph is a minor.
Ununfoldable Polyhedra with 6 Vertices or 6 Faces.
H. A. Akitaya,
E. Demaine,
D. Eppstein,
T. Tachi, and
R. Uehara.
22nd Japan Conference on Discrete and Computational Geometry, Graphs,
and Games (JCDCG3), Tokyo, Japan, 2019, pp. 27–28.
Comp. Geom. Theory & Applications 103: 101857, 2022, doi:10.1016/j.comgeo.2021.101857.
We find a (nonconvex, but topologically equivalent to convex) polyhedron with seven vertices and six faces that cannot be unfolded to a flat polygon by cutting along its edges. Both the number of vertices and the number of faces are the minimum possible. The JCDCG3 version used the title "Minimal ununfoldable polyhedron".
Some polycubes have no edge-unzipping.
E. Demaine,
M. Demaine,
D. Eppstein, and
J. O'Rourke.
arXiv:1907.08433.
Proc. 32nd Canadian Conference on Computational Geometry, 2020, pp. 101–105.
Geombinatorics 31 (3): 101–109, 2022.
We find polycubes that cannot be cut along a simple path through their vertices and edges and unfolded to form a flat polygon in the plane.
Tracking paths in planar graphs.
D. Eppstein,
M. T. Goodrich,
P. Matias, and
J. A. Liu.
arXiv:1908.05445.
Proc. 30th International Symposium on Algorithms and Computation
(ISAAC 2019), Shanghai, China, 2019.
Leibniz International
Proceedings in Informatics (LIPIcs) 149, 2019, pp. 54:1–54:17, doi:10.4230/LIPIcs.ISAAC.2019.54.
A tracking set for a given graph, with designated start and destination vertices, is a set of vertices such that any path from start to destination is determined by the subsequence of its vertices that belong to the tracking set. We show that finding the smallest tracking set is \(\mathsf{NP}\)-hard but has a constant factor approximation, and can be solved exactly in fixed-parameter-tractable time for graphs of bounded width.
Existence and hardness of conveyor belts.
M. Baird,
S. C. Billey,
E. Demaine,
M. Demaine,
D. Eppstein,
S. P. Fekete,
G. Gordon,
S. Griffin,
J. S. B. Mitchell, and
J. P. Swanson.
arXiv:1908.07668.
Electronic
J. Combinatorics 27 (4), Paper P4.25, 2020, doi:10.37236/9782.
A conveyor belt is a tight simple closed curve that touches each of a given set of disjoint disks. We show that certain special families of disks always have a conveyor belt, but that it is \(\mathsf{NP}\)-complete to tell whether one exists for arbitrary families of disks. It is always possible to add a linear number of "guide disks" to a given set of disks to allow them to be connected by a conveyor belt.
Face flips in origami tessellations.
H. A. Akitaya,
V. Dujmović,
D. Eppstein,
T. Hull,
K. Jain, and
A. Lubiw.
arXiv:1910.05667.
J. Computational Geometry 11 (1): 397–417, 2020, doi:10.20382/jocg.v11i1a15.
We study problems in which we are given an origami crease pattern and seek to reconfigure one locally flat foldable mountain-valley assignment into another by a sequence of operations that change the assignment around a single face of the crease pattern.
Simplifying activity-on-edge graphs.
D. Eppstein,
D. Frishberg, and
E. Havvaei.
arXiv:2002.01610.
Proc. 17th Scandinavian Symposium and Workshops on Algorithm
Theory (SWAT 2020).
Leibniz International
Proceedings in Informatics (LIPIcs) 162, 2020, pp. 24:1–24:14, doi:10.4230/LIPIcs.SWAT.2020.24.
Given a partially ordered set of activities, we find in polynomial time a directed acyclic graph and a mapping from activities to its edges, such that the sequences of activities along paths in the graph are exactly the totally ordered subsets of activities in the input.
Low-stretch spanning trees of graphs with bounded width.
G. Borradaile,
E. Chambers,
D. Eppstein,
W. Maxwell, and
A. Nayyeri.
arXiv:2004.08375.
Proc. 17th Scandinavian Symposium and Workshops on Algorithm
Theory (SWAT 2020).
Leibniz International
Proceedings in Informatics (LIPIcs) 162, 2020, pp. 15:1–15:19, doi:10.4230/LIPIcs.SWAT.2020.15.
We describe a random distribution on the spanning trees of bounded-bandwidth graphs such that each edge has bounded expected stretch, along with several related results for other kinds of graph widths.
On the treewidth of Hanoi graphs.
D. Eppstein,
D. Frishberg, and
W. Maxwell.
arXiv:2005.00179.
Proc. 10th Int. Conf. Fun with Algorithms (FUN 2021).
Leibniz International
Proceedings in Informatics (LIPIcs) 157, 2020, pp. 13:1–13:21, doi:10.4230/LIPIcs.FUN.2021.13.
Theor. Comput. Sci. 906: 1–17, 2022, doi:10.1016/j.tcs.2021.12.014.
The \(n\)-disc \(p\)-peg Hanoi graphs have treewidth within a polynomial factor of \(n^{p-1}\). In a follow-up paper, "On the expansion of Hanoi graphs", we eliminated the polynomial factor.
On the edge crossings of the greedy spanner.
D. Eppstein and
H. Khodabandeh.
arXiv:2002.05854.
Proc. 37th International Symposium on Computational Geometry (SoCG 2021).
Leibniz International
Proceedings in Informatics (LIPIcs) 189, 2021, pp. 33:1–33:17, doi:10.4230/LIPIcs.SoCG.2021.33.
Greedy spanners are graphs formed from sets of geometric points by considering the pairs of points in sorted order by distance and adding an edge whenever a pair cannot be connected by a short path through the previously-added edges. We show that for points in the Euclidean plane, these graphs have linearly many crossings, that the intersection graph of their edges has bounded degeneracy, and that they have separators of square-root size.
Dynamic products of ranks.
D. Eppstein.
arXiv:2007.08123.
Proc. 32nd Canadian Conference on Computational Geometry, 2020, pp. 199–205.
We provide data structures for the following problem: maintain a collection of points in the Euclidean plane, subject to insertions or deletions, and after each update find the point whose product of ranks according to the two sorted orders of the points by x- and y-coordinates is as small or as large as possible.
Acutely triangulated, stacked, and very ununfoldable polyhedra.
E. Demaine,
M. Demaine, and
D. Eppstein.
arXiv:2007.14525.
Proc. 32nd Canadian Conference on Computational Geometry, 2020, pp. 106–113.
We construct non-convex but topologically spherical polyhedra in which all faces are acute triangles, with no unfolded net.
New results in sona drawing: hardness and TSP separation.
M.-W. Chiu,
E. Demaine,
M. Demaine,
D. Eppstein,
R. Hearn,
A. Hesterberg,
M. Korman,
I. Parada, and
M. Rudoy.
arXiv:2007.15784.
Proc. 32nd Canadian Conference on Computational Geometry, 2020, pp. 63–72.
A sona drawing is a self-crossing curve in the plane that separates each of a given system of points into its own region. We show that it is hard to find the shortest such curve, and we explore how much shorter than the TSP it can be.
On polyhedral realization with isosceles triangles.
D. Eppstein.
arXiv:2009.00116.
Graphs and Combinatorics 37 (4): 1247–1269, 2021, doi:10.1007/s00373-021-02314-9.
We find convex polyhedra with all faces triangular that cannot be realized with all faces isosceles, and new families of convex polyhedra with congruent isosceles-triangle faces.
The graphs of stably matchable pairs.
D. Eppstein.
arXiv:2010.09230.
47th International Workshop on Graph-Theoretic Concepts in Computer
Science (WG 2021).
Springer, Lecture
Notes in Comp. Sci. 12911 (2021), pp. 349–360, doi:10.1007/978-3-030-86838-3_27.
If you form a bipartite graph from a stable matching instance, with an edge for each pair that can participate in a stable matching, what graphs can you get? They are matching-covered, but \(\mathsf{NP}\)-hard to recognize, and their structure is related to the structure of the lattice of stable matchings of the same instance.
Stack-number is not bounded by queue-number.
V. Dujmović,
D. Eppstein,
R. Robert Hickingbotham,
P. Morin, and
D. R. Wood.
arXiv:2011.04195.
Combinatorica 42: 151–164, 2022, doi:10.1007/s00493-021-4585-7.
Stack number is also known as page number or book thickness; it is the minimum number of stacks needed so that you can process the vertices of a graph in some sequence, pushing each edge onto one of the stacks when you process its first endpoint and popping it from the same stack when you process its second endpoint. Queue number is defined in the same way using queues instead of stacks. We show that the strong products of triangular grids and high-degree stars have bounded queue number but unbounded stack number. This result disproves the Blankenship–Oporowski conjecture, according to which subdividing edges of a graph a constant number of times cannot decrease its stack number from non-constant to constant, because subdivisions of the same products also have bounded stack number. It also confirms a conjecture of Bonnet et al on the existence of graphs with bounded sparse twin-width and unbounded stack number.
Geometric dominating sets – A minimum version of the
no-three-in-line problem.
O. Aichholzer,
D. Eppstein, and
E.-M. Hainzl.
37th European Workshop on Computational Geometry (EuroCG 2021), pp. 17:1–17:7.
arXiv:2203.13170.
Comp. Geom. Theory & Applications 108: 101913, 2023 (special issue for EuroCG), doi:10.1016/j.comgeo.2022.101913.
We study how few points can be placed in a grid so that all remaining grid points are collinear with two of the placed points. The illustration below was sent to me by Ed Pegg.

(Blog post: How good is greed for the no-three-in-line problem?)
A stronger lower bound on parametric minimum spanning trees.
D. Eppstein.
arXiv:2105.05371.
17th Algorithms and Data Structures Symp. (WADS 2021).
Springer, Lecture
Notes in Comp. Sci. 12808 (2021), pp. 343–356, doi:10.1007/978-3-030-83508-8_25.
Algorithmica 85: 1738–1753, 2023 (special issue for WADS 2021), doi:10.1007/s00453-022-01024-9.
There exist graphs with edges labeled by linear real functions, such that the number of different minimum spanning trees obtained for different choices of the function argument is \(\Omega(m\log n)\).
Angles of arc-polygons and Lombardi drawings of cacti.
D. Eppstein,
D. Frishberg, and
M. Osegueda.
arXiv:2107.03615.
Proc. 33rd
Canadian Conference on Computational Geometry, 2021,
pp. 56–64.
Comp. Geom. Theory & Applications 112: 101982, 2023 (special issue for CCCG 2021), doi:10.1016/j.comgeo.2023.101982.
We precisely characterize the triples vertex angles that are possible for arc-triangles (curved triangles made from circular arcs), and prove an existence theorem for a large class of sets of angles for arc-polygons. Our characterization allows us to prove that every cactus graph has a planar Lombardi drawing for its natural planar embedding (the embedding in which each cycle is a bounded face), but that there exist other embeddings of cacti that have no Lombardi drawing.
Parameterized complexity of finding subgraphs with hereditary
properties on hereditary graph classes.
D. Eppstein,
E. Havvaei, and
S. Gupta.
arXiv:2101.09918.
Proc. 23rd International Symposium on Fundamentals of Computation
Theory, 2021.
Springer, Lecture
Notes in Comp. Sci. 12867 (2021), pp. 217–229, doi:10.1007/978-3-030-86593-1_15.
We provide a partial classification of the complexity of parameterized graph problems of the form "find a \(k\)-vertex induced subgraph with property \(X\) in a larger subgraph with property \(Y\)", in terms of the existence of large cliques and large independent sets in the graphs with properties \(X\) and \(Y\).
Distributed construction of lightweight spanners for unit ball graphs.
D. Eppstein and
H. Khodabandeh.
arXiv:2106.15234.
Brief
announcement, 34th ACM Symposium on Parallelism in Algorithms and
Architectures, 2022, pp. 57–59, doi:10.1145/3490148.3538553.
Proc. 36th International Symposium on Distributed Computing (DISC
2022).
Leibniz International
Proceedings in Informatics (LIPIcs) 246, 2022,
pp. 21:1–21:23, doi:10.4230/LIPIcs.DISC.2022.21.
Metric spaces of bounded doubling dimension have spanners with bounded degree, weight a bounded multiple of the minimum spanning tree weight, and dilation arbitrarily close to one, that can be found efficiently by a distributed algorithm.
Limitations on realistic hyperbolic graph drawing.
D. Eppstein.
arXiv:2108.07441.
Proc. 29th Int. Symp. Graph Drawing, Tübingen, Germany, 2021.
Springer, Lecture
Notes in Comp. Sci. 12868 (2021), pp. 343–357, doi:10.1007/978-3-030-92931-2_25.
Graphs drawn in the hyperbolic plane can be forced to have features much closer together than unit distance, in the absolute distance scale of the plane. In particular this is true for planar drawings of maximal planar graphs or grid graphs, and for nonplanar drawings of arbitrary graphs.
Multifold tiles of polyominoes and convex lattice polygons.
K. Chida,
E. Demaine,
M. Demaine,
D. Eppstein,
A. Hesterberg,
T. Horiyama,
J. Iacono,
H. Ito,
S. Langerman,
R. Uehara, and
Y. Uno.
23rd Thailand-Japan Conference on Discrete and Computational
Geometry, Graphs, and Games, 2021, pp. 28–29.
Thai Journal of Mathematics 21 (4): 957–978, 2023.
We investigate shapes whose congruent copies can cover the plane exactly \(k\) times per point, but not a number of times that is a nonzero integer smaller than \(k\). We find polyominoes with this property for all \(k\ge 2\), and convex integer-coordinate polygons with this property for \(k=5\) and for all \(k\ge 7\).
Egyptian fractions with denominators from sequences closed under doubling.
D. Eppstein.
J. Integer Sequences 24: 21.8.8, 2021.
arXiv:2109.12217.
We prove that if a set of positive integers includes multiples of all integers, and is closed under multiplication by two, then its reciprocals can form Egyptian fractions for every rational number up to the sum of reciprocals of the set.
See also "Ten algorithms for Egyptian fractions".
Finding relevant points for nearest-neighbor classification.
D. Eppstein.
arXiv:2110.06163.
Proc. SIAM Symp. Simplicity in Algorithms, 2022, pp. 68–78, doi:10.1137/1.9781611977066.6 (best paper award).
The nearest-neighbor classification problem considered here takes as input a training set of points in a Euclidean space, each with a classification from some finite set of classes or colors, and then uses that input to predict the classification of new points as being equal to that of the nearest neighbor in the input training set. A training point is irrelevant when removing it from the training set would produce the same predicted classification for all possible new points that might be queried. We describe how to find all of the relevant points, in polynomial time, using a simple algorithm whose only components are construction of a minimum spanning tree of the training set and the computation of extreme points (convex hull vertices) of geometrically transformed subsets of points. For any constant dimension, with \(k\) relevant points resulting from a training set of \(n\) points, this method can be made to take time \(O(n^2+k^2n)\), using only simple algorithms for the minimum spanning tree and extreme point subroutines. For small dimensions, somewhat better but more complicated bounds are possible.
Rapid mixing of the hardcore Glauber dynamics and other Markov chains in bounded-treewidth graphs.
D. Eppstein and
D. Frishberg.
arXiv:2111.03898.
Proc 34th International Symposium on Algorithms and Computation (ISAAC 2023).
Leibniz International
Proceedings in Informatics (LIPIcs) 283, 2022, pp. 30:1–30:13, doi:10.4230/LIPIcs.ISAAC.2023.30.
A random walk on the independent sets or dominating sets of a graph mixes rapidly for graphs of bounded treewidth, and a random walk on maximal independent sets mixes rapidly for graphs of bounded carving width.
The complexity of iterated reversible computation.
D. Eppstein.
arXiv:2112.11607.
Invited talk at 15th Latin American Theoretical Informatics Symposium,
Guanajuato, Mexico, November 2022.
TheoretiCS 2: A10:1–A10:41, 2023, doi:10.46298/theoretics.23.10.
We study a class of problems involving computing a value \(f^{(n)}(x)\), the \(n\)th iterate of a function \(f\), for polynomial time bijections. We prove that these problems are complete for \(\mathsf{P}^{\mathsf{PSPACE}}\), and include hard problems in circuit complexity, graph algorithms, the simulation of one- and two-dimensional automata, and dynamical systems. We also provide a polynomial time algorithm for the special case where the bijection is an interval exchange transformation.
Three-dimensional graph products with unbounded stack-number.
D. Eppstein,
R. Robert Hickingbotham,
L. Merker,
S. Norin,
M. T. Seweryn, and
D. R. Wood.
arXiv:2202.05327.
Discrete Comput. Geom. 71: 1210–1237, 2024, doi:10.1007/s00454-022-00478-6.
The strong product of any three graphs of non-constant size has unbounded book thickness. In the case of strong products of three paths, and more generally of triangulations of \(n\times n\times n\) grid graphs obtained by adding a diagonal to each square of the grid, the book thickness is \(\Theta(n^{1/3})\). This is the first explicit example of a graph family with bounded maximum degree and unbounded book thickness.
Orthogonal dissection into few rectangles.
D. Eppstein.
arXiv:2206.10675.
34th Canadian Conference on Computational Geometry, 2022, pp. 143–150.
Discrete Comput. Geom. 73 (1): 129–148, 2025, doi:10.1007/s00454-023-00614-w.
The rank of the Dehn invariant of an orthogonal polygon equals the minimum number of rectangles into which it can be transformed by axis-parallel cuts, translation, and gluing. This allows the minimum number of rectangles to be calculated in polynomial time.
Reflections in an octagonal mirror maze.
D. Eppstein.
arXiv:2206.11413.
34th Canadian Conference on Computational Geometry, 2022, pp. 129–134.
For two-dimensional scenes consisting of mirrors and opaque walls that are either axis-parallel or with slope ±1, with integer endpoints, it is possible to determine the eventual destination of rational light rays in time polynomial in the description complexity of the scene, even though the number of reflections before a ray reaches this destination may be exponential. The solution involves transforming the problem into one involving interval exchange transformations and from there into another problem involving normal curves on topological surfaces.
Locked and unlocked smooth embeddings of surfaces.
D. Eppstein.
arXiv:2206.12989.
34th Canadian Conference on Computational Geometry, 2022, pp. 135–142.
Computing in Geometry and Topology 2 (2): 5.1–5.20, 2023, doi:10.57717/cgt.v2i2.28.
If a subset of the plane has a continuous shrinking motion of itself, then every smooth isometric embedding of that subset into 3d can be smoothly flattened. However, there exist subsets of the plane with holes, for which some smooth embeddings that are topologically equivalent to a flat embedding cannot be smoothly flattened.
Improved mixing for the convex polygon triangulation flip walk.
D. Eppstein and
D. Frishberg.
arXiv:2207.09972.
Proc. 50th EATCS International Colloquium on Automata, Languages, and Programming (ICALP 2023).
Leibniz International
Proceedings in Informatics (LIPIcs) 261, 2023, pp. 56:1–56:17, doi:10.4230/LIPIcs.ICALP.2023.56.
The associahedron is a polytope whose vertices represent the triangulations of a convex polygon, and whose edges represent flips connecting one triangulation to another. We show that a random walk on the edges of this polytope rapidly converges to the uniform distribution on triangulations. However, we also show that the associahedron does not have constant expansion.
Geodesic paths passing through all faces on a polyhedron.
E. Demaine,
M. Demaine,
D. Eppstein,
H. Ito,
Y. Katayama,
W. Maruyama, and
Y. Uno.
24th Japan Conference on Discrete and Computational Geometry, Graphs, and Games, September 9–11, 2022.
Springer, Lecture
Notes in Comp. Sci. 14364 (2026), pp. 184–209, doi:10.1007/978-3-032-00281-5_12.
Which convex polyhedra have the property that there exist two points on the surface of the polyhedron whose shortest path passes through all of the faces of the polyhedron? The answer is yes for the tetrahedron, and for certain prisms, but no for all other regular polyhedra.
Product structure extension of the Alon–Seymour–Thomas theorem.
M. Distel,
V. Dujmović,
D. Eppstein,
R. Robert Hickingbotham,
G. Joret,
P. Micek,
P. Morin,
M. T. Seweryn, and
D. R. Wood.
arXiv:2212.08739.
SIAM J. Discrete
Math. 38 (3): 2095–2107, 2024, doi:10.1137/23M1591773.
The graphs in any nontrivial minor-closed graph family can be represented as strong products of a graph of treewidth 4 with a clique of size \(O(\sqrt{n})\). For planar graphs and \(K_{3,t}\)-minor-free graphs, the treewidth can be reduced to 2.
On the biplanarity of blowups.
D. Eppstein.
arXiv:2301.09246.
Proc. 31st Int. Symp. Graph Drawing and Network Visualization, Palermo, Italy, 2023 (best paper award).
Springer, Lecture Notes in Computer Science 14465 (part I), pp. 3–17, doi:10.1007/978-3-031-49272-3_1.
J. Graph Algorithms &
Applications 28 (2): 83–99, 2024, doi:10.7155/jgaa.v28i2.2989.
Expanding every vertex of a planar graph to two independent copies can produce a graph of thickness greater than two, disproving a conjecture of Ellen Gethner. We also investigate special cases of this construction for which the thickness is two, such as the graphs whose edges can be decomposed into a path and a dual path.
Non-crossing Hamiltonian paths and cycles in output-polynomial time.
D. Eppstein.
arXiv:2303.00147.
Proc. 39th International Symposium on Computational Geometry (SoCG 2023).
Leibniz
International Proceedings in Informatics (LIPIcs) 258, 2023,
pp. 29:1–29:16, doi:10.4230/LIPIcs.SoCG.2023.29.
Algorithmica 86: 3027–3053, 2024, doi:10.1007/s00453-024-01255-y.
Inaugural
Algorithmica best paper award, 2025.
For any point set, the numbers of non-crossing paths, non-crossing Hamiltonian paths, non-crossing surrounding polygons, and non-crossing Hamiltonian cycles can be bounded above and below by functions of two simple parameters: the minimum number of points whose deletion leaves a collinear subset, and the number of points interior to the convex hull. Because their bounds have the same form, the numbers of the two types of paths are bounded by polynomials of each other, as are the numbers of the two types of polygons. We use these relations to list non-crossing Hamiltonian paths and polygonalizations in time polynomial in the number of outputs.
On the complexity of embedding in graph products.
T. Biedl,
D. Eppstein, and
T. Ueckerdt.
arXiv:2303.17028.
Proc. 35th Canadian Conference on Computational Geometry, 2023, pp. 77–88.
Computing in Geometry and Topology 4 (2): 5:1–5:18, 2025, doi:10.57717/cgt.v4i2.56.
Row treewidth (embedding a graph as a subgraph of a strong product of a path with a low treewidth graph), row pathwidth, and row tree-depth are all \(\mathsf{NP}\)-hard.
Lower bounds for non-adaptive shortest path relaxation.
D. Eppstein.
arXiv:2305.09230.
Proc. 18th Algorithms and Data Structures Symposium (WADS 2023).
Springer, Lecture Notes in Computer Science 13079 (2023), pp. 416–429, doi:10.1007/978-3-031-38906-1_27.
The Bellman–Ford algorithm for single-source shortest paths operates by relaxation steps, in which it checks for a given edge whether the best path it knows to the start of the edge, plus the edge itself, is better than the path it already knows to the end of the edge. We prove that, up to constant factors, Bellman–Ford is optimal among algorithms that use relaxation in an edge ordering that does not depend on the results of earlier relaxation steps.
Widths of geometric graphs.
D. Eppstein.
Invited talk, Workshop
on Parameterized Algorithms for Geometric Problems, CG Week 2023.
Many computational geometry problems can be solved by transforming them into a graph problem on a geometric graph. When the graph has low width, for some form of graph width, this can often lead to efficient classical or parameterized algorithms. We survey the geometric graphs that always have low width, the geometric graphs that can have high width, and the opportunities for parameterization obtained by studying low-width instances of graphs that sometimes have high width.
A parameterized algorithm for flat folding.
D. Eppstein.
arXiv:2306.11939.
Proc. 35th Canadian Conference on Computational Geometry, 2023, pp. 35–42.
Testing whether an origami folding pattern can be folded flat is fixed-parameter tractable when parameterized by two parameters: the ply (maximum number of layers) of the folding, and the treewidth of a planar graph describing the arrangement of polygons in the flat-folded result. The dependence on treewidth is optimal under the exponential-time hypothesis.
Merged into "Computational complexities of folding" for journal submission.
Geometric graphs with unbounded flip-width.
D. Eppstein and
R. McCarty.
arXiv:2306.12611.
Proc. 35th Canadian Conference on Computational Geometry, 2023, pp. 197–208.
We show that many constructions for dense geometric graphs produce graphs of unbounded flip-width, frustrating the search for natural classes of graphs that have bounded flip-width but unbounded twin-width.
(Blog posts: Geometric graphs with unbounded flip-width and Geometric flip-width revisited)
Quasipolynomiality of the smallest missing induced subgraph.
D. Eppstein,
A. Lincoln,
and V. V. Williams.
arXiv:2306.11185.
J. Graph Algorithms & Applications 27 (5): 329–339, 2023, doi:10.7155/jgaa.00625.
The smallest graph that is not an induced subgraph of a given graph can be found in time \(n^{O(\log n)}\). The exponent is optimal, up to constant factors, under the exponential time hypothesis.
Manipulating weights to improve stress-graph drawings of 3-connected planar graphs.
A. Chiu,
D. Eppstein,
and M. T. Goodrich.
arXiv:2307.10527.
Proc. 31st Int. Symp. Graph Drawing and Network Visualization, Palermo, Italy, 2023.
Springer, Lecture Notes in Computer Science 14466 (part II), pp. 141–149, doi:10.1007/978-3-031-49275-4_10.
In Tutte spring embeddings for planar graphs, it is possible to adjust the strengths of the springs and the fixed positions of the vertices on the outer face to obtain an infinite continuous family of straight-line planar embeddings. We experiment with making those adjustments to spread out the features of the drawing to better positions than they would have in the unweighted case.
(Blog post: Well-spaced spring embeddings and well-spaced polyhedra)
The widths of strict outerconfluent graphs.
D. Eppstein.
arXiv:2308.03967.
Proc. 31st Int. Symp. Graph Drawing and Network Visualization, Palermo, Italy, 2023 (poster session).
Springer, Lecture Notes in Computer Science 14466 (part II), pp. 244–247.
Discrete Mathematics & Theoretical Computer Science 26 (3) 20:1–20:17, 2024, doi:10.46298/dmtcs.12862.
We construct a family of strict outerconfluent graphs with unbounded clique-width. In contrast, we use a counting argument to prove that strict outerconfluent graphs have bounded twin-width.
(GD'23 poster – GD'23 proceedings summary – Blog post: The widths of strict outerconfluent graphs)
Uniqueness in puzzles and puzzle solving.
D. Eppstein.
Minisymposium on Mathematical Puzzles and Games in Theoretical Computer
Science, ICIAM, Waseda Univ., Tokyo, Japan, 2023.
In puzzles such as Sudoku, one can often make use of an assumption that the solution is unique, in deduction rules that eliminate alternatives that would lead to a non-unique solution. However, these rules can lack the monotonicity properties of other deduction rules, under which a conclusion that can be deduced from some partially-solved state of the puzzle remains available to be deduced until it actually is deduced. I discuss a method of obtaining monotonic deductions in a planar precoloring extension puzzle, and ask whether there is some more general method for obtaining monotonicity in this way.
Games on game graphs.
D. Eppstein.
AMS Special Session on Serious Recreational Mathematics,
Joint Mathematics Meetings, San Francisco, 2024.
This talk surveys graph parameters defined from pursuit-evasion games on graphs, including cop-number, treewidth, and flip-width, and the values of these parameters on graphs derived from games and puzzles.
Non-Euclidean Erdős–Anning theorems.
D. Eppstein.
arXiv:2401.06328.
41st International Symposium on Computational Geometry (SoCG 2025), Kanazawa, Japan.
Leibniz
International Proceedings in Informatics (LIPIcs) 332, 2025,
pp. 46:1–46:15, doi:10.4230/LIPIcs.SoCG.2025.46.
J. Computational Geometry 17 (2): 46–76, 2026, doi:10.20382/jocg.v17i2a2 (special issue for SoCG 2025).
Non-collinear point sets with integer distances must be finite, for strictly convex distance functions on the plane, for two-dimensional complete Riemannian manifolds of bounded genus, and for geodesic distance on convex surfaces in 3d.
For related results on higher-dimensional Euclidean and hyperbolic spaces, see "Tangent spheres and integer distances".
(SoCG'25 talk slides – Blog post: Integer distances in floppy metric spaces)
Maintaining light spanners via minimal updates.
D. Eppstein and
H. Khodabandeh.
arXiv:2403.03290.
Proc. 36th Canadian Conference on Computational Geometry, 2024, pp. 1–15.
We find a way to maintain a spanner of a dynamic point set, a graph approximating its distances to within a \(1+\varepsilon\) factor while maintaining weight proportionate to the minimum spanning tree. Each change to the point set leads to a logarithmic number of changes to the spanner, although update times remain slow.
Well-separated multiagent path traversal.
G. Dilman,
D. Eppstein,
V. Polishchuk, and
C. Schmidt.
Proc. 36th Canadian Conference on Computational Geometry, 2024, pp. 137–144.
We find algorithms and lower bounds for scheduling a sequence of release times for robots to follow the same path as each other, traversing the path at uniform speeds, and not colliding.
What is ... treewidth?.
D. Eppstein.
Notices
of the American Mathematical Society 72 (2): 172–175,
2025, doi:10.1090/noti3043.
We survey graph treewidth at a high level. The focus is on applications of treewidth to various areas of mathematics.
Computational complexities of folding.
D. Eppstein.
Invited talk,
8th International Meeting on Origami in Science, Mathematics and
Education, Melbourne, Australia, 2024.
Invited talk, 26th Japan Conference
on Discrete and Computational Geometry, Graphs, and Games, Tokyo, 2024.
arXiv:2410.07666.
Journal of
Information Processing 33: 954–973, 2025, doi:10.2197/ipsjjip.33.954.
We survey known hardness results on folding origami and prove several new ones: finding a flat-folded state is \(\mathsf{NP}\)-hard, but fixed-parameter tractable in a combination of ply and the treewidth of an associated graph. Finding a 3d-folded state cannot be expressed in closed form and cannot be computed by bounded-degree algebraic-root primitives. Reconfiguring certain systems of overlapping origami squares, hinged to a table at one edge, is \(\mathsf{PSPACE}\)-complete, and counting the number of configurations is \(\#\mathsf{P}\)-complete. Testing flat-foldability of infinite fractal folding patterns (even on normal square origami paper) is undecidable.
The journal version merges results from "A parameterized algorithm for flat folding".
Drawing planar graphs and 1-planar graphs using cubic Bézier
curves with bounded curvature.
D. Eppstein,
M. T. Goodrich, and
A. M. Illickan.
32nd International Symposium on Graph Drawing and Network
Visualization.
Leibniz
International Proceedings in Informatics (LIPIcs) 320, 2024,
pp. 39:1–39:17, doi:10.4230/LIPIcs.GD.2024.39.
arXiv:2410.12083.
1-planar graphs are the graphs that can be drawn in the plane with at most one crossing per edge. We show that we can make all crossings into right angles using Bézier spline curve edges.
Noncrossing longest paths and cycles.
G. Aloupis,
A. Biniaz,
P. Bose,
J.-L. De Carufel,
D. Eppstein,
A. Maheshwari,
S. Odak,
M. Smid,
C. Tóth, and
P. Valtr.
32nd International Symposium on Graph Drawing and Network
Visualization.
Leibniz
International Proceedings in Informatics (LIPIcs) 320, 2024,
pp. 36:1–36:17, doi:10.4230/LIPIcs.GD.2024.36.
arXiv:2410.05580.
Graphs and Combinatorics 41, article 122 (25pp), 2025, doi:10.1007/s00373-025-02985-8.
The shortest path or cycle through given planar points (the solution to the traveling salesperson problem) never crosses itself: any crossing can be eliminated by a local move that shortens the tour. One might think that, correspondingly, the longest path or cycle through enough planar points always crosses itself. We show that this is not the case: there exist arbitrarily large point sets for which the longest path or cycle has no crossing.
Fast Schulze voting using quickselect.
A. Arora,
D. Eppstein, and
R. L. Huynh.
arXiv:2411.18790.
J. Graph Algorithms & Applications 30 (1): 237–252, 2026,
doi:10.7155/jgaa.v30i1.3030.
We show how to determine the outcome of a Schulze method election, from an input consisting of an \(m\times m\) array of pairwise margins of victory, in time \(O(m^2\log m)\). The algorithm uses random pivoting like that of quickselect.
Princ-wiki-a mathematica: Wikipedia editing and mathematics.
D. Eppstein,
J. B. Lewis,
R. Woodroofe,
and X. Easter.
arXiv:2412.20419.
Notices of the AMS 72 (1): 65–73, 2025,
doi:10.1090/noti3096.
We describe the experience of editing mathematics articles on Wikipedia, with the aim of providing helpful advice for new editors and encouraging mathematicians to become Wikipedia editors.
Computational geometry with probabilistically noisy primitive operations.
D. Eppstein,
M. T. Goodrich,
and V. Sridhar.
arXiv:2501.07707.
Proc. 19th Algorithms and Data Structures Symposium (WADS 2025).
Leibniz
International Proceedings in Informatics (LIPIcs) 349, 2025,
pp. 24:1–24:20, doi:10.4230/LIPIcs.WADS.2025.24.
An algorithm that uses Boolean primitive operations, like comparisons, that may be erroneous with some small independent probability per call, may be made to run correctly with high probability by repeating each primitive enough times to be sure its majority result is correct, but this incurs a logarithmic time penalty. Prior work avoids this penalty for sorting; we extend this speedup to algorithms in computational geometry that can be formulated using path search in DAGs. Applications of our "path-guided pushdown random walk" technique include point location, plane sweep, convex hulls, and Delaunay triangulation.
Zip-tries: simple dynamic data structures for strings.
D. Eppstein,
O. Gila,
M. T. Goodrich,
and R. Kitagawa.
SIAM Conference on Applied and Computational Discrete Algorithms
(ACDA25), Montreal, Canada, 2025, pp. 130–143, doi:10.1137/1.9781611978759.10.
arXiv:2505.04953.
We provide fast parallel and bit-parallel data structures for string search in a dynamic set of strings, with few bits of metadata per node.
Better late than never: the complexity of arrangements of polyhedra.
B. Aronov,
S. W. Bae,
O. Cheong,
D. Eppstein,
C. Knauer, and
R. Seidel.
41st European Workshop on Computational Geometry (EuroCG 2025),
Liblice, Czech Republic, pp. 62:1–62:4.
arXiv:2506.03960.
My 1994 paper "On the number of minimal 1-Steiner trees" with Aronov and Bern, in some preliminary manuscript versions, included a bound of \(O(m^{\lceil d/2\rceil}n^{\lfloor d/2\rfloor})\) on the complexity of an arrangement of \(m\) convex polytopes given as intersections of a total of \(n\) halfspaces, interpolating between the upper bound theorem for polytopes and the complexity of hyperplane arrangements. However, the manuscript and the proof were lost. This paper re-proves the result, with better care for the degenerate cases.
Bandwidth vs BFS width in matrix reordering, graph
reconstruction, and graph drawing.
D. Eppstein,
M. T. Goodrich,
and S. Liu.
arXiv:2505.10789.
Proc. 33rd Annual European Symposium on Algorithms (ESA 2025).
Leibniz
International Proceedings in Informatics (LIPIcs) 351, 2025,
pp. 69:1–69:17, doi:10.4230/LIPIcs.ESA.2025.69.
In graphs of bounded bandwidth, the number of vertices per level of a breadth-first search tree is at most polylogarithmic, with the exponent of the polylogarithm both upper and lower bounded by functions of the bandwidth. This has applications to the Cuthull-McKee heuristic and reverse Cuthull-McKee heuristic in sparse numerical algebra, to reconstructing an unknown graph by shortest distance queries, and to drawing graphs as arc diagrams of small height.
Decremental greedy polygons and polyhedra without sharp angles.
D. Eppstein.
arXiv:2507.04538.
Proc. 37th
Canadian Conference on Computational Geometry, 2025,
pp. 85–91.
For given elements and a quality function of an element in a subset, monotonically non-increasing with respect to removals of other elements, we can find the max-min-quality subset by a decremental greedy algorithm that repeatedly removes low-quality subsets. We apply this method to find the max-min-angle polygon for points in the plane, the max-min-weight cycle in a directed graph, and several generalizations of both problems.
Entropy-bounded computational geometry made easier and sensitive to sortedness.
D. Eppstein,
M. T. Goodrich,
A. M. Illickan, and
C. A. To.
arXiv:2508.20489.
Proc. 37th
Canadian Conference on Computational Geometry, 2025,
pp. 53–61.
We define a notion of structural entropy of point sets under which a set has low entropy when it can be covered by few disjoint triangles that are either entirely under the hull of the input or presorted, and show that we can find the hull in time sensitive to this entropy. Generalizations of the same technique apply to geometric maxima, lower envelopes, and visibility polygons.
Stabbing faces by a convex curve.
D. Eppstein.
arXiv:2508.17549.
33rd International Symposium on Graph Drawing and Network
Visualization.
Leibniz
International Proceedings in Informatics (LIPIcs) 357, 2025,
pp. 29:1–29:8, doi:10.4230/LIPIcs.GD.2025.29.
For each smooth convex curve \(C\), and each planar graph \(G\), there exists a straight-line drawing of \(G\) all of whose faces are crossed by \(C\). This result serves as a counterexample to an argument that universal point sets for planar graph drawing cannot be covered by few convex polygons.
String graph obstacles of high girth and of bounded degree.
M. Chudnovsky,
D. Eppstein,
and D. Fischer.
arXiv:2509.00278.
33rd International Symposium on Graph Drawing and Network
Visualization.
Leibniz
International Proceedings in Informatics (LIPIcs) 357, 2025,
pp. 24:1–24:18, doi:10.4230/LIPIcs.GD.2025.24.
String graphs, the intersection graphs of curves in the plane, are closed under induced minors (induced subgraphs of contractions), and were known to have infinitely many obstacles under the induced minor order, but these obstacles were very dense. We find an infinite class of obstacles that are nearly-planar (one edge away from being planar) but we prove that there are no subcubic obstacles of high girth. Recognizing string graphs is known to be \(\mathsf{NP}\)-complete (unusually, the hard part of this result is proving that recognition belongs to \(\mathsf{NP}\)); we use Courcelle's theorem to give a fixed-parameter tractable algorithm for recognizing subcubic string graphs, parameterized by treewidth.
Visualizing treewidth.
A. Chiu,
T. Depian,
D. Eppstein,
M. T. Goodrich,
and
M. Nöllenburg.
arXiv:2508.19935.
33rd International Symposium on Graph Drawing and Network
Visualization.
Leibniz
International Proceedings in Informatics (LIPIcs) 357, 2025,
pp. 17:1–17:20, doi:10.4230/LIPIcs.GD.2025.17.
J. Graph Algorithms & Applications, to appear.
We experiment with metro-map style visualizations of tree decompositions of graphs. Here, the bags of a tree decomposition are visualized as stations on a metro system, and the vertices of a graph are visualized as metro lines passing through certain stations. Within each bag we display a drawing of the induced subgraph of the bag.
Bicriteria polygon aggregation with arbitrary shapes.
L. Blank,
D. Eppstein,
J.-H. Haunert,
H. Haverkort,
B. Kolbe,
P. Mayer,
P. Mutzel,
A. Naumann, and
J. Sauer.
arXiv:2507.11212.
Proc. 34th Annual European Symposium on Algorithms (ESA 2026), to appear.
We consider a problem of shape aggregation in which we cluster a collection of disjoint regions in the plane by finding a collection of surrounding shapes, covering all the given regions and minimizing a linear combination of area and perimeter. The tradeoff between area and perimeter gives us a nested family of clusterings ranging from each given region forming its own cluster to a single cluster for all the regions. The cluster boundaries are straight line segments and circular arcs, leading to a discretization of the clustering problem that allows its optimal solution to be found in polynomial time by a transformation to network flow.
(Blog post: Enclosures that minimize the sum of area and perimeter)
Hamiltonian cycles in subdivided doubles.
D. Eppstein.
arXiv:2510.18359.
Ars Mathematica Contemporanea, to appear.
The subdivided double construction turns a 4-regular graph into a bigger 4-regular graph, by subdividing each edge and doubling each vertex. We prove that the resulting graphs, which include the Folkman graph, have the following curious property: every Hamiltonian cycle (of which there are exponentially many) is complementary to another Hamiltonian cycle.
On the expansion of Hanoi graphs.
D. Eppstein,
D. Frishberg, and
W. Maxwell.
arXiv:2510.18010
Discrete Mathematics & Theoretical Computer Science 28 (2): 31:1–31:18, 2026, doi:10.46298/dmtcs.16770.
In a previous paper, "On the treewidth of Hanoi graphs", we showed that \(n\)-disc \(p\)-peg Hanoi graphs have treewidth within a polynomial factor of \(n^{p-1}\). Here we consider expansion instead, and prove that both it and the treewidth are \(\Theta(n^{p-1})\).
Layer-respecting linear graph layouts.
A. Chiu,
T. Depian,
D. Eppstein,
M. T. Goodrich,
and
S. Liu.
arXiv:2607.06968.
Proc. 38th Canadian Conference on Computational Geometry, 2026,
to appear.
We develop fixed-parameter tractable dynamic programming algorithms for constructing optimized arc diagram visualizations of graphs of bounded BFS width.
Tangent spheres and integer distances.
D. Eppstein.
arXiv:2606.18569.
Proc. 38th Canadian Conference on Computational Geometry, 2026,
to appear.
Whenever a system of spheres or hyperspheres in three or more dimensions has the property that it can be partitioned into two subsets with each sphere in one subset externally tangent to each sphere in the other subset, it must be the case that within each subset the spheres all have coplanar centers. We use this to prove a high-dimensional version of the Erdős–Anning theorem: in any Euclidean or hyperbolic space, any point set within which all distances are integers must be either finite or collinear.
Minimum-weight Steiner triangulation of convex polygons
requires interior Steiner points.
D. Eppstein and
Z. Hadizadeh.
arXiv:2606.25302.
Proc. 38th Canadian Conference on Computational Geometry, 2026,
to appear.
In "Approximating the minimum weight Steiner triangulation" I conjectured that the minimum weight Steiner triangulation of a convex polygon only needs its Steiner points to be on the boundary of the polygon. This would give the triangulation a tree-like structure that could potentially lead to an efficient dynamic programming algorithm for constructing it. Unfortunately, the conjecture is not true: we construct a counterexample.
Sudoku grids that require many clues.
D. Eppstein and
X. Zhang.
arXiv:2607.05728.
26th Japan Conference on Discrete and Computational Geometry, Graphs,
and Games, Tokyo, 2026, to appear.
We study the minimum number of clues needed in sudoku, for a solution matrix that maximizes this minimum number. We show that, for most \(n^2\times n^2\) sudoku puzzles, all but a logarithmic fraction of the squares must be clues, and we apply this to the worst-case complexity of solving these problems. We also show how to pack many independent Latin squares into a sudoku puzzle, and we use this construction to construct many \(9\times 9\) puzzles that require 18 clues and \(16\times 16\) puzzles that require 80 clues.